
ナレッジグラフ活用大全
構造化すれば、AIは賢くなる
ナレッジグラフ 活用大全 | GraphRAG・Neo4j・RDF・Property Graph・Emotion AI の実践書
Zenn累計32,000+ views · 4言語で30冊以上出版 · Kindle 6カ国で販売中
📖 無料で読める章
買う前に3章をその場で読めます。気に入ったらKindleで続きを。
01 はじめに
はじめに
「データはたくさんあるのに、つながりが見えない」
これは、エンジニアが日常的に直面する課題です。コードベースの依存関係、社内ドキュメントの関連性、ユーザーの感情変化。どれも個別のデータとしては存在しているのに、それらの 関係性 を構造化して活用できている組織は多くありません。
ナレッジグラフは、この「つながり」を明示的に表現する技術です。2012年にGoogleが検索エンジンに導入して以来、エンタープライズ、学術研究、開発ツールと幅広い領域で活用されてきました。そして2024年以降、LLM(大規模言語モデル)との組み合わせにより、その価値が再び急上昇しています。
本書は、ナレッジグラフの「なぜ」「なに」「どうやって」を一冊にまとめたものです。
なぜ今この本を出すのか
2024年2月、Microsoft ResearchがGraphRAGを発表しました。LLMがナレッジグラフを自動構築し、それを検索基盤として使う。この技術が出た瞬間、「手作業でKGを構築する時代は終わった」と確信しました。
同時期にMCPが普及し、コードベースをグラフに変換するツール(GitNexus等)が次々とリリースされました。GraphRAGとコードKGとパーソナルKG — 3つの波が同時に来ている今が、ナレッジグラフの技術を一冊にまとめる最適なタイミングです。
ただし、本書で紹介するツールやAPIは変化が速い領域です。具体的なバージョンや価格は執筆時点(2026年4月)の情報であり、最新の状況は各ツールの公式ドキュメントを確認してください。
本書の構成
第1部: 基礎編 では、ナレッジグラフの基本概念、RDFとプロパティグラフの選び方、Neo4jを使った構築ステップを解説します。
第2部: GraphRAG編 では、Microsoft Researchが発表したGraphRAGの仕組みと、企業での導入方法を解説します。LLMの「もっともらしい嘘」を抑制するための、エビデンスベースのアプローチです。
第3部: コード解析編 では、Tree-sitter ASTとMCPを使って、コードベースをナレッジグラフに変換する最新ツール群を紹介します。AIコードレビューのトークン消費を最大49倍削減する手法です。
第4部: 感情推論編 では、感情常識ナレッジグラフ(ECoK)やATOMIC/COMETを使った対話中の感情推論を解説します。心理学と計算機科学が交差する領域です。
第5部: 組織知・パーソナルKG編 では、LinkedInやMetaの企業事例、Obsidianとの統合によるパーソナルナレッジ管理を紹介します。
対象読者
- ナレッジグラフに興味があるエンジニア・データアーキテクト
- GraphRAGの導入を検討しているチームリーダー
- AIコードレビューの効率化を模索している開発者
- 組織の暗黙知を構造化したいナレッジマネージャー
「グラフで考える」という思考フレームワークが、あなたの仕事に新しい視点をもたらすことを願っています。
この続きはKindleで →02 第1章: ナレッジグラフとは何か
第1章: ナレッジグラフとは何か


