
The Practical Knowledge Graph Guide
Structure Your Data, Sharpen Your AI
Why RAG alone won't make your AI smart — GraphRAG, Neo4j, and Property Graphs explained with working code, not abstractions
30+ technical books across 4 languages · Sold on Kindle in 6 countries · From a year of real production use
📖 Read for free
Read three full chapters right here before you buy. Liked it? Continue on Kindle.
01 Preface
Preface
“We have plenty of data, but we can’t see how it connects.”
This is a problem engineers face every day. Codebase dependencies, links between internal documents, shifts in user sentiment: all of these exist as isolated data points, yet few organizations have managed to structure and use those relationships effectively.
Knowledge graphs are the technology that makes these connections explicit. Since Google introduced one into its search engine in 2012, knowledge graphs have been adopted across enterprise, academic research, and developer tooling. And from 2024 onward, their value has surged again thanks to the combination with LLMs (Large Language Models).
This book brings together the “why,” “what,” and “how” of knowledge graphs in a single volume.
Why This Book, Why Now
In February 2024, Microsoft Research published GraphRAG. An LLM automatically builds a knowledge graph, then uses it as a retrieval backbone. The moment this technique appeared, it was clear that the era of hand-crafting KGs was over.
Around the same time, MCP gained traction, and tools that convert codebases into graphs (GitNexus, among others) started shipping one after another. GraphRAG, code KGs, and personal KGs — three waves hitting at once make this the right time to put knowledge graph technology into one book.
That said, the tools and APIs covered here are in a fast-moving space. Specific versions and pricing reflect the time of writing (April 2026); always check each tool’s official documentation for the latest information.
How This Book Is Organized
Part 1: Foundations covers the core concepts of knowledge graphs, how to choose between RDF and property graphs, and a step-by-step build with Neo4j.
Part 2: GraphRAG explains the GraphRAG architecture published by Microsoft Research and how to deploy it in an enterprise setting. It is an evidence-based approach to curbing the “plausible lies” that LLMs produce.
Part 3: Code Analysis introduces the latest tools for converting codebases into knowledge graphs using Tree-sitter AST and MCP. These techniques can cut AI code review token consumption by up to 49x.
Part 4: Emotion Reasoning covers emotion reasoning during dialogue using Emotion Commonsense Knowledge Graphs (ECoK), ATOMIC, and COMET — where psychology and computer science intersect.
Part 5: Organizational Knowledge and Personal KGs presents enterprise case studies from LinkedIn and Meta, along with personal knowledge management through Obsidian integration.
Who This Book Is For
- Engineers and data architects interested in knowledge graphs
- Team leads evaluating GraphRAG adoption
- Developers looking to make AI code review more efficient
- Knowledge managers who want to structure tacit organizational knowledge
My hope is that “thinking in graphs” as a mental framework will bring a fresh perspective to your work.
Continue this chapter on Kindle →02 Chapter 1: What Is a Knowledge Graph?
Chapter 1: What Is a Knowledge Graph?


Nodes, Edges, and Triples
The essence of a knowledge graph is representing knowledge through relationships.
The simplest unit is the triple: a three-part structure of Subject, Predicate, and Object that expresses a single fact.
(Neo4j) --[is_a]--> (GraphDatabase)
(GraphRAG) --[developed_by]--> (MicrosoftResearch)
(Python) --[used_in]--> (code-review-graph)A collection of these triples forms a knowledge graph. Nodes (vertices) represent entities; edges represent relationships.
How It Differs from Relational Databases
SQL databases join tables with JOIN operations. In a knowledge graph, edges are baked into the data structure from the start.
| Aspect | Relational DB | Knowledge Graph |
|---|---|---|
| Data model | Tables (rows and columns) | Nodes and edges |
| Expressing relationships | Foreign keys + JOIN | Edges (direct connections) |
| Schema | Must be defined upfront | Flexible (schema-optional) |
| Traversal depth | Slows proportionally with JOINs | Fast regardless of hop count |
| Best-fit question | ”Get A’s data" | "How are A and B connected?” |
For relationships three or more hops deep, a graph DB dominates an RDB. A query like “friends of friends of friends” requires three JOINs in an RDB, but in a graph DB you just walk the nodes. Writing a four-level JOIN in an RDB is like asking someone at a bar to introduce you to “my friend’s ex-girlfriend’s coworker’s boss.” By the third hop, nobody remembers who’s who.
