
Why ChatGPT Ignores Your Website
The LLMO Practical Guide
Google SEO won't get you cited by ChatGPT — this is the playbook for being seen by AI search, with measurement included
30+ technical books across 4 languages · Sold on Kindle in 6 countries · From a year of real production use
📖 Read for free
Read three full chapters right here before you buy. Liked it? Continue on Kindle.
01 Introduction
Your website is being ignored by ChatGPT.
Even if you rank #1 on Google, your site doesn’t appear in AI-generated answers. Why?
Introduction
Background
One day, while reviewing the logs of my AI agent, I noticed something strange.
I was setting up an AI agent framework called OpenClaw. The configuration screen asked me to enter a “Brave Search API key.” Not a Google API key. Brave. The AI agent I’d been delegating my daily research to wasn’t using Google for web searches at all.
The search engine I’d been optimizing for and the search engine my AI actually used to retrieve information were completely different. This discovery inspired me to write this book.
As I dug deeper, I realized this wasn’t just about my agent. The primary battleground of search is shifting from Google’s “ten blue links” to AI’s “single answer.” And it’s becoming clear that traditional SEO alone can’t win on this new battlefield.
Purpose of This Book
This book is a practical guide to getting your content “discovered” by LLMs (Large Language Models).
I call this field LLMO (Large Language Model Optimization). If SEO is the art of optimizing for Google’s search algorithm, LLMO is the art of optimizing for AI’s information retrieval mechanisms.
At the core of this book is the Three Pathways Framework. There are only three ways information reaches an LLM:
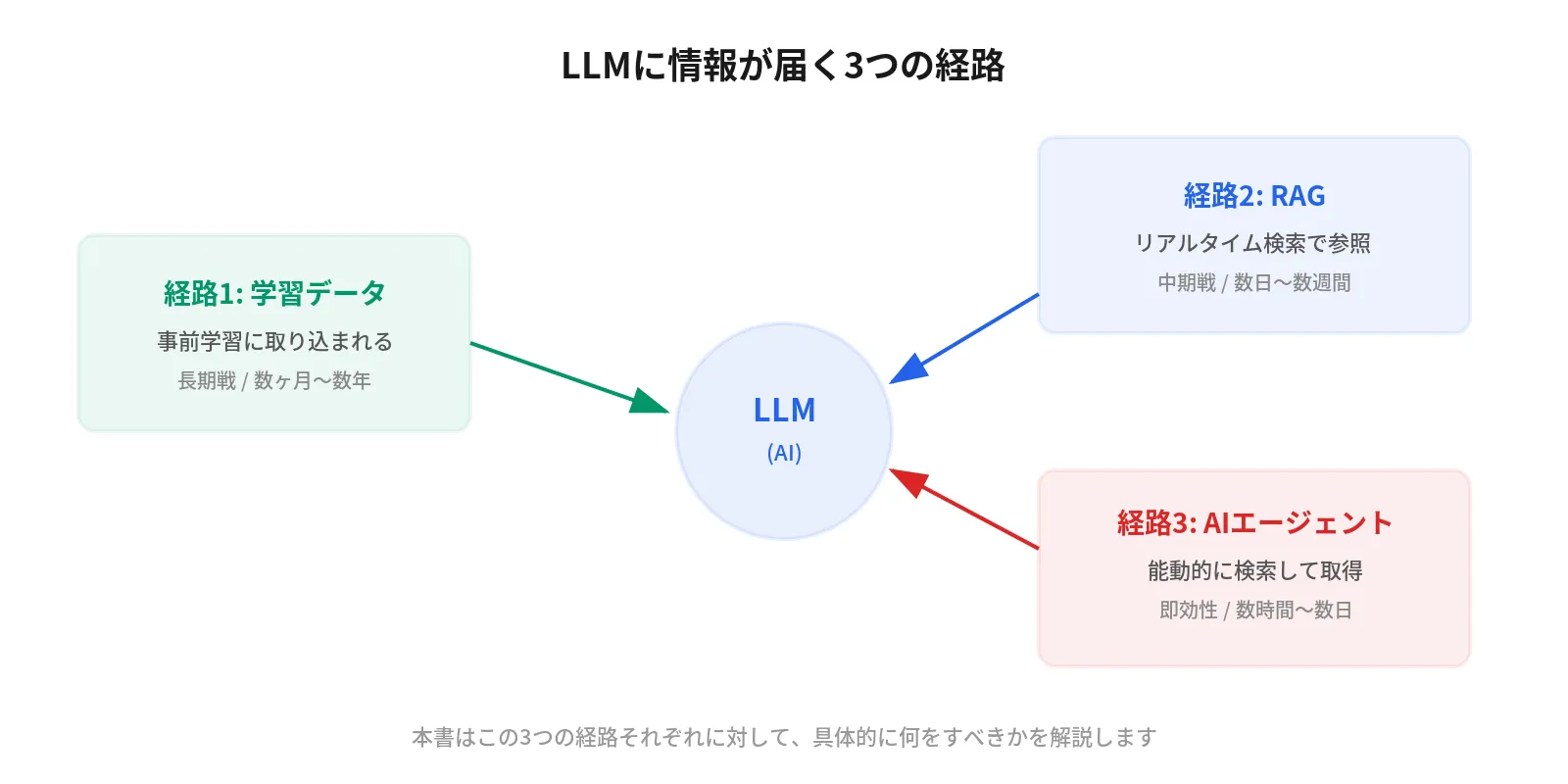
- Training Data: Incorporated during the model’s pre-training
- RAG (Retrieval-Augmented Generation): Referenced through real-time search
- AI Agent Search Behavior: Actively searched by CLI tools and agents
This book explains what specific actions to take for each of these three pathways.
Target Audience
- Engineers and marketers with basic SEO knowledge
- Product managers seeking to improve AI search visibility
- Technical professionals who want to understand how AI search works in ChatGPT, Perplexity, Claude, etc.
