AIエージェントは月いくらかかるのか -- API・サブスク・ローカルの損益分岐点
AIエージェントの選定記事を10本読んで、「精度」「拡張性」「エコシステム」の比較表を眺めた。よくわかった。ただ、一番知りたいことが書いていない。
月いくらかかるのか。
技術選定で最初にやるべきことは、アーキテクチャ図を描くことでも、ベンチマークを読むことでもない。上長に「月額いくら?」と聞かれたときに即答できる数字を持っておくことです。私はこれを怠って、プロトタイプが完成してから見積もりを出し、「これ月5万かかるの?」という一言でプロジェクトが3週間止まった経験があります。
2026年5月時点の料金体系で、AIエージェントのコストを3つの類型に整理しました。
コスト構造の3類型
AIエージェントのコストは、LLMをどう使うかによって3つのパターンに分かれます。

類型1: API従量課金
LLMプロバイダのAPIキーを使い、トークン消費量に応じて課金される方式です。
2026年5月時点の主要モデル料金:
| モデル | 入力 | 出力 | 特徴 |
|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $25/MTok | 最高精度、1Mコンテキスト |
| Claude Sonnet 4.6 | $3/MTok | $15/MTok | コスパのバランス型 |
| GPT-4o | $2.50/MTok | $10/MTok | OpenAI主力 |
| Claude Haiku 4.5 | $0.25/MTok | $1.25/MTok | 高速・低コスト |
| GPT-4o mini | $0.15/MTok | $0.60/MTok | 最安クラス |
注意: Claude Opus 4.7は同じ$5/$25の価格ですが、新しいトークナイザーが同じ入力に対して最大35%多くトークンを生成します。1リクエストあたりの実効コストはOpus 4.6より高くなる場合があります。
エージェントはチャットボットと違い、トークン消費が桁違いに多い。1つのタスクを達成するために、計画→実行→観察→修正のループを何周も回し、そのたびにコンテキストが積み上がります。
実測例を出します。中規模リポジトリ(ファイル数300)のリファクタリングをClaude Sonnet 4.6のAPI経由で依頼した場合、1セッションで50万-100万トークン消費。金額にして$4.50-$9.00(約700-1,400円)。1日に複数セッション回すと月額は3-5万円に到達します。
電気代が月5,000円の家庭で、AIエージェントのAPI費が月30,000円。家賃の次に高い固定費がAIになる日が来るとは思いませんでした。
向いているケース: 使用頻度が低い(月数回)、タスクごとにモデルを切り替えたい、コストの上限を細かく管理したい
類型2: サブスクリプション
月額固定で、追加のAPI費用が発生しない方式です。
| プラン | 月額 | 含まれるもの |
|---|---|---|
| Claude Pro | $20 | Claude基本利用(制限あり) |
| Claude Max 5x | $100 | Proの5倍の利用枠 + Claude Code |
| Claude Max 20x | $200 | Proの20倍の利用枠 + Claude Code |
| ChatGPT Plus | $20 | GPT-4o基本利用 |
| OpenAI Codex | ~$100-200 | 開発者向け(利用量で変動) |
