One Question, Five AI Search Engines, Five Different Answers
I asked five AI search engines the same question: “What’s the best CI/CD tool for a small team?” Google AI Overviews recommended GitHub Actions. ChatGPT went with GitLab CI. Perplexity cited a 2026 benchmark from a blog I’d never heard of. Gemini pulled in a YouTube tutorial. Claude said it depends on your stack and asked me three follow-up questions.
Same question. Five different answers. Five different sources. I sat there staring at my screen like someone who just learned that five different weather apps can’t agree on whether it’s raining.
This isn’t a bug. It’s architecture. Each AI search engine queries a different index, applies different ranking logic, and cites different sources. If you’re creating technical content and want AI to reference your work, you need to understand what each platform is actually looking at.
The Five Architectures
Here’s what’s going on under the hood. Each platform has its own relationship with the web.
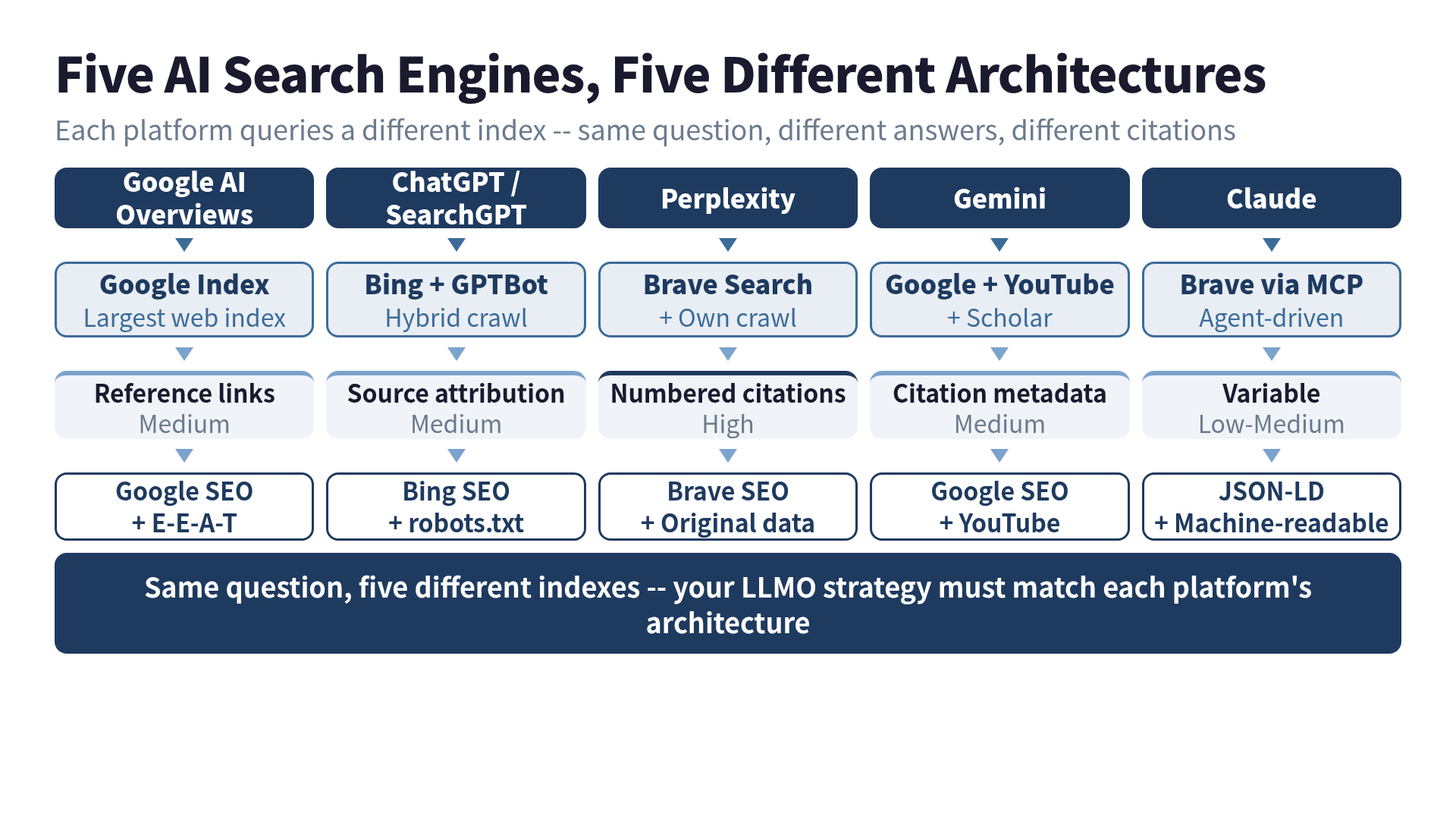
Google AI Overviews: The Incumbent
Google AI Overviews generates AI answers directly in search results. The key fact: it runs on the Google search index. The same index that powers traditional search results.