ノード、エッジ、トリプル
ナレッジグラフの本質は、「知識を関係性で表現する」ことにあります。
最もシンプルな単位は トリプル です。主語(Subject)、述語(Predicate)、目的語(Object)の3つ組で、ひとつの事実を表現します。
(Neo4j) --[is_a]--> (GraphDatabase)
(GraphRAG) --[developed_by]--> (MicrosoftResearch)
(Python) --[used_in]--> (code-review-graph)これらのトリプルが集まったものがナレッジグラフです。ノード(頂点)は実体を、エッジ(辺)は関係を表します。
リレーショナルDBとの違い
SQLデータベースはテーブル間をJOINで結合しますが、ナレッジグラフではエッジが最初からデータ構造に組み込まれています。
| 観点 | リレーショナルDB | ナレッジグラフ |
|---|---|---|
| データモデル | テーブル(行と列) | ノードとエッジ |
| 関係の表現 | 外部キー + JOIN | エッジ(直接接続) |
| スキーマ | 事前定義が必要 | 柔軟(スキーマレスも可) |
| 探索の深さ | JOINの数に比例して遅くなる | ホップ数に依存せず高速 |
| 得意な問い | 「Aのデータを取得」 | 「AとBはどうつながっているか」 |
3ホップ以上の関係探索では、グラフDBがRDBを圧倒します。「友達の友達の友達」のようなクエリは、RDBでは3回のJOINが必要ですが、グラフDBではノードを辿るだけです。RDBで4段階のJOINを書くのは、居酒屋で「友達の元カノの同僚の上司」を紹介してもらうようなものです。途中で誰が誰だかわからなくなる。
 テーブルをJOINで横断するRDBと、ノードを直接辿るナレッジグラフの構造的な違い
テーブルをJOINで横断するRDBと、ノードを直接辿るナレッジグラフの構造的な違い
ベクトルDBとの違い
RAG(Retrieval-Augmented Generation)の普及で、ベクトルDBに馴染みのある読者も多いでしょう。ベクトルDBとナレッジグラフも、根本的に異なる技術です。
| 観点 | リレーショナルDB | ベクトルDB | ナレッジグラフ |
|---|---|---|---|
| データ構造 | テーブル(行と列) | 高次元ベクトル(埋め込み) | ノードとエッジ |
| 得意な問い | 「ID=123のデータを取得」 | 「Xに似たものを探す」 | 「XとYはどうつながるか」 |
| 検索方法 | WHERE句 + JOIN | コサイン類似度 / ANN | グラフ探索(ホップ) |
| 弱点 | 深い関係探索が遅い | 「つながり」の推論ができない | 類似検索ができない |
ベクトルDBは「概念的に近い文書」を見つけるのは得意ですが、「AとBの間にどんな経路があるか」「Aを変えたら何に影響するか」には答えられません。
逆に、ナレッジグラフは関係の探索に特化しており、「なんとなく似ている」という曖昧な類似検索は苦手です。
 RDB、ベクトルDB、ナレッジグラフはそれぞれ異なる「問い」に強い。GraphRAGはベクトル検索とグラフ検索を組み合わせる
RDB、ベクトルDB、ナレッジグラフはそれぞれ異なる「問い」に強い。GraphRAGはベクトル検索とグラフ検索を組み合わせる
ベクトル検索とグラフ検索は対立する技術ではなく 補完関係 です。実際にGraphRAG(第5章)はこの2つを組み合わせることで、従来のRAGでは回答できなかった文書横断的な質問に答えられるようになりました。
