llms.txt: The File That Decides Whether AI Can Find Your Site
I spent two weeks optimizing my site’s SEO. Meta tags, structured data, Open Graph images — the whole ritual. Then I asked ChatGPT about my own blog and got silence. Not wrong information. Not outdated information. Nothing.
My site was invisible to AI.
Turns out, I’d been decorating a house with no front door.
The Problem: AI Can’t Read Your Site the Way Google Does
Google’s crawler is a patient librarian. It reads your sitemap, follows every link, indexes every page, and comes back next week to check for updates. It’s had 25 years to get good at this.
AI crawlers are more like an intern on their first day. They show up, get overwhelmed by your navigation menus and cookie banners and JavaScript bundles, and leave with a vague impression that your site exists. Maybe.
The core issue: LLMs have a context window. They can’t ingest your entire site. They need someone to hand them a cheat sheet — “here’s what this site is about, and here are the pages that matter.”
That cheat sheet is llms.txt.
What llms.txt Actually Is
Jeremy Howard (the fast.ai founder — you’ve probably used his course materials) proposed llms.txt in 2024 as a Markdown file you place at your site’s root: yoursite.com/llms.txt.
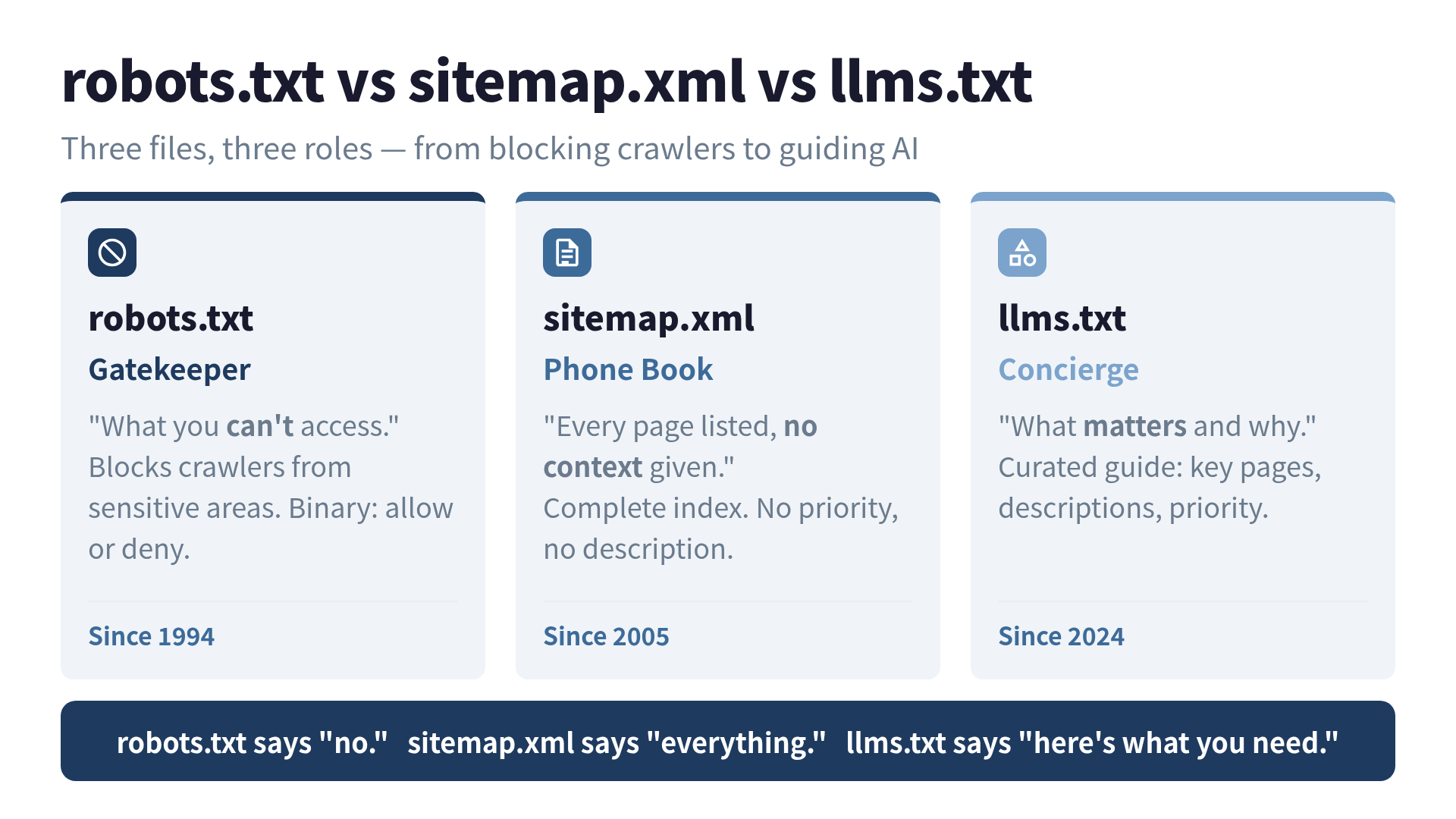
Think of it this way:
- robots.txt is a bouncer. “You can’t go in there.”
- sitemap.xml is a phone book. Every page listed, no context given.
- llms.txt is a concierge. “Welcome. Here’s who we are, here’s what matters, and here’s where to find it.”
The format is dead simple — it’s just Markdown:
# Your Site Name
> One-to-two sentence description of what this site does.
## Docs
- [Page Title](https://yoursite.com/page.html.md): Brief description
- [Another Page](https://yoursite.com/other.html.md): Brief description
## Optional
- [Less Critical Page](https://yoursite.com/extra.html.md): For context if neededThe ## Optional section is clever: it tells the LLM “skip this if your context window is tight.” Self-aware documentation.
Who’s Already Doing This