- Executives and directors looking to update their content strategy for the AI era
How to Read This Book
Reading cover to cover: Reading from Chapter 1 sequentially will deepen your understanding progressively: “Why LLMO is necessary” → “Understanding the mechanics” → “Implementation” → “Measurement and improvement.”
Starting with implementation: Begin with Chapter 7 (Structured Data) and Chapter 8 (llms.txt / robots.txt), then refer back to earlier chapters as needed for the most efficient approach.
For decision-makers: Read Chapter 1, Chapter 11 (Case Studies), and Chapter 12 (Future Outlook) first to get an overview of LLMO and gather material for investment decisions.
Technical Environment
The code examples in this book have been tested in the following environments:
- Python 3.10 or higher
- Node.js 18 or higher
- Claude Code, Gemini CLI, Codex CLI (latest versions)
Code examples generally work as-is, though some require initial setup such as obtaining API keys. See each chapter’s instructions for details.
Let’s explore the new optimization strategies for the AI search era together.
Continue this chapter on Kindle →02 The Day SEO Breaks
Chapter 1: The Day SEO Breaks
Your SEO efforts? AI isn’t watching.
What My AI Agent Taught Me
One day in 2026, I was reviewing the logs of my AI agent when I noticed something strange.
I use an AI agent framework called OpenClaw. I delegate day-to-day research and information gathering to a Claude-based (Anthropic’s LLM) agent. When I happened to check what this agent, “Iris,” was using to execute web searches, here’s what I found:
Brave Search API.
Not Google.
As a freelancer working on multiple projects, one of my engagements involved SEO (Search Engine Optimization). I’d been carefully structuring headings, optimizing meta descriptions, and designing internal links. All to rank higher on Google’s search results.
But my AI agent wasn’t looking at Google at all.
This discovery was a shock. The search engine I’d been optimizing for and the search engine my AI actually used to retrieve information were completely different things.
Further investigation revealed that this wasn’t unique to my agent. Anthropic’s Claude uses Brave Search as its search backend. Perplexity also uses Brave as one of its search sources. Many AI coding assistants are beginning to offer integration with the Brave Search API.