ナレッジグラフの構成要素
ナレッジグラフは以下の要素で構成されます。
エンティティ(ノード)
現実世界の「もの」を表します。人、組織、概念、ファイル、関数など、対象は何でも構いません。各ノードにはラベル(型)とプロパティ(属性)を持たせることができます。
(:Tool {name: "GitNexus", stars: 24800, language: "TypeScript"})
(:Paper {title: "GraphRAG", year: 2024, venue: "Microsoft Research"})リレーション(エッジ)
2つのノード間の関係を表します。エッジには方向と型があり、プロパティグラフモデルではエッジにも属性を持たせることができます。
(GitNexus)-[:USES {since: "v1.0"}]->(TreeSitter)
(GraphRAG)-[:IMPROVES {metric: "comprehensiveness"}]->(BaselineRAG)オントロジー
ナレッジグラフの「設計図」です。どのようなノード型やエッジ型が存在するか、それらの間にどのような制約があるかを定義します。オントロジーの設計がナレッジグラフの品質を左右します。
Cypherクエリ言語
Neo4jは最も広く使われているグラフデータベースです(第3章・第4章で詳しく扱います)。そのNeo4jで使われるCypherは、グラフパターンを直感的に記述できるクエリ言語です。
// GitNexusが依存しているツールをすべて取得
MATCH (g:Tool {name: "GitNexus"})-[:DEPENDS_ON]->(dep)
RETURN dep.name, dep.category
// 2ホップ以内の関連ノードを探索
MATCH path = (start:Concept {name: "GraphRAG"})-[*1..2]-(related)
RETURN path
// 最も接続数の多いノード(ハブ)を発見
MATCH (n)-[r]-()
RETURN n.name, COUNT(r) AS connections
ORDER BY connections DESC
LIMIT 10SQLに慣れたエンジニアでも、アスキーアートのような構文で直感的にグラフパターンを記述できます。
まとめ
- ナレッジグラフは「知識の関係性」を構造化する技術
- トリプル(主語-述語-目的語)が基本単位
- RDBと比較して、関係の探索が本質的に得意
- エンティティ、リレーション、オントロジーの3要素で構成
- Cypherで直感的にグラフパターンをクエリできる
ここまでで、ナレッジグラフの基礎概念は揃いました。トリプル、Cypher、オントロジーの3つを押さえておけば、以降の章で迷うことはありません。
この続きはKindleで →03 第2章: なぜ今ナレッジグラフなのか
第2章: なぜ今ナレッジグラフなのか

生成AI時代の「つながり」問題
第1章では、ナレッジグラフの基本構造 — ノード、エッジ、トリプル — を学びました。RDBより関係探索が得意だということもわかりました。では、60年以上の歴史を持つこの技術が、なぜ 2024年以降 に急速に再注目されているのでしょうか。
その背景には、生成AIの台頭があります。LLM(大規模言語モデル)は驚くほど流暢にテキストを生成しますが、根本的な弱点があります。 学習データにない事実を「もっともらしく」でっち上げる ことです。いわゆるハルシネーション(幻覚)です。