When I first heard about llms.txt, I assumed it was one of those standards that gets proposed, debated on Hacker News, and quietly forgotten. I was wrong. The adoption list reads like a YC demo day roster.
Stripe has three separate llms.txt files across two domains, plus every docs page available as .md. They also added an instructions section — because when you have 15 years of API surface area and deprecated payment primitives, you need to tell AI “please stop recommending Charges, use PaymentIntents.” Smart.
Cloudflare went with progressive disclosure: a root llms.txt that links to 130 per-product llms.txt files. Each one indexes that product’s docs. If an agent is building a Worker, it only needs to fetch the Workers section. No one reads the entire encyclopedia to fix a faucet.
Vercel keeps a slim index plus a llms-full.txt for bulk ingestion — reportedly 400,000 words. That’s four novels. About Next.js.
Other adopters include Anthropic, Cursor, Mintlify, and a growing list tracked on llms-txt-hub on GitHub.
The Honest Truth About Impact
I’ll be straight with you: the evidence for direct traffic impact is thin.
Google’s John Mueller has said “no AI service has confirmed they use llms.txt.” A study of 9 sites found 8 showed no measurable traffic change after implementation. The file has no official standardization body behind it — no W3C stamp, no IETF RFC.
So why am I writing about it?
Because the cost-benefit ratio is absurd. Implementation takes 15 minutes. There is literally zero downside — it doesn’t affect your existing SEO, doesn’t break anything, doesn’t require a deploy pipeline change. And the upside scenario is that AI search keeps growing (it will) and this becomes the standard way to communicate with it (it might).
I’ve made worse bets. Like that time I spent a weekend learning Google Wave.
How to Build Your llms.txt
Here’s the file I wrote for a technical blog. Steal it.
# Ken Imoto — Engineering Blog
> Software engineer writing about AI agents, harness engineering,
> and search optimization. Articles in English and Japanese.
