9 Bugs in My AI Pipeline: None Were the AI's Fault
I tested my autonomous content pipeline 6 times and found 9 bugs.
The model caused exactly zero of them.
Every single failure was in the harness: the environment around the model. This post walks through all 9 bugs, what caused them, and how I fixed them.
What I Built
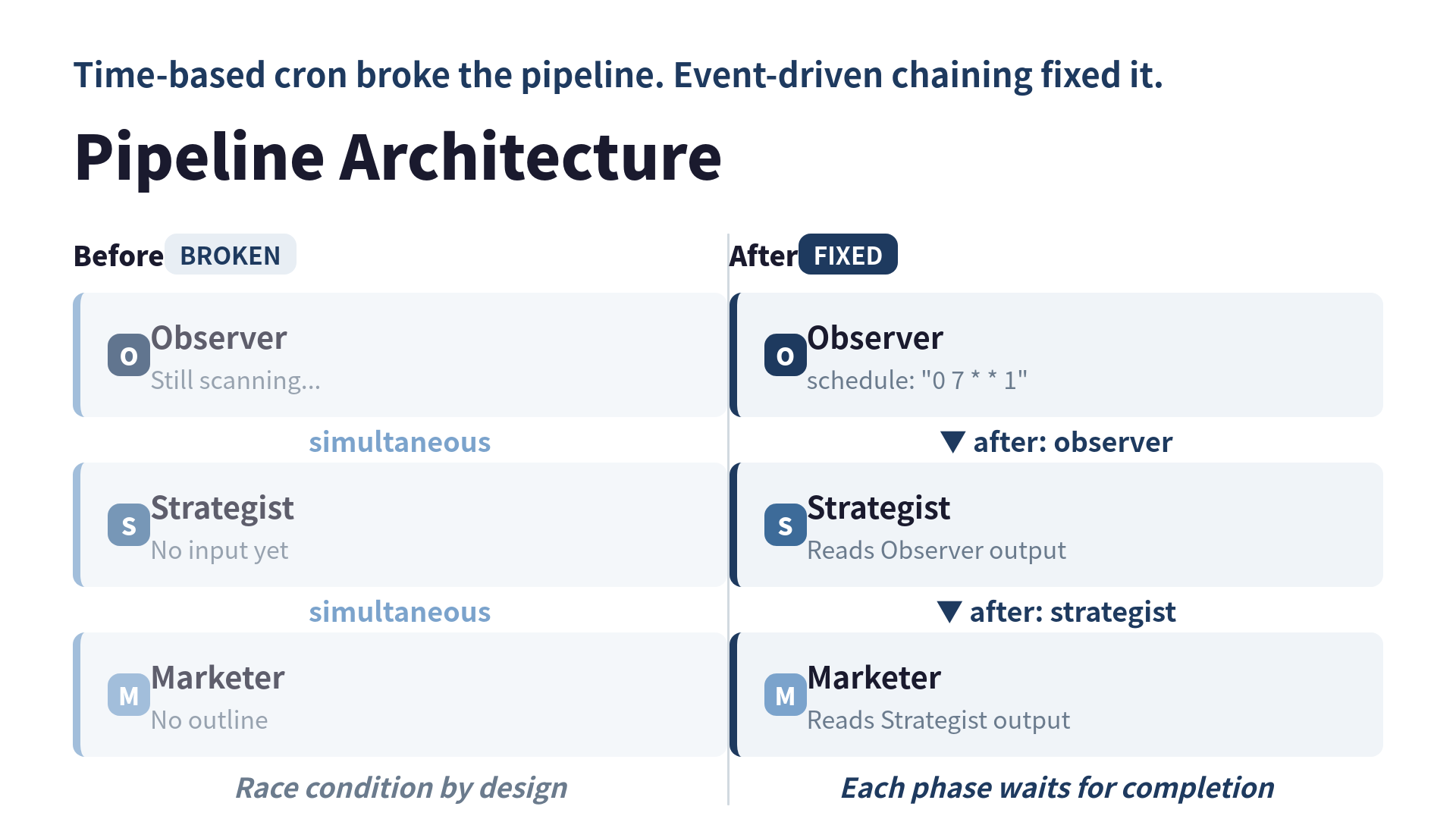
I built an autonomous content pipeline using Claude Code. Three independent AI sessions chain together in sequence:
- Observer: scans the landscape (trending topics, competitor articles, performance data)
- Strategist: picks the best topic, decides the angle, writes an outline
- Marketer: writes the full article, runs quality checks, schedules publication
Each phase is a separate Claude session. The Observer’s output becomes the Strategist’s input. The Strategist’s output becomes the Marketer’s input. No human in the loop: unless something fails quality checks.
I drew this architecture diagram on paper and felt like a genius. On paper, it was perfect.
# The target architecture
observer:
schedule: "0 7 * * 1" # Every Monday 7:00 AM
strategist:
after: observer # Starts when Observer completes
marketer:
after: strategist # Starts when Strategist completesSounds clean. Reality was messier.