RAG(Retrieval-Augmented Generation)はこの問題に対する有効なアプローチですが、従来のRAGには限界がありました。ベクトル検索は「概念的に近い文書」を取得するのは得意ですが、「点と点をつなぐ」推論は苦手です。
例えば、「プロジェクトAで使われている技術と、プロジェクトBの障害原因に共通する要素は何か?」という質問には、複数の文書を横断的に理解する必要があります。ここでナレッジグラフが力を発揮します。
データサイロの解消
企業のデータは、部門ごと、システムごとに分断されています。
- 営業部はCRMにデータを持ち
- 技術部はJiraとGitHubにデータを持ち
- 経理部はERPにデータを持っている
3つの部門に「あの案件の全体像は?」と聞くと、3つの異なるExcelファイルが送られてくる。しかもどれも微妙に数字が違う。この状況に覚えがある人は多いはずです。
これらのデータソースをナレッジグラフで統合すると、「この顧客が報告したバグは、どの開発者のどのコミットに関連し、売上にどう影響したか」を一気通貫で辿ることができます。
ナレッジグラフが再注目される3つの理由
1. GraphRAGの登場
2024年2月、Microsoft ResearchがGraphRAGを発表しました。LLMを使ってテキストからナレッジグラフを自動生成し、それをRAGの知識源として活用する手法です。従来のRAGでは回答できなかった「データセット全体に関する質問」に対して、大幅に優れた回答を生成できることが実証されました。
2. LLMによるKG自動構築
以前は、ナレッジグラフの構築には専門家による手作業が必要でした。エンティティの抽出、関係の定義、オントロジーの設計。これらすべてに膨大な時間がかかっていました。
LLMの登場により、テキストからのエンティティ・関係抽出が自動化されました。NTTデータの実証では、ニュース記事からの企業関係抽出で73%の精度を達成しています。完璧ではありませんが、ゼロから手作業で構築するよりも圧倒的に効率的です。
3. 開発者ツールとの統合
MCP(Model Context Protocol)の普及により、ナレッジグラフをAI開発ツールに直接統合できるようになりました。GitNexus、code-review-graph、CodeGraphContextなどのツールは、コードベースをナレッジグラフに変換し、MCPサーバー経由でClaude CodeやCursorからクエリできます。
ナレッジグラフの歴史的背景
ナレッジグラフという言葉が広く知られるようになったのは、2012年のGoogleの発表です。検索結果の右側に表示される情報パネル(「東京タワーの高さは?」と検索したときに出る333mという回答)は、Google Knowledge Graphの成果でした。
しかし、概念自体はもっと古く、1960年代のセマンティックネットワークにまで遡ります。
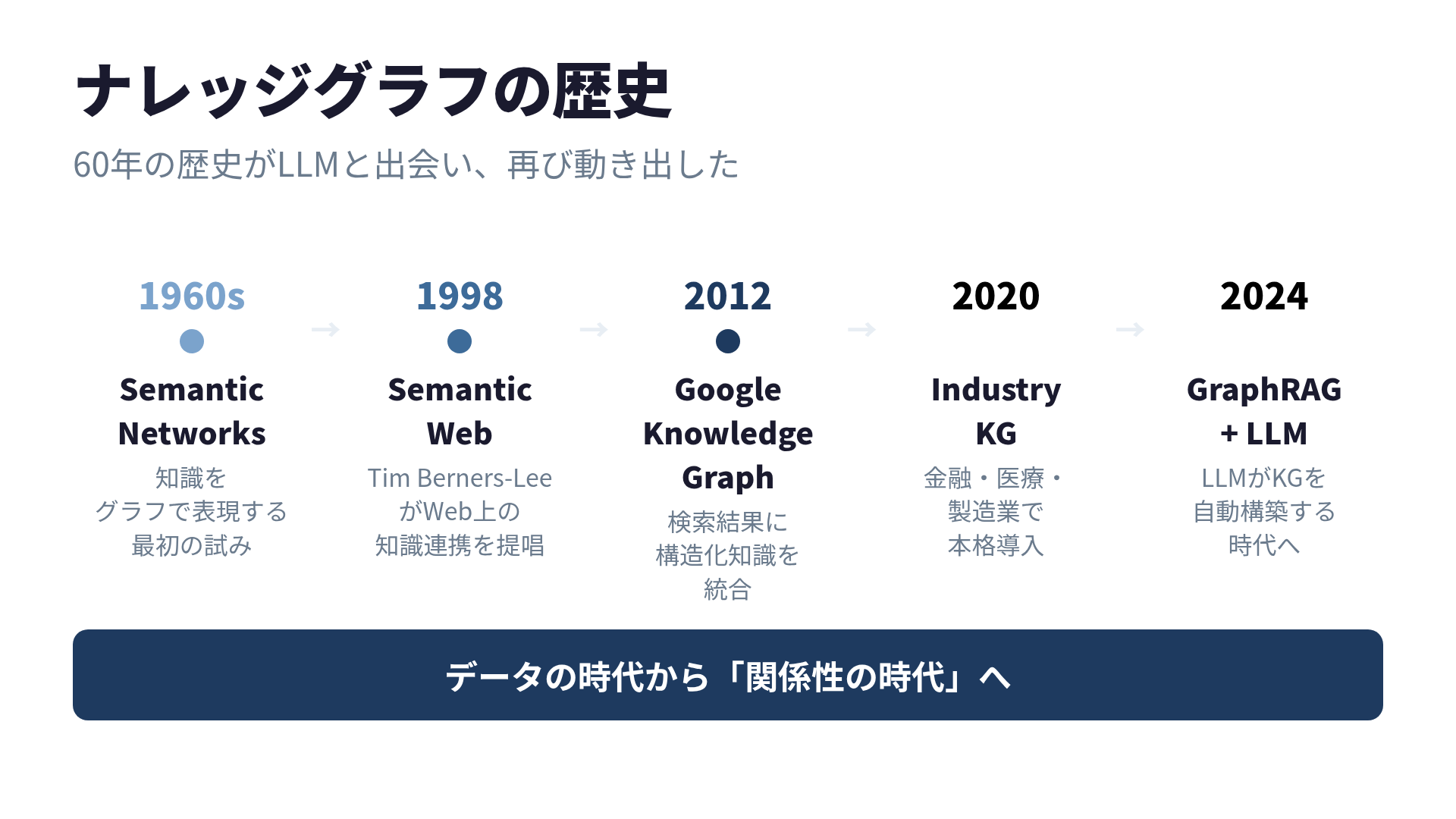 60年の歴史がLLMと出会い、再び動き出した
60年の歴史がLLMと出会い、再び動き出した
| 年代 | マイルストーン |
|---|---|
| 1960s | セマンティックネットワークの研究 |
| 2001 | W3CがRDF標準を策定 |
| 2012 | Google Knowledge Graph発表 |