2026年4月4日、Anthropicはサードパーティツールからのサブスクリプション利用を制限しました。OpenClaw、Aider等のサードパーティツールからClaude Maxの枠を使う方法は公式には禁止です。Claude CodeはAnthropic公式ツールなので引き続きサブスクリプション内で利用できます。
slaude(Slack経由プロキシ)やMeridian(Claude Max→OpenCode/Aider連携)といった非公式ツールは存在しますが、利用規約に違反するリスクがあります。「壁の穴を見つけたからといって、そこを通っていいとは限らない」という話です。
向いているケース: 毎日エージェントを使う、月間トークン消費が多い(40万トークン+)、公式ツールだけで完結できる
類型3: ローカルLLM
Ollamaなどを使い、自前のGPU(またはCPU)でLLMを動かす方式です。API費用ゼロ。代わりにハードウェアと電気代がかかります。
2026年5月時点の推奨構成:
| モデルサイズ | 推奨VRAM | 推奨GPU | 推論速度目安 |
|---|---|---|---|
| 7-8B | 6GB+ | RTX 3060/4060 | 30-50 tok/s |
| 14B | 10GB+ | RTX 3080/4070 Ti | 20-35 tok/s |
| 32B | 20GB+ | RTX 4090/A5000 | 10-20 tok/s |
| 70B+ | 40GB+ | A100/H100 | 量子化必須 |
RTX 5090が2026年1月30日に発売されました。MSRP $1,999(約30万円)ですが、DRAMの供給不足で実売価格は$3,000-$5,000(45-75万円)まで高騰しています。スペックは32GB GDDR7、帯域1,792GB/s、TGP 575W。RTX 4090の約27-35%の性能向上ですが、電力消費も450W→575Wに増加。1日8時間稼働なら月額電気代は約5,500-7,000円の増分になります。
実用的なコーディング用ローカルモデルはDevstral-24B(Mistral)とQwen3-Coder:32B(Alibaba)。日本語対応ではLlama-3-ELYZA-JP-8Bがあります。
コスト計算:
- RTX 4090(約30万円、450W): 月額電気代 約4,000-5,000円
- RTX 5090(実売約50万円、575W): 月額電気代 約5,500-7,000円
- GPU本体の減価償却を月割りすると: RTX 4090で月約8,300円(3年)、RTX 5090で月約13,900円(3年)
向いているケース: 機密データを扱う、インターネット接続なしで動かしたい、長期的にコストを抑えたい、ゲーミングPCが余っている
損益分岐点を計算する
月間のトークン消費量に応じて、最安の類型が変わります。Claude Sonnet 4.6の料金($3/$15)で計算します。
- 月40万トークン以下: API従量課金が最安。月額$1-2(150-300円)程度
- 月40万-200万トークン: サブスクリプション($100/月)が有利。同じ使い方をAPIでやると$5-30相当
- 月200万トークン以上: ローカルLLMが最安(GPU環境がある場合)。APIでは$30+
ただし、ローカルLLMはClaude Sonnet 4.6やGPT-4oと比較して推論品質が落ちます。Devstral-24BやQwen3-Coderは日常的なコーディングタスクなら実用的ですが、複雑なアーキテクチャ設計やバグの根本原因分析ではフロンティアモデルに差をつけられます。