 The structural difference between an RDB that crosses tables via JOINs and a knowledge graph that traverses nodes directly
The structural difference between an RDB that crosses tables via JOINs and a knowledge graph that traverses nodes directly
How It Differs from Vector Databases
With the spread of RAG (Retrieval-Augmented Generation), many readers are already familiar with vector databases. Vector DBs and knowledge graphs are also fundamentally different technologies.
| Aspect | Relational DB | Vector DB | Knowledge Graph |
|---|---|---|---|
| Data structure | Tables (rows and columns) | High-dimensional vectors (embeddings) | Nodes and edges |
| Best-fit question | ”Get data where ID=123" | "Find things similar to X" | "How are X and Y connected?” |
| Search method | WHERE clause + JOIN | Cosine similarity / ANN | Graph traversal (hops) |
| Weakness | Slow for deep relationship traversal | Cannot reason about “connections” | Cannot do similarity search |
Vector DBs excel at finding “conceptually similar documents,” but they cannot answer “What paths exist between A and B?” or “If I change A, what gets affected?”
Conversely, knowledge graphs specialize in relationship traversal and struggle with the fuzzy “sort-of similar” style of similarity search.
 RDB, Vector DB, and Knowledge Graph each excel at different kinds of questions. GraphRAG combines vector search with graph search
RDB, Vector DB, and Knowledge Graph each excel at different kinds of questions. GraphRAG combines vector search with graph search
Vector search and graph search are not competing technologies — they are complementary. In practice, GraphRAG (Chapter 5) combines these two approaches, enabling answers to cross-document questions that traditional RAG could not handle.
Components of a Knowledge Graph
A knowledge graph is made up of the following elements.
Entities (Nodes)
These represent “things” in the real world: people, organizations, concepts, files, functions — anything goes. Each node can carry a label (type) and properties (attributes).
(:Tool {name: "GitNexus", stars: 24800, language: "TypeScript"})
(:Paper {title: "GraphRAG", year: 2024, venue: "Microsoft Research"})Relations (Edges)
These represent the relationship between two nodes. Edges have a direction and a type; in the property graph model, edges can also carry attributes.
(GitNexus)-[:USES {since: "v1.0"}]->(TreeSitter)
(GraphRAG)-[:IMPROVES {metric: "comprehensiveness"}]->(BaselineRAG)Ontology
This is the “blueprint” of a knowledge graph. It defines what node types and edge types exist and what constraints govern them. Ontology design determines the quality of the entire knowledge graph.
The Cypher Query Language
Neo4j is the most widely used graph database (covered in detail in Chapters 3 and 4). Cypher, the query language used by Neo4j, lets you describe graph patterns intuitively.
// Get all tools that GitNexus depends on
MATCH (g:Tool {name: "GitNexus"})-[:DEPENDS_ON]->(dep)
RETURN dep.name, dep.category
// Explore related nodes within 2 hops
MATCH path = (start:Concept {name: "GraphRAG"})-[*1..2]-(related)
RETURN path
// Find the most connected nodes (hubs)
MATCH (n)-[r]-()
RETURN n.name, COUNT(r) AS connections
ORDER BY connections DESC
LIMIT 10Even engineers accustomed to SQL can write graph patterns intuitively using Cypher’s ASCII-art-like syntax.
Note: “Walking the nodes” is the key concept that runs through this entire book. Code dependencies (Chapter 8), emotional causality (Chapter 11), organizational tacit knowledge (Chapter 13) — in every case, traversing relationships reveals connections that were previously invisible.
Summary
- A knowledge graph is a technology for structuring the relationships between pieces of knowledge
- The triple (Subject-Predicate-Object) is the basic unit
- Compared to RDBs, graph DBs are fundamentally better at relationship traversal
- Knowledge graphs consist of three components: entities, relations, and ontology
- Cypher lets you query graph patterns intuitively
With that, you have the foundational concepts of knowledge graphs. Keep triples, Cypher, and ontology in mind, and nothing in the chapters ahead will trip you up.