In other words, many of the AI tools that proliferated rapidly from 2024 to 2025 use Brave Search rather than Google when retrieving information.
When you ask a technical question using Gemini CLI, Reddit’s r/programming threads sometimes get cited as answer sources. With Claude in Chrome, the AI references information from X (formerly Twitter) timelines open in your browser to generate responses.
No matter which AI tool you examine, the information retrieval path doesn’t go through Google’s search results pages. The act of AI “searching for information” and the act of a human “Googling something” are now entirely separate phenomena.
Google’s 20-Year Reign
Let’s rewind a bit.
Google began to dominate the search market in the early 2000s. Its PageRank algorithm, which numerically scored web page importance based on the principle that “pages linked to by many quality sites are more important,” overwhelmed the directory-based search engines of the time and created a culture where “searching” meant “Googling.”
As of 2024, Google’s global search share stands at approximately 90%. Roughly 85% on desktop and about 95% on mobile. The remainder is split among Bing, Yahoo!, DuckDuckGo, and others.
For engineers and marketers working on the web, “search optimization” has effectively meant “Google optimization.” We’ve spent 20 years reacting to every Google algorithm update, adapting to Core Web Vitals, and crafting content with E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) in mind. This has been the common wisdom for two decades.
That premise is now beginning to crumble.
From “Ten Blue Links” to “One AI Answer”
Picture a Google search results page. Titles and snippets lined up as “ten blue links.” This has been the fundamental search experience. Users click links, visit individual sites, and synthesize information to form their own judgments.
However, since ChatGPT’s arrival, user information-seeking behavior has fundamentally changed.
“Ask ChatGPT.” “Look it up on Perplexity.” “Consult Gemini.” These behaviors are rapidly becoming mainstream, especially among technical professionals. Instead of browsing multiple sites, users ask AI a question and receive a single, synthesized answer.
The data backs up this shift:
- 27% of US users substitute AI chatbots for everyday searches (February 2025 survey)
- Gartner predicts a 25% decline in traditional search engine traffic by 2026
- The display of AI Overviews caused Google’s #1 ranking CTR (click-through rate) to drop by 34.5% (Ahrefs study, 300,000 keywords)
Meanwhile, AI-driven referral traffic has increased 357% year-over-year (SimilarWeb). This means the overall search traffic pie isn’t changing so much as the channel through which people find information is shifting dramatically.
The critical point here is that this change is irreversible.
Once users experience the convenience of getting an instant answer from AI, they won’t go back to “ten blue links.” It’s the same as how nobody went back to the abacus after calculators became widespread. This is especially true for efficiency-minded professions like engineering.
I’ve personally noticed a change in what I do first when a technical question arises. I used to search Google for Stack Overflow answers. Now I ask Claude Code or Gemini CLI directly. It’s faster, more accurate, and produces answers tailored to my context.
The Birth of LLMO: A New Field
A new optimization domain has emerged to address this change. That domain is LLMO: Large Language Model Optimization.
LLMO is the art of optimizing your content so that it gets referenced and cited in responses from large language models like ChatGPT, Claude, Gemini, and Perplexity.
While traditional SEO aimed to “rank higher on Google’s search results pages,” LLMO aims to “be cited as an information source within AI-generated answers.”
This distinction is fundamentally important for engineers.
In SEO, Google’s crawler indexes your site and its algorithm determines rankings. The optimization target is clear, and the feedback loop is relatively well-established (through Search Console, for example).
In LLMO, the situation is entirely different.
First, how an LLM “knows” your content is complex. There’s the pathway of being incorporated into pre-training data, the pathway of being searched in real-time through RAG (Retrieval-Augmented Generation), and the pathway where AI agents independently retrieve information. At least three pathways exist (Chapter 2 covers this in detail).
Second, there isn’t just one “search engine” to optimize for. ChatGPT uses Bing (potentially SearchGPT in the future), Claude uses Brave Search, and Gemini uses Google Search. Each platform references different search infrastructure.