## Featured Articles
- [9 Bugs in My AI Pipeline](/blog/9-bugs-in-my-ai-pipeline.html.md): All 9 bugs were in the harness, not the model
- [llms.txt Guide](/blog/llms-txt-ai-find-your-site.html.md): How to make your site visible to AI search
## Topics
- [AI Agent Design](/tags/ai-agent.html.md): Building autonomous agents with Claude Code
- [LLMO](/tags/llmo.html.md): AI search optimization techniques
## Optional
- [About](/about.html.md): Background and contact informationThe Design Decisions That Matter
1. Keep it under 10KB. The whole point is to fit in a context window. If your llms.txt is longer than your actual content, you’ve missed the assignment.
2. Use descriptive link text. Not “API Reference” but “Payments API: Charges and PaymentIntents.” LLMs parse the link text to decide whether to follow the URL.
3. The .html.md convention. Jeremy Howard proposed that appending .md to any URL should return a clean Markdown version of that page — no nav, no ads, no JavaScript. If you can set this up on your server, do it. If not, llms.txt still works with regular URLs.
4. Curate aggressively. Your sitemap has 500 pages. Your llms.txt should have 10-20. The value is in the filtering, not the listing.
The Three-Layer Strategy
llms.txt doesn’t replace robots.txt and structured data — it complements them. Think of it as three layers of communication with AI:
| Layer | File | Message |
|---|---|---|
| Access Control | robots.txt | ”What you’re allowed to crawl” |
| Navigation | llms.txt | ”What you should pay attention to” |
| Semantics | JSON-LD | ”What this content means” |

Most sites have layer 1 (robots.txt has been around since 1994 — it’s older than some of the engineers reading this). Fewer have layer 3 (structured data). Almost nobody has layer 2 yet. That’s your opening.
robots.txt: Don’t Block What You Want AI to Find
A quick detour on a mistake I see constantly: blocking AI crawlers in robots.txt while wondering why AI search doesn’t mention your site.
GPTBot and ClaudeBot requests now account for roughly 20% of Googlebot’s volume. These crawlers serve two purposes — training data collection (long-term) and RAG retrieval (immediate). If you block them entirely, you disappear from AI-powered answers. Period.
The smart play for most sites:
User-agent: GPTBot
Allow: /blog/
Allow: /docs/
Disallow: /admin/
Disallow: /internal/
User-agent: ClaudeBot
Allow: /blog/
Allow: /docs/
Disallow: /admin/
Disallow: /internal/Block your admin panels and internal tools. Allow everything you want the world to see. This isn’t complicated — but Perplexity’s CTO Denis Yarats noted that many sites over-block AI crawlers and then complain about low AI visibility. You can’t lock the door and complain nobody visits.
What Happens Next
llms.txt is at an inflection point. January 2026 saw Anthropic, Cursor, and Mintlify officially confirm they read it. OpenAI and Perplexity reportedly analyze it without formal announcement.
Two possible futures:
- It becomes the standard. W3C or IETF formalizes it. Every CMS adds a “Generate llms.txt” button. Early adopters get a head start.
- It gets absorbed. The principles get baked into robots.txt or a new protocol. The skills you build now (curating content for AI, thinking about machine readability) transfer directly.
Both outcomes reward action. Neither rewards waiting.
I added my llms.txt in 15 minutes. The next morning, I asked Claude about my blog, and it referenced an article I’d published two days earlier.
Correlation isn’t causation, and a sample size of one is a terrible experiment. But the smile on my face was real. Sometimes that’s enough to ship it.
References
- llms.txt specification — The original proposal by Jeremy Howard
- llms-txt-hub — Directory of sites implementing llms.txt
- Stripe’s llms.txt analysis — How Stripe uses instructions sections
- Mintlify’s real-world examples — Implementation patterns from top tech companies
Want to go deeper?
Want to ship LLMO in 30 minutes? LLMO Quickstart distills the core into 8 chapters with copy-pasteable templates.
Was this article helpful?