Continue this chapter on Kindle →03 Chapter 2: Why Knowledge Graphs Now?
Chapter 2: Why Knowledge Graphs Now?

The “Connection” Problem in the Age of Generative AI
In Chapter 1, we learned the basic structure of knowledge graphs — nodes, edges, and triples — and saw that they handle relationship traversal better than RDBs. So why has this technology, with over 60 years of history, attracted a surge of renewed attention since 2024?
The answer lies in the rise of generative AI. LLMs (Large Language Models) generate remarkably fluent text, but they have a fundamental weakness: they fabricate facts that aren’t in their training data while sounding perfectly confident. This is known as hallucination.
RAG (Retrieval-Augmented Generation) is an effective approach to this problem, but traditional RAG has its own limits. Vector search is good at retrieving “conceptually similar documents,” but it struggles with “connecting the dots.”
For example, answering “What do the technologies used in Project A and the root cause of the outage in Project B have in common?” requires cross-document understanding. This is where knowledge graphs come into play.
Note: Vector search and graph search are not in opposition — they are complementary. Most production systems use both. GraphRAG (Chapter 5) is the prime example of this combination.
Breaking Down Data Silos
Enterprise data is fragmented across departments and systems.
- Sales keeps data in the CRM
- Engineering keeps data in Jira and GitHub
- Finance keeps data in the ERP
Ask all three departments for “the full picture on that deal” and you get three different spreadsheets — each with slightly different numbers. If this sounds familiar, you are not alone.
Integrating these data sources into a knowledge graph lets you trace, end to end, “which developer’s commit relates to the bug this customer reported, and how did it affect revenue.”
Three Reasons Knowledge Graphs Are Back in the Spotlight
1. The Arrival of GraphRAG
In February 2024, Microsoft Research published GraphRAG: a method that uses LLMs to automatically generate a knowledge graph from text, then uses that graph as the knowledge source for RAG. It was shown to produce dramatically better answers for “questions about the dataset as a whole” — questions that traditional RAG simply could not handle.
2. LLM-Powered KG Construction
Building a knowledge graph used to require manual work by domain experts: entity extraction, relationship definition, ontology design. All of it took enormous amounts of time.
With LLMs, entity and relationship extraction from text has been automated. NTT Data’s validation achieved 73% accuracy in extracting corporate relationships from news articles. Not perfect, but orders of magnitude more efficient than building from scratch by hand.
3. Integration with Developer Tools
The spread of MCP (Model Context Protocol) has made it possible to integrate knowledge graphs directly into AI development tools. Tools like GitNexus, code-review-graph, and CodeGraphContext convert codebases into knowledge graphs and let you query them via MCP servers from Claude Code or Cursor.
Historical Background
The term “knowledge graph” became widely known through Google’s 2012 announcement. The information panel that appears on the right side of search results (the “333 m” answer when you search “How tall is Tokyo Tower?”) was powered by the Google Knowledge Graph.
But the concept itself is much older, stretching back to semantic networks in the 1960s.