| 2020s | NTTデータが契約リスク評価にKGを適用 |
| 2024 | Microsoft ResearchがGraphRAGを発表 |
| 2025- | コードKGツール(GitNexus等)が急増 |
60年かけて熟成された技術が、LLMという「最後のピース」を得て実用化のフェーズに入った。それが現在の状況です。
ノーコード/ローコードの民主化
Altair社のようなプラットフォームは、ノーコードでナレッジグラフを構築・可視化できるツールを提供しています。これにより、データサイエンティストやビジネスアナリストも、プログラミングなしでナレッジグラフを活用できるようになりました。
さらに注目すべきは、Neo4j AuraDBやAmazon Neptuneのようなマネージドサービスの成熟です。グラフDBの運用コストが下がり、「試してみる」ハードルが格段に低くなりました。5年前なら専任のグラフDBエンジニアが必要だった作業が、今はクラウドコンソールから数クリックで始められます。
まとめ
- ハルシネーション抑制とデータサイロ解消がナレッジグラフ再注目の背景
- GraphRAGが従来RAGの限界(文書横断的な推論)を突破
- LLMによるKG自動構築でコストが桁違いに低下
- MCP統合で開発者のワークフローに直接組み込み可能
- ノーコードツールの登場で非エンジニアにも門戸が開放
では、この波に乗るために最初に決めなければならない問いがあります。データモデルをRDFにするか、プロパティグラフにするか?
この続きはKindleで →本書の概要
RAG だけでは AI は賢くならない。構造化することで初めて関係性が見える — Knowledge Graph / GraphRAG / Neo4j / RDF / Property Graph / Tree-sitter / MCP / Emotion AI まで、AIに「賢さ」を与える構造化技術を体系化した実践ガイド。
この本でできるようになること
- RDF / Property Graph / GraphRAG の使い分けを判断できる
- Neo4j で実プロジェクトのナレッジグラフを構築できる
- Tree-sitter でコードベースをナレッジグラフ化できる
- MCP 経由で AI からナレッジグラフを参照する設計ができる
- Emotion AI のような新領域にもナレッジグラフを応用できる
対象読者
- 【RAG実装中】ベクトル検索だけで限界を感じている人
- 【AIエージェント開発者】文脈の関係性を構造化したい人
- 【データエンジニア】Neo4j / Property Graph を本格運用したい人
- 【コードベース解析中】Tree-sitter でAST活用したい人
- 【感情AI / 心理学応用】Emotion AI を構造化アプローチで実装したい人
この本で解決できる悩み
- RAG を実装したが、関連情報が散らばってAIが答えを統合できない
- Neo4j を使ってみたが、設計指針が分からず使いこなせない
- GraphRAG という言葉は聞くが、普通のRAGと何が違うのか不明
- コードベースをナレッジグラフ化したいが、ツール選定で迷う
- RDF と Property Graph のどちらを選ぶべきか判断できない
- Emotion AI / 心理学応用にグラフを使いたいが事例が少ない
この本の立ち位置
- 実装重視 (Neo4j / RDF / Tree-sitter の具体実装)
- 横断統合 (GraphRAG ・ コード解析 ・ Emotion AI を1冊で)