This means conventional SEO transfers directly to AI Overviews. If you rank on page one for a query, you’re already in the candidate pool for AI-generated answers.
The numbers have moved fast. In early 2025, AI Overviews appeared on about 13% of queries. By early 2026, that number climbed to roughly 48-60% of all U.S. queries, depending on who’s measuring. For education queries, the jump was from 18% to 83%. B2B tech went from 36% to 82%.
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) matters even more for AI Overviews than for traditional results. Google needs to trust content enough to put its name on an AI-generated summary. The “Experience” dimension is the one that separates human-written content from the flood of AI-generated noise: did you actually build, test, or use the thing you’re writing about?
What to do: If your Google SEO is solid, you’re already halfway there. Add structured snippets (concise answers near the top of your posts), strengthen author credentials, and show first-hand experience. The investment compounds across both traditional and AI results.
ChatGPT + Search: The Hybrid
ChatGPT’s search runs on a Bing index + GPTBot crawl hybrid. SearchGPT, which launched as a standalone product, is now fully integrated into ChatGPT. As of February 2026, ChatGPT captures 60.7% of all AI search traffic — the largest share by a wide margin.
But here’s the twist: ChatGPT only activates its search feature on 34.5% of queries. The rest are answered from training data alone. So your content needs to exist in two places: the live web (for search-enabled queries) and the training corpus (for everything else).
The ranking logic is a two-headed system:
- Bing side: Domain authority, backlinks, keyword relevance, click-through rates. Standard search engine signals.
- ChatGPT side: Training data quality, contextual understanding, conversational fit. Whether your content reads like a natural answer to a question.
The Apple Intelligence angle makes this even more significant. As of iOS 18.2, Siri can hand off questions to ChatGPT. At WWDC 2026 (June 8), Apple is expected to announce an even deeper Siri overhaul with iOS 27 that opens the door to multiple AI services — ChatGPT, Claude, Gemini. If Siri becomes a daily search interface for a billion iPhone users, the distribution channel changes everything.
What to do: Don’t sleep on Bing SEO. Check your robots.txt — make sure GPTBot isn’t blocked. Write content that answers questions conversationally, not just keyword-optimized landing pages.
Perplexity: The Transparent One
Perplexity is the platform where you can actually see whether you’re being cited. Every answer includes numbered source citations. Click a number, visit the source. This makes Perplexity the most measurable platform for LLMO.
Under the hood, Perplexity queries the Brave Search index plus its own crawl data. The citation transparency creates a real traffic loop: users see the citation, click through, visit your site. While other AI platforms create “zero-click” experiences (the user reads the answer and leaves), Perplexity regularly sends traffic to sources.
Content characteristics that get cited on Perplexity:
- Authoritative domains — official docs, established publications, peer-reviewed work
- Structured answers — Q&A format, numbered lists, step-by-step procedures
- Fresh content — explicit dates, regular updates
- Hard data — numbers, benchmarks, measurements
- Original research — data nobody else has
Perplexity’s 2026 product moves are worth watching. Deep Research now runs on Claude Opus 4.6. Model Council lets users run one query through three models simultaneously. Perplexity Computer ($200/month) is an autonomous agent using 19 different models. And Comet, their Chromium-based browser, ships with built-in AI on every page. Each of these products is another surface where your content might get cited.
What to do: Optimize for Brave Search. Publish original data. Use explicit timestamps. Structure content so individual sections can be extracted as standalone answers.
Gemini: The Google Multimodal Play
Gemini sits on Google’s full stack: Google Search grounding, YouTube, Google Scholar. The multimodal angle is what sets it apart.
A tutorial you wrote as a blog post? Gemini might prefer the YouTube video covering the same topic, because it can process both. A technical paper on Google Scholar carries academic authority that gets weighted in answers. Your code repository, your conference talk recording, your documentation site — Gemini can cross-reference all of them.
Google Search grounding is the shared base. The same signals that power AI Overviews also power Gemini’s answers. But Gemini adds layers: YouTube transcripts, Scholar citations, image understanding.