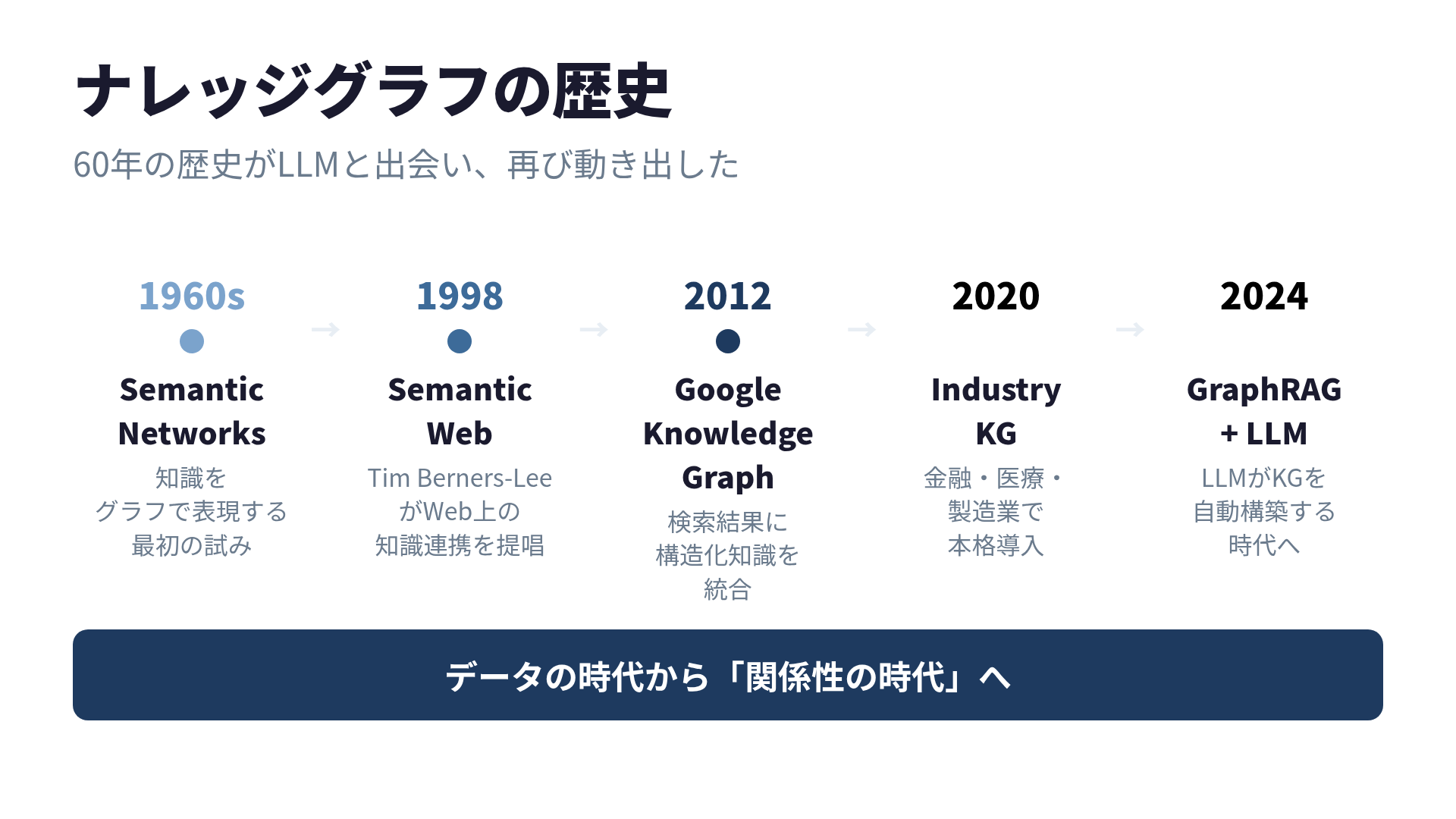 Sixty years of history met LLMs and started moving again
Sixty years of history met LLMs and started moving again
| Era | Milestone |
|---|---|
| 1960s | Research on semantic networks |
| 2001 | W3C publishes the RDF standard |
| 2012 | Google Knowledge Graph announced |
| 2020s | NTT Data applies KGs to contract risk assessment |
| 2024 | Microsoft Research publishes GraphRAG |
| 2025- | Code KG tools (GitNexus, etc.) proliferate |
A technology that matured over 60 years has gained its “missing piece” in LLMs and entered the practical deployment phase. That is where we are now.
No-Code / Low-Code Democratization
Platforms like Altair offer no-code tools for building and visualizing knowledge graphs. This lets data scientists and business analysts work with knowledge graphs without writing code.
Even more noteworthy is the maturation of managed services like Neo4j AuraDB and Amazon Neptune. Lower operational costs for graph databases mean the barrier to “just trying it” has dropped significantly. Work that required a dedicated graph DB engineer five years ago can now be started with a few clicks in a cloud console.
Summary
- Hallucination mitigation and data silo elimination are the forces behind the renewed interest in knowledge graphs
- GraphRAG breaks through the limits of traditional RAG (cross-document reasoning)
- LLM-powered KG construction has cut costs by orders of magnitude
- MCP integration embeds knowledge graphs directly into developer workflows
- No-code tools have opened the door to non-engineers
So, to ride this wave, there is a first decision you need to make: should the data model be RDF or a property graph?