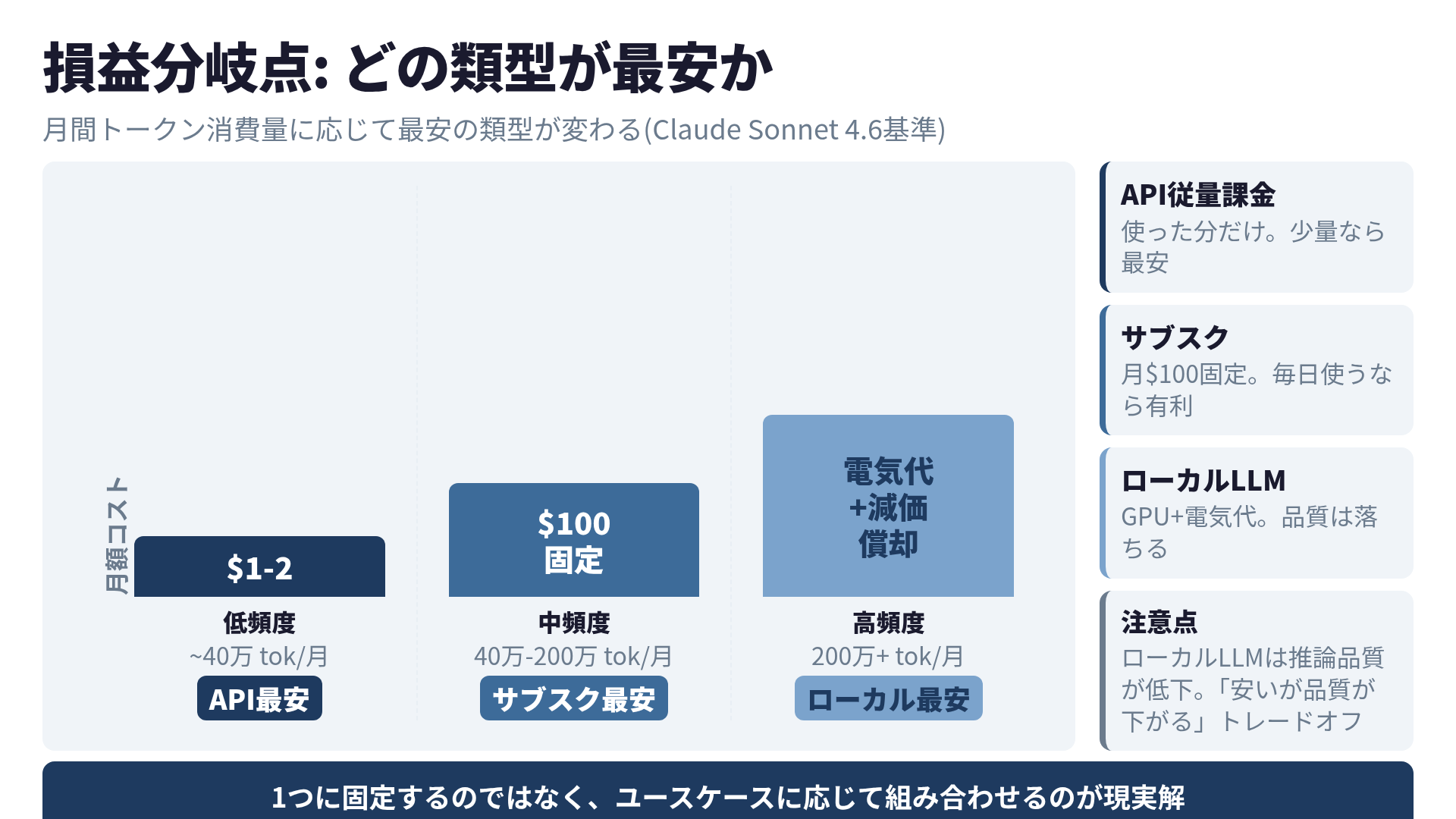
「安いが品質が下がる」。このトレードオフを許容できるかが判断のポイントです。コードレビューで「このリファクタ、なんか微妙だな」と思う頻度が増えたら、そのモデルの限界に到達しています。
私のハイブリッド戦略
1つの類型に固定するのは、1つの工具で家を建てようとするようなものです。
実用的なのは組み合わせる方法です。私は現在こう使い分けています:
- 日常のコーディング支援: Claude Code(Claude Max $100/月)。コード生成、レビュー、デバッグの日常タスク
- 大規模リファクタリング: Claude API(Opus 4.6)。精度が必要な場面だけ従量課金。月に2-3回で$10-20程度
- 機密データの処理: Ollama + Devstral-24B。クライアントのデータが外部に出ない
- 定型タスクの自動化: n8n + ローカルモデル。毎日動くバッチ処理にAPI費用をかけない
月額の内訳:
- Claude Max: $100(固定)
- API従量課金: $10-20(変動)
- ローカル電気代: 約5,000円(固定)
- 合計: 約20,000-22,000円/月
サブスク100ドルだけで全部やろうとしていた頃より、実は安くなっています。大規模タスクをMaxの枠内で無理やり回すと、レート制限に引っかかって待ち時間が発生し、その間に手動で作業する羽目になる。待ち時間の人件費を考えたら、必要な場面でAPIを使ったほうが安い。
コスト管理の実践
予算アラート
API従量課金を使う場合、予算の上限設定は必須です。Anthropic ConsoleでもOpenAI Dashboardでも月額上限を設定できます。私は月$50に設定しています。超えたことはまだない。超えたら「なぜ超えたか」を分析して、ローカルに逃がすべきタスクがないか見直します。
トークン消費の可視化
Claude Codeを使っているなら、セッション終了時にトークン消費量が表示されます。これを1週間記録すると、自分の消費パターンが見えてきます。「月曜は重い作業が多くてトークン消費が2倍」みたいな傾向が見つかれば、月曜だけAPIに切り替えるという判断もできます。
2026年後半に向けて
コスト構造は3-6ヶ月で変わります。注目しているポイント:
- Anthropicの料金改定: 2026年4月のサードパーティ制限に続く動きがあるか
- RTX 5090の価格安定: DRAMの供給が改善すればMSRP付近まで下がる可能性
- ローカルモデルの品質向上: Devstral-24Bの後継、Meta Llama 4のコーディング性能
- WWDC 2026(6月8日): AppleがSiriを複数のAIサービス(ChatGPT、Claude、Gemini)に開放する予定。iOSからのAIエージェント利用が加速すれば、サブスクリプションモデルの競争が変わる
料金表を読むのは面白くない作業です。でも「月いくら?」に答えられる人が、チームでAIエージェントの導入を推進できる人です。技術選定は、コストの話ができて初めて完了します。
さらに深掘りしたい方へ
本記事はその一面に過ぎません。OpenAI・Anthropic・LangChain・Martin Fowler・学術の5つの解釈を1冊に統合した体系書 ハーネス・エンジニアリング — AIを”使う”から”操る”へ で、ハーネスとは何か、どう設計し、どう運用するかを19章で解説しています。
この記事は役に立ちましたか?