- 中級者向け (グラフDB の基礎は前提)
- RAG 卒業者向け (RAG だけでは行き詰まった人にとっての次のステップ)
なぜこの本か
- GraphRAG を実装レベルで日本語解説した数少ない書籍
- RDF と Property Graph の使い分けを明確に提示
- Tree-sitter でコードAST → ナレッジグラフ化のパイプラインを公開
- MCP との統合で「AIから参照可能なグラフ」を構築
- Emotion AI の構造化アプローチという独自視点
他のAI本との違い
| 比較対象 | 本書の違い |
|---|---|
| Neo4j 入門書 | Neo4j単体ではなく、GraphRAG・コード解析・MCP統合まで含めた実践書。 |
| RAG入門書 | ベクトル検索の限界を超えるGraphRAGに特化。RAGの卒業先として位置付け。 |
| セマンティックWeb / RDF書籍 | 学術的なRDFだけでなく、Property Graphとの実践的な使い分けを扱う。 |
目次
- 01 はじめに 無料公開
- 1-1 なぜ今この本を出すのか
- 1-2 本書の構成
- 1-3 対象読者
- 02 第1章: ナレッジグラフとは何か 無料公開
- 2-1 ノード、エッジ、トリプル
- 2-2 リレーショナルDBとの違い
- 2-3 ベクトルDBとの違い
- 2-4 ナレッジグラフの構成要素
- 2-5 Cypherクエリ言語
- 03 第2章: なぜ今ナレッジグラフなのか 無料公開
- 3-1 生成AI時代の「つながり」問題
- 3-2 データサイロの解消
- 3-3 ナレッジグラフが再注目される3つの理由
- 3-4 ナレッジグラフの歴史的背景
- 3-5 ノーコード/ローコードの民主化
- 04 第3章: RDF vs プロパティグラフ
- 05 第4章: 7ステップで構築するナレッジグラフ
- 06 第5章: GraphRAGの仕組み
- 07 第6章: エンタープライズGraphRAGの導入
- 08 第7章: LLM × KGの実践ユースケース
- 09 第8章: コードをグラフで理解する
- 10 第9章: コード解析KGツール比較
- 11 第10章: MCP統合とAIコードレビュー
- 12 第11章: 感情常識ナレッジグラフ
- 13 第12章: 対話における感情推論
- 14 第13章: 企業のナレッジグラフ活用
- 15 第14章: パーソナルナレッジグラフ
- 16 第15章: ナレッジグラフの未来
- 17 おわりに — 「グラフで考える」という武器 無料公開
ベクトル検索 (RAG) でAIに「知識」を与えても、関係性は見えません。「AさんはBさんの上司で、Cプロジェクトを担当している」という構造は、ベクトルではなくグラフで初めて表現できます。
本書は、その「構造化されたAI」を作るための実践書です。Neo4j / RDF / Property Graph の基礎から、GraphRAG の実装、Tree-sitter によるコードAST のグラフ化、MCP 統合、Emotion AI 応用まで、現場で使えるパターンを体系化しました。
「データはベクトルでなく、グラフで賢くなる。」
シリーズ・関連書籍


Kindleで購入する
Kindle Unlimited 対象
Kindleで読む (¥1,250)※ 本ページにはAmazonアソシエイトリンクが含まれます。クリック先での購入により著者に紹介料が入る場合があります。