The Cheap Model That Won: Why Context Beats Parameters
I spent months assuming bigger models meant better results. Then I ran an experiment that made me feel like I’d been tipping 200% at a restaurant where the food was worse.
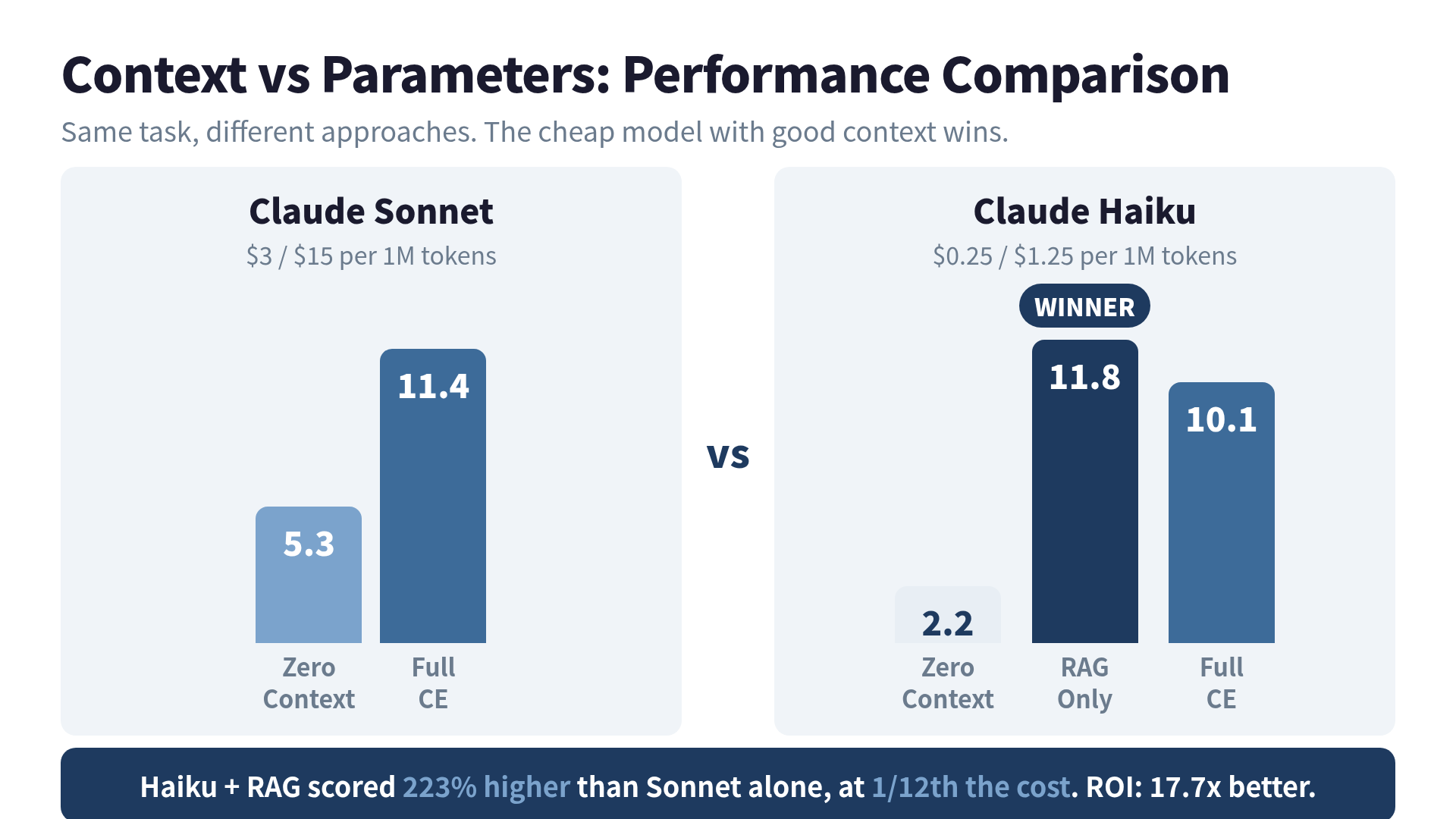
Claude Haiku with RAG scored 11.8. Claude Sonnet alone scored 5.3. The cheap model more than doubled Sonnet’s score. At one-twelfth the cost.
This post is about that experiment, why the results make sense, and what it means for how you should design AI systems.
The Experiment
I was building evaluation benchmarks for a context engineering book when I noticed something odd. My test suite measured how well different model configurations answered domain-specific questions. The scoring was simple: accuracy, completeness, and relevance on a 0-15 scale.
Here’s what the numbers looked like:
Claude Sonnet (2025 pricing: $3/$15 per 1M tokens)
- Zero context: 5.3
- Full context engineering: 11.4
- Improvement: 2.15x
Claude Haiku (2025 pricing: $0.25/$1.25 per 1M tokens)
- Zero context: 2.2
- RAG only: 11.8
- Full context engineering: 10.1
- RAG improvement: 5.36x
Read that again. Haiku with RAG didn’t just close the gap with Sonnet. It passed Sonnet. By a wide margin.
The Math That Should Change Your Architecture
Let me put this in terms your CFO will understand.
Assuming a 1
input/output ratio, the average cost per million tokens:- Haiku: ($0.25 + $1.25) / 2 = $0.75
- Sonnet: ($3.00 + $15.00) / 2 = $9.00
Sonnet costs 12x more. Even after adding RAG overhead (vector search, extra tokens for retrieved context), Haiku + RAG comes in around $1.13 per million tokens. That’s still 8x cheaper.