Furthermore, AI responses are probabilistic. Even with the same question, the same sources won’t necessarily be cited every time. The response and its citations vary based on the temperature (randomness) parameter, query time, user location, model version, and other factors.
In short, LLMO is an optimization problem that is inherently more complex, uncertain, and multi-platform than SEO.
Terminology: LLMO / GEO / AIO / AEO
Let’s organize the terminology in this field. Since the industry hasn’t yet settled on a unified name, multiple terms coexist.
LLMO (Large Language Model Optimization)
Content optimization for being cited and referenced in LLM responses. This book primarily uses this term because it’s the most technically precise, with a clear target (LLMs).
GEO (Generative Engine Optimization)
Optimization for generative AI engines broadly. Defined in a paper published at KDD 2024 by a Princeton University research team. This is the standard term in academia, and it’s also gaining traction in overseas marketing circles.
However, in Japan, searching “GEO” returns results for a rental DVD chain called “GEO,” which creates a barrier to adoption of the term.
AIO (Artificial Intelligence Optimization)
A general term for content and site structure optimization for AI overall. Relatively common in Japan, but it’s also used as an abbreviation for “AI Overviews” (Google’s generative AI answer feature), creating contextual ambiguity.
AEO (Answer Engine Optimization)
Answer engine optimization. Aims to appear in “instant answers” from AI-powered search features like Google AI Overviews, Bing Copilot, and Perplexity. A slightly narrower concept than GEO, focused on “search engine AI answer features.”
The Three-Layer Model
The three-layer model proposed by Jasper’s blog is useful for understanding the relationship between these terms:
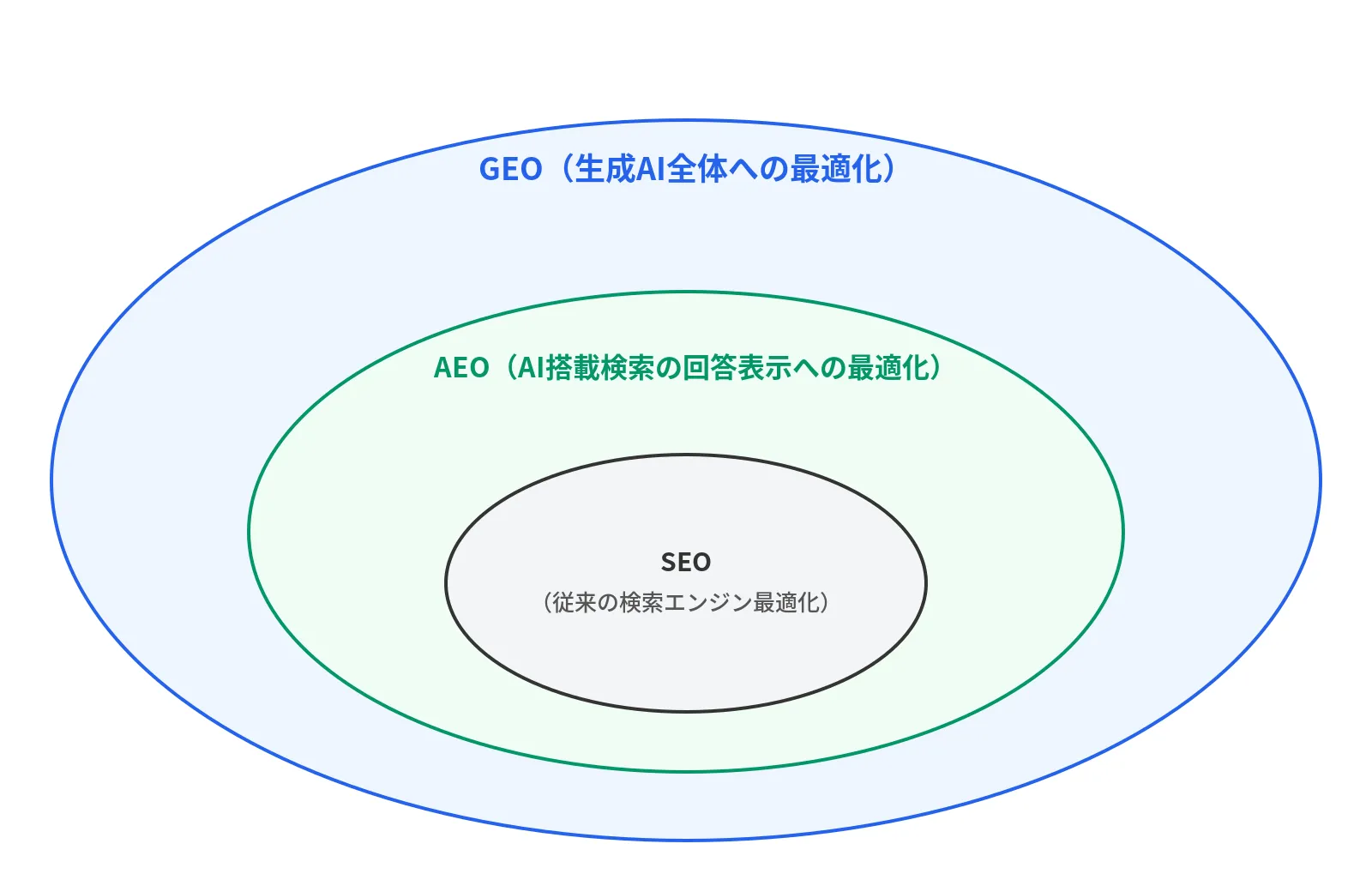
SEO forms the foundation, AEO sits on top of it, and GEO is layered above that. The key insight is that GEO and AEO don’t replace SEO. They are additional layers on top of SEO. Abandoning SEO to focus solely on GEO is a mistake.
Semrush’s survey data supports this as well. ChatGPT users are not abandoning Google Search. Rather, AI usage is expanding overall search behavior.
This book primarily uses “LLMO” for technical precision, but also uses GEO and AEO depending on context. Regardless of which term appears, understand that they all fundamentally refer to optimization aimed at getting “your content referenced in AI answers.”