Continue this chapter on Kindle →Overview
RAG alone won't make your AI smart. Relationships only emerge through structure — Knowledge Graph, GraphRAG, Neo4j, RDF, Property Graph, Tree-sitter, MCP, and Emotion AI. The practical guide to giving AI true reasoning through structured data.
What you will be able to do
- Choose between RDF, Property Graph, and GraphRAG for each use case
- Build a real production knowledge graph with Neo4j
- Convert codebases into knowledge graphs with Tree-sitter
- Design AI access to knowledge graphs through MCP
- Apply knowledge graphs to new domains like Emotion AI
Who is this book for
- [RAG Practitioner] Hit the ceiling with vector search alone
- [AI Agent Developer] Want to structure context relationships
- [Data Engineer] Need to operate Neo4j / Property Graph in production
- [Codebase Analyzer] Want to use Tree-sitter for AST work
- [Emotion AI / Psychology] Want to apply graphs to less-explored domains
Problems this book solves
- RAG implementation scatters info — AI can't synthesize answers
- Tried Neo4j but design guidance is unclear
- Hear about GraphRAG but don't understand how it differs from regular RAG
- Want to graph the codebase but tool choice is overwhelming
- Confused choosing between RDF and Property Graph
- Want to apply graphs to Emotion AI / psychology but few examples exist
Where this book stands
- Implementation-focused (concrete Neo4j / RDF / Tree-sitter examples)
- Cross-domain integration (GraphRAG + code analysis + Emotion AI in one book)
- Intermediate (graph DB basics assumed)
- For RAG graduates (the next step after vector search hits its limits)
Why this book
- One of the few books explaining GraphRAG at implementation level
- Clear guidance on RDF vs Property Graph trade-offs
- Open pipeline: code AST → knowledge graph via Tree-sitter
- MCP integration to make graphs queryable from AI
- Original lens: structuring approach for Emotion AI
How this differs from other AI books
| Compared to | This book's difference |
|---|---|
| Neo4j tutorials | Not Neo4j alone. Goes into GraphRAG, code analysis, and MCP integration. |
| RAG intro books | Focused on GraphRAG — what to do after vector search hits its limits. |
| Semantic Web / RDF books | Not academic-only. Practical RDF vs Property Graph trade-off guidance. |
Table of contents
- 01 Preface Free preview
- 1-1 Why This Book, Why Now
- 1-2 How This Book Is Organized
- 1-3 Who This Book Is For
- 02 Why Knowledge Graphs Now Free preview
- 2-1 Nodes, Edges, and Triples
- 2-2 How It Differs from Relational Databases
- 2-3 How It Differs from Vector Databases
- 2-4 Components of a Knowledge Graph
- 2-5 The Cypher Query Language
- 03 RDF vs Property Graph Free preview
- 3-1 The "Connection" Problem in the Age of Generative AI
- 3-2 Breaking Down Data Silos
- 3-3 Three Reasons Knowledge Graphs Are Back in the Spotlight
- 3-4 Historical Background
- 3-5 No-Code / Low-Code Democratization
- 04 Neo4j Fundamentals
- 05 Cypher / SPARQL Query Design
- 06 What is GraphRAG
- 07 GraphRAG Implementation Patterns
- 08 Codebase to Graph with Tree-sitter
- 09 MCP Integration
- 10 Knowledge Graph × LLM Design
- 11 Emotion AI Application
- 12 Enterprise Operations
- 13 Visualization and Debugging
- 14 Benchmarking and Evaluation
- 15 The Future
- 16 Afterword
Vector search hands AI knowledge, not relationships. “Alice reports to Bob, who runs project C” is a graph fact, not a vector fact.
This book is the field guide to giving AI that structured intelligence: Neo4j, RDF, Property Graphs, GraphRAG, Tree-sitter for code ASTs, MCP integration, and even Emotion AI. All turned into patterns you can ship.
“Data gets smart not as vectors, but as graphs.”
Related books



Read on Kindle
Included in Kindle Unlimited
Read on Kindle* This page contains Amazon Associates links. Purchases may earn the author a referral fee.