What to do: Google SEO is your primary lever again. But think beyond text. Technical YouTube content, published papers, and image-rich documentation all feed Gemini’s multimodal understanding. If you have a YouTube channel, its content directly influences your visibility in Gemini.
Claude: The Agent
Claude works differently from the other four. There’s no built-in web search by default. Instead, Claude uses MCP (Model Context Protocol) to connect to external data sources — Brave Search, GitHub, databases, file systems. Search is an intentional action, not an automatic feature.
In my setup, I have an AI agent (Iris) that searches like a researcher: generating multiple queries, fetching pages, cross-referencing results, and synthesizing. This “active exploration” pattern — multiple searches, deep reading, structured synthesis — is fundamentally different from the single-query model of the other platforms.
Claude’s MCP architecture also means the search source is configurable. Brave Search is the default for web queries, but developers can wire up any data source. Your API documentation, your npm package README, your structured data endpoints — all of these become searchable through MCP.
What to do: Optimize for Brave Search (MCP default). Make your content machine-readable: JSON-LD, clean API docs, well-structured READMEs. Claude’s agent-mode users are developers who value programmatic access to information.
The LLMO Matrix: What Works Where
Here’s the punchline. Different platforms, different levers.
| Strategy | AI Overviews | ChatGPT | Perplexity | Gemini | Claude |
|---|---|---|---|---|---|
| Google SEO | High | Medium | Low | High | Low |
| Bing SEO | Low | High | Low | Low | Low |
| Brave Search | Low | Low | High | Low | High |
| Structured data (JSON-LD) | Medium | Medium | Medium | Medium | High |
| E-E-A-T signals | High | Medium | Medium | High | Medium |
| YouTube content | Low | Low | Low | High | Low |
| llms.txt | Medium | Medium | Medium | Medium | Medium |
| robots.txt (AI crawlers) | High | High | Medium | High | Medium |
If you’re staring at this thinking “I can’t optimize for five different things,” you’re right. Nobody should try.
The Universal Playbook
Here’s what works everywhere, regardless of platform:
1. Write things only you can write. Original benchmarks, real-world measurements, first-hand implementation stories. Every AI platform weights primary sources higher than summaries of summaries. This is E-E-A-T’s “Experience” dimension, and it’s the one humans still own.
2. Structure your content for extraction. Headings, lists, tables, code blocks. AI platforms need to pull specific answers from your content. A 3,000-word essay with no subheadings is invisible to extraction algorithms. A well-structured post with clear sections is a citation candidate for every platform.
3. Keep it fresh. Date your content. Update it. Every platform penalizes stale information. I update my top-performing posts quarterly, even if it’s just adding a note like “Verified still accurate as of May 2026.”
4. Don’t block the bots. Check your robots.txt. GPTBot, Google-Extended, PerplexityBot, ClaudeBot, Brave’s crawler — each has its own user agent. Blocking any of them is opting out of that platform’s AI citations.
5. Add structured data. schema.org markup via JSON-LD helps Google AI Overviews (direct ranking factor), Brave’s LLM Context API (preferential extraction), and anything else that parses your page programmatically.
For a more systematic framework that ties these platform-specific strategies together, I’ve been building the LLMO Framework — it maps which tactics matter for which platforms and how to prioritize them.
The Zero-Click Reality
Here’s the uncomfortable truth: according to Bain & Company research, 80% of users resolve 40% of their queries without clicking anything. AI answers are making this worse (or better, depending on your perspective).
But “zero click” doesn’t mean “zero value.” When an AI cites your work, that’s a brand impression — even if nobody clicks through. In B2B, being the source that AI recommends carries serious weight. “Perplexity recommends this tool” and “ChatGPT cited this benchmark” are becoming the new social proof.
I track my own AI citations monthly. The traffic is small. The conversion rate on that traffic is 3x my organic average. People who arrive via AI search have already done their research — the AI did it for them. They’re ready to act.
My weather-app confusion from the beginning of this post? Turns out it’s a feature. Five different architectures mean five different chances to get cited. Your blog post that Google ignores might be exactly what Perplexity picks up. The YouTube video Perplexity can’t see is right in Gemini’s wheelhouse.
You don’t need to win on all five platforms. You need to understand which ones your audience actually uses, and build for those. The architecture decides what gets cited. Now you know the architecture.
Want to go deeper?
For the full LLMO playbook — llms.txt patterns, JSON-LD examples, citation-rate KPIs, and ChatGPT/Perplexity/Brave comparison — see LLMO Practical Guide: Why ChatGPT Ignores Your Website.
Was this article helpful?