Why Now: Why 2025 Is the Tipping Point
“AI will transform search” has been said for several years. So why does “now” matter?
There are concrete reasons why 2025 is the tipping point.
First, the discontinuation of external Bing Search API access (August 2025). This effectively left Brave Search as the only independent search API available to AI providers. The diversity of search backends collapsed overnight, and the importance of Brave optimization skyrocketed.
Second, the explosive growth of the AI agent market. Agent frameworks like OpenClaw, AI coding assistants like Cursor and Windsurf, custom corporate AI agents: these are being embedded into daily workflows. Agents search for information on behalf of users, gathering decision-making materials. Even without humans opening Google, AI is executing web searches. That era has arrived.
Third, the rollout of Apple Intelligence. With AI features shipping as standard on iPhones, mobile user search behavior could change dramatically. When over 1 billion iPhones worldwide begin offering AI search by default, the impact will be enormous.
All these changes are happening simultaneously in 2025. This is precisely why now is the time to invest in LLMO. Continuing to fight with SEO alone is like faxing clients in the smartphone era. It still works. But your reach is limited.
LLMO as an Engineering Problem
Reading this far, some of you may be thinking, “Isn’t this a marketer’s job?”
It isn’t. LLMO is fundamentally an engineering problem.
Traditional SEO had a heavy marketing component, with content planning and keyword research at its core, while technical implementation (structured data, Core Web Vitals, site architecture) was just one part of it.
In LLMO, the technical weight is far greater:
- Understanding the architecture of how LLMs retrieve information, process it, and generate answers
- Content structure design that accounts for RAG system Query Fan-out
- Implementation of structured data via JSON-LD
- AI crawler control through
llms.txtandrobots.txt - Understanding differences across search platforms: Brave Search API, Google Search Grounding, Bing API
- Automating AI visibility measurement (monitoring via Python scripts)
These are tasks that belong to an engineer’s skill set, not a marketer’s.
Moreover, we engineers are “stakeholders” in LLMO.