The 9 Bugs
After 6 rounds of testing, I cataloged every failure. They fall into four categories.
Execution Control (2 bugs)
Bug #1: Parallel execution conflict
The first version used three separate cron jobs, all set to the same time. The Strategist hadn’t finished reading the Observer’s output when the Marketer started: with no input. Three people talking at the same time in a meeting. Nobody listening.
# Before: all fire at once
observer: "0 7 * * 1"
strategist: "0 7 * * 1"
marketer: "0 7 * * 1"The fix was switching from time-based scheduling to event-driven chaining with after dependencies.
Bug #2: Cron simultaneous fire
Even after staggering the times (7
, 7, 8), the Strategist sometimes took longer than 30 minutes. Race condition by design.The real fix was the same: event-driven chaining. Don’t schedule by clock: schedule by completion.
Data Integrity (3 bugs)
Bug #3: Topic duplication
Without an exclusion list, the pipeline kept selecting the same topic. The Observer saw “LLMO” trending and picked it every single time.
# Fix: inject exclusion list before topic selection
existing = list_existing_articles()
prompt = f"""
Select a topic. Do NOT pick any of these (already published):
{existing}
"""Bug #4: Calendar entry duplication
The pipeline registered calendar events without checking if one already existed. Run it twice, get two identical events.
Fix: delete matching entries before inserting.
Bug #5: Scheduling conflict with existing reservations
The auto-scheduler picked dates that already had articles scheduled. Two articles published on the same day, zero on the next.
# Fix: calculate available dates first
available = get_available_publish_dates(
start=today,
count=batch_size,
existing=get_scheduled_dates()
)Quality Assurance (2 bugs)
Bug #6: Self-reported quality checks
The AI was checking its own work: and always passing itself. “Is this article good?” “Yes, it’s excellent.” I had built the grading equivalent of a student marking their own homework. With a red pen. Giving themselves an A+.
Fix: run quality checks in a separate Claude session that has no memory of the writing session. Independent reviewer, not self-assessment.
Bug #7: Missing wit check
The quality pipeline checked for AI slop vocabulary but didn’t check for wit: the human touch that makes writing engaging rather than competent.
Fix: added a dedicated Phase 4 check requiring at least 2 instances of wit (self-deprecation, unexpected metaphors, deflation after grand statements).
Infrastructure (2 bugs)
Bug #8: Bash syntax error from angle brackets
The prompt template contained <devto_id> as a placeholder. Bash interpreted < as input redirection and silently corrupted the command.
# Before: bash interprets <devto_id> as redirect
echo "Update article <devto_id> to published"
# After: escape or quote
echo "Update article DEVTO_ID_PLACEHOLDER to published"Bug #9: at job duplication
The scheduler used at for timed publication but didn’t check for existing jobs with the same article ID. Re-running the pipeline queued duplicate publish commands.
Fix: delete matching at jobs before scheduling new ones.
The Pattern
None of these bugs involve the model generating bad text. The model was fine. What failed was everything around the model:
| Category | Count | Example |
|---|---|---|
| Execution control | 2 | Parallel sessions, race conditions |
| Data integrity | 3 | Duplicates, conflicts, missing exclusions |
| Quality assurance | 2 | Self-grading, missing checks |
| Infrastructure | 2 | Shell escaping, job management |

This maps cleanly to the Prompt → Context → Harness progression that’s emerging in the AI engineering space:
- Prompt Engineering: optimizing what you say to the model
- Context Engineering: optimizing everything you send to the model (RAG, tools, memory)
- Harness Engineering: optimizing the environment the model operates in
All 9 bugs were harness bugs. Y Combinator’s data backs this up: 40% of AI agent projects fail, and the common thread isn’t model quality. It’s harness quality.
The Fix: Event-Driven Chaining
The single most impactful change was moving from time-based cron to event-driven dependencies.
# Final architecture
observer:
schedule: "0 7 * * 1"
strategist:
after: observer
marketer:
after: strategistEach phase writes its output to a known location. The next phase only starts when the previous one completes successfully. If any phase fails, the chain stops: no downstream corruption.
After implementing all 9 fixes, the 7th test run produced 5 articles in a single batch, automatically scheduled to non-conflicting dates, each independently quality-checked.
Takeaway
AI agent quality is determined outside the AI.
The model is the chef. The context is the ingredients. The harness is the kitchen.
If the kitchen is broken: wrong burners firing simultaneously, ingredients getting mixed up, no one tasting the food: it doesn’t matter how talented the chef is.
I spent 3 hours optimizing my prompts. I spent 0 minutes checking my kitchen. Turns out, I was bug #10.
Before you optimize your prompts, check your kitchen.
Want to go deeper?
This article shows one piece. The full system — five vendor interpretations, six building blocks, and the implementation patterns from AGENTS.md to Self-Evolving Agents — is in Harness Engineering — From Using AI to Controlling AI.
Was this article helpful?