Now let’s calculate ROI (performance per dollar):
- Haiku + RAG: 11.8 / $1.13 = 10.44
- Sonnet zero context: 5.3 / $9.00 = 0.59
Haiku + RAG delivers 17.7x the ROI of naked Sonnet.
Here’s a real-world projection. Take a service running 1,000 queries per day with 2,000 input tokens and 500 output tokens per query:
| Configuration | Cost/Query | Monthly Cost |
|---|---|---|
| Sonnet (zero context) | $0.0135 | $405 |
| Haiku + RAG | $0.0024 | $71 |
| Savings | $334/month (82%) |
And the cheaper option performs better. This isn’t a tradeoff. It’s a free lunch. (The only free lunch I’ve found in engineering, and I’ve been looking for a while.)
This Isn’t Just an Anthropic Thing
The pattern holds across providers. OpenAI’s GPT-4.1 mini now matches or beats GPT-4o on many benchmarks, at 83% lower cost. Google’s smaller Gemini variants show similar patterns when paired with good retrieval.
The 2025 LaRA benchmark studied 2,326 test cases across eleven LLMs and found that the optimal choice between RAG and long-context depends on model capabilities, task type, and retrieval quality. But the consistent finding was this: a well-designed retrieval pipeline can close the gap between model tiers.
The industry is quietly converging on the same conclusion. There’s a reason most production SaaS products run on small models. It’s not just about saving money. It’s because small model + good context is genuinely competitive with large model + no context.
Why Context Beats Parameters
Think about it with a hiring analogy.
You have two candidates for a specialized role:
- Candidate A: Brilliant generalist from a top university. Knows a lot about everything. Expensive.
- Candidate B: Solid engineer from a state school. You hand them a complete briefing packet: the codebase, the architecture docs, the last three incident reports, the customer feedback.
Candidate B outperforms Candidate A. Not because B is smarter, but because B has the right information at the right time.
That’s what RAG does for a small model. It compensates for fewer parameters by providing exactly the knowledge needed for the task. The model doesn’t need to “know” everything. It just needs to know what’s relevant right now.
There’s a formula hiding here:
Performance = Model Capability x Context Quality
A large model with zero context is running on vibes. A small model with targeted context is running on data. Data wins.
When Big Models Still Win
I’d be lying if I said small models always win. They don’t. Here’s when you should reach for the bigger model:
Complex reasoning chains. Tasks requiring 5+ logical steps where each step builds on the previous one. Larger models hold more in working memory.
Novel creative synthesis. When you need the model to connect ideas that don’t appear together in your retrieval corpus. You can’t RAG your way to genuine insight.
Safety-critical applications. Healthcare, legal, financial decisions where the cost of a wrong answer dwarfs the cost of the API call.
Low-volume, high-stakes queries. If you’re making 10 queries a day and each one matters, the cost difference is negligible. Use the best model.
Here’s my decision heuristic:
- Start with the smallest model that can follow your instructions
- Add context (RAG, few-shot examples, structured prompts)
- Measure performance against your actual success criteria
- Only upgrade the model if context alone can’t get you there
Most teams skip steps 2 and 3. They jump straight to “use the biggest model” and wonder why their AI budget looks like a phone number.
The 2026 Pricing Reality
Model pricing keeps shifting. As of April 2026, Anthropic’s lineup looks like this:
| Model | Input | Output | Relative Cost |
|---|---|---|---|
| Haiku 4.5 | $1.00 | $5.00 | 1x |
| Sonnet 4.6 | $3.00 | $15.00 | 3x |
| Opus 4.6 | $5.00 | $25.00 | 5x |
Even though Haiku 4.5 costs more than the Haiku 3 I used in my experiment, the ratio still holds. The cheapest model is 3-5x less expensive than its bigger siblings. And the gap between models has actually narrowed in capability, making the “small model + context” strategy even more attractive.
On the OpenAI side, GPT-4.1 mini and nano continue the trend. Nano scores 80.1% on MMLU (higher than GPT-4o mini), handles 1M token context, and costs a fraction of GPT-4o. The era of “big model or bust” is over.
What This Means for Your Architecture
If you’re designing an AI system today, here’s the practical takeaway:
Invest in context, not model size. Every dollar spent on better retrieval, cleaner data, and smarter prompt construction returns more than the same dollar spent on a bigger model.
Benchmark on your actual task. Generic benchmarks are marketing materials. Your task is specific. Your data is specific. Measure what matters to you.
Run the migration math. If you’re on a large model today, calculate what it would cost to move to a small model + RAG. The 82% cost reduction in my example isn’t unusual.
Build the pipeline first. RAG infrastructure, embedding pipelines, and prompt templates are reusable across model upgrades. The context layer is an asset. The model is a commodity.
I started this project thinking context engineering was about making good models better. I was wrong. Context engineering is about making any model good enough. The model is the chef. The context is the recipe, the ingredients, and the kitchen. A decent chef with a great kitchen beats a celebrity chef standing in an empty room.
Before you upgrade your model, upgrade your context. Your budget (and your benchmarks) will thank you.
Want to go deeper?
The complete Context Engineering system — 5 strategies, RAG benchmarks (4.6× quality lift), MCP server design, Agentic RAG implementation — is in Turning LLMs from Liars into Experts: Context Engineering in Practice.
Was this article helpful?