When you use Gemini CLI to write code, when you do technical research with Claude Code, when you compare libraries on Perplexity: you’re an AI search “user.” At the same time, when you write tech blog posts, maintain OSS documentation, or polish API references: you’re an AI search “content provider.”
Engineers who hold both perspectives are best positioned to understand the reality of LLMO and to practice it most effectively.
SEO Won’t Die, But It Will Change
Finally, let me emphasize something important.
SEO is not dead.
Google’s search share remains at 90%. The vast majority of users still search on Google. AI-driven traffic is growing rapidly, but it’s still under 1% of total traffic (Ahrefs study).
However, the quality of that sub-1% traffic is exponentially higher.
Ahrefs research reports cases where the conversion rate of LLM-driven visitors was up to 23 times higher than organic search (AI search visits accounted for 0.5% of total traffic but 12.1% of sign-ups). SimilarWeb’s global e-commerce data shows AI-driven conversion rates at 11.4% versus 5.3% for organic search, roughly a 2x gap. Semrush data indicates that the average conversion rate from LLM-referred visitors is 4.4 times that of traditional search traffic.
Low volume but overwhelmingly high quality. That’s the defining characteristic of AI search traffic.
And this “volume” is growing at a pace of several hundred percent per year. If Gartner’s prediction holds and traditional search declines 25% by 2026, much of that traffic will flow through AI channels.
As an engineer, if you care about the visibility of your tech blog or OSS project, there is more than enough reason to start working on LLMO now. You don’t need to abandon SEO. Layer LLMO on top of SEO. That is the fundamental strategy for information dissemination on the web going forward.
This book is your practical guide to doing exactly that. Reverse-engineering from LLM internals, and from an engineer’s perspective, it explains what to optimize and how.
In Chapter 2, we’ll take a deep technical dive into the three pathways through which information reaches LLMs: training data, RAG, and AI agent real-time search.
Key Takeaways
- AI agents search using Brave Search, not Google. The premise of SEO strategy is breaking down.
- User information-seeking behavior is irreversibly shifting from “ten blue links” to “one AI answer.” Gartner predicts a 25% decline in traditional search traffic by 2026.
- LLMO/GEO/AIO/AEO are different names for the same phenomenon. The essence is optimization to get “your content cited in AI answers.”
- SEO won’t die, but SEO alone isn’t enough. A hybrid strategy that layers LLMO on top of SEO is necessary.
- LLMO is fundamentally an engineering problem. LLM architecture, RAG, structured data, crawler control: technical understanding is essential.
03 Three Pathways Information Reaches LLMs
Chapter 2: Three Pathways Information Reaches LLMs
Why your site doesn’t appear when someone asks ChatGPT.
Say you’ve written a tech blog post. You’ve done your SEO and you’re ranking well on Google. But when someone asks ChatGPT a related question, your article is never cited.
Why?
The answer is simple. The pathway through which an LLM “knows” your content and the pathway through which Google indexes your content are completely different.
This chapter dissects the three pathways through which information reaches LLMs from a technical perspective. Understanding each pathway’s mechanics is the starting point for any LLMO strategy.
Let’s use a library metaphor to grasp the big picture.
SEO is like registering your book correctly in the library catalog. LLMO, on the other hand, is about creating a situation where the librarian (AI) recommends your book to patrons: “I’d suggest this one.” Even if you’re in the catalog, if the librarian doesn’t know about your book, they can’t recommend it.
The three pathways map to the librarian’s information sources. Training data is the librarian’s memory of books they’ve read. RAG is searching the shelves on the spot. Agent search is running to the next library over to look something up.
The Big Picture: Three Pathways
LLM “knowledge” of content can be broadly classified into three pathways.

Each has a completely different time scale for information delivery, different optimization methods, and different durability of effects. Let’s examine them in order.
Pathway 1: Training Data: The Long Game
The Nature of LLM “Memory”
State-of-the-art LLMs like GPT-4o/o3 and Claude Sonnet 4/4.5 are pre-trained on massive text datasets. Information contained in this training data gets encoded into the model’s parameters, essentially becoming the LLM’s “memory.”
When a user asks “How do I use React’s useEffect?”, the LLM uses knowledge from React documentation and blog posts it read during training to generate a response. In this case, no source citations accompany the answer, because it’s generated directly from the LLM’s “memory.”
GPT-3’s Training Data Composition
Let’s look concretely at how LLM training data is composed. GPT-3’s training data composition was published in OpenAI’s paper (“Language Models are Few-Shot Learners”, 2020, Table 2.2), and subsequent models follow roughly the same structure.
| Data Source | Token Share | Training Weight |
|---|---|---|
| CommonCrawl | 80%+ | 60% (reduced) |
| WebText2 | Small | ~22% (6x increase) |
| Books | Small | ~8% (increased) |
| Wikipedia | Small | ~3% (5x increase) |
What’s notable here is the divergence between token share and training weight.
CommonCrawl has the largest data volume but its training weight is held to 60%. Meanwhile, Wikipedia and WebText2 have their training weights inflated 5-6x relative to their data volume.
In other words, not all web pages are treated equally in LLM training. Sources judged as high-quality receive greater weight.
Influence Pathways for Each Data Source
CommonCrawl
This is broad crawl data from across the web. If your website isn’t blocking CCBot (CommonCrawl’s crawler), it’s eligible for collection. However, it may be excluded during the sanitization (quality filtering) process.
This is technically the lowest-barrier pathway, but since training weight is reduced, being included here alone doesn’t carry significant influence.
Wikipedia (5x training weight)
Nearly all LLMs give special weight to Wikipedia. Semi-structured content, strict moderation, multilingual support, semantic cross-links: Wikipedia has ideal characteristics for LLM training data.
The practical implication is clear. If your product or technology is mentioned in a Wikipedia article, the probability of it being encoded into the LLM’s “memory” increases substantially. However, Wikipedia editing is notoriously difficult. Articles that don’t meet notability criteria get deleted, and promotional editing can backfire.
WebText2 (6x training weight)
This is less well-known but extremely important.
WebText2 is a dataset built by scraping pages from outbound links in Reddit posts that received 3 or more upvotes.
In other words, content that the Reddit community judged as “valuable” is incorporated into LLMs with 6x training weight.
This has critical implications for technical content. If your tech blog gets shared on Reddit’s r/programming or r/javascript and earns upvotes, it could be incorporated into future LLM training data with high weight.
The Cutoff Wall
The biggest constraint of the training data pathway is the cutoff date.
LLM training data has a clear expiration date. For example, GPT-4o’s training data extends to October 2024, and Claude Sonnet 4.5 to April 2025 (as of writing; varies by model version). Content published after the cutoff is not included in training data.
Furthermore, model retraining doesn’t happen frequently. The update from GPT-3 to GPT-4 took about 3 years. That means content published today will be reflected in training data at the earliest in a few months, and typically in 1-2 years.
This is why it’s called “the long game.” Incorporation into training data takes the longest of any LLMO pathway, but once incorporated, it persists as part of the model’s “memory” for an extended period.
Training Data Optimization in Practice
Here are the common characteristics of content that tends to be incorporated into training data:
- Publication on authoritative domains: Content featured in major media outlets (NYT, Bloomberg, etc.) influences training data through three pathways: CommonCrawl (directly) + Wikipedia citation (indirectly) + Reddit upvotes (WebText2)
- Natural sharing on Reddit: Links shared in a way that provides value to the community, not spam
- Wikipedia mentions: Being cited as a reliable source
- Publishing original data: Primary information not available elsewhere gets cited and shared more readily, making it more likely to enter training data
Pathway 2: RAG: The Medium Game
How RAG Works
RAG (Retrieval-Augmented Generation) is a mechanism where LLMs perform real-time web searches to supplement information not in their “memory,” then generate responses based on the retrieved information.
ChatGPT’s “Browse with Bing,” Perplexity’s web search, and Google AI Overviews’ Search Grounding are all RAG implementations.
The basic processing flow of RAG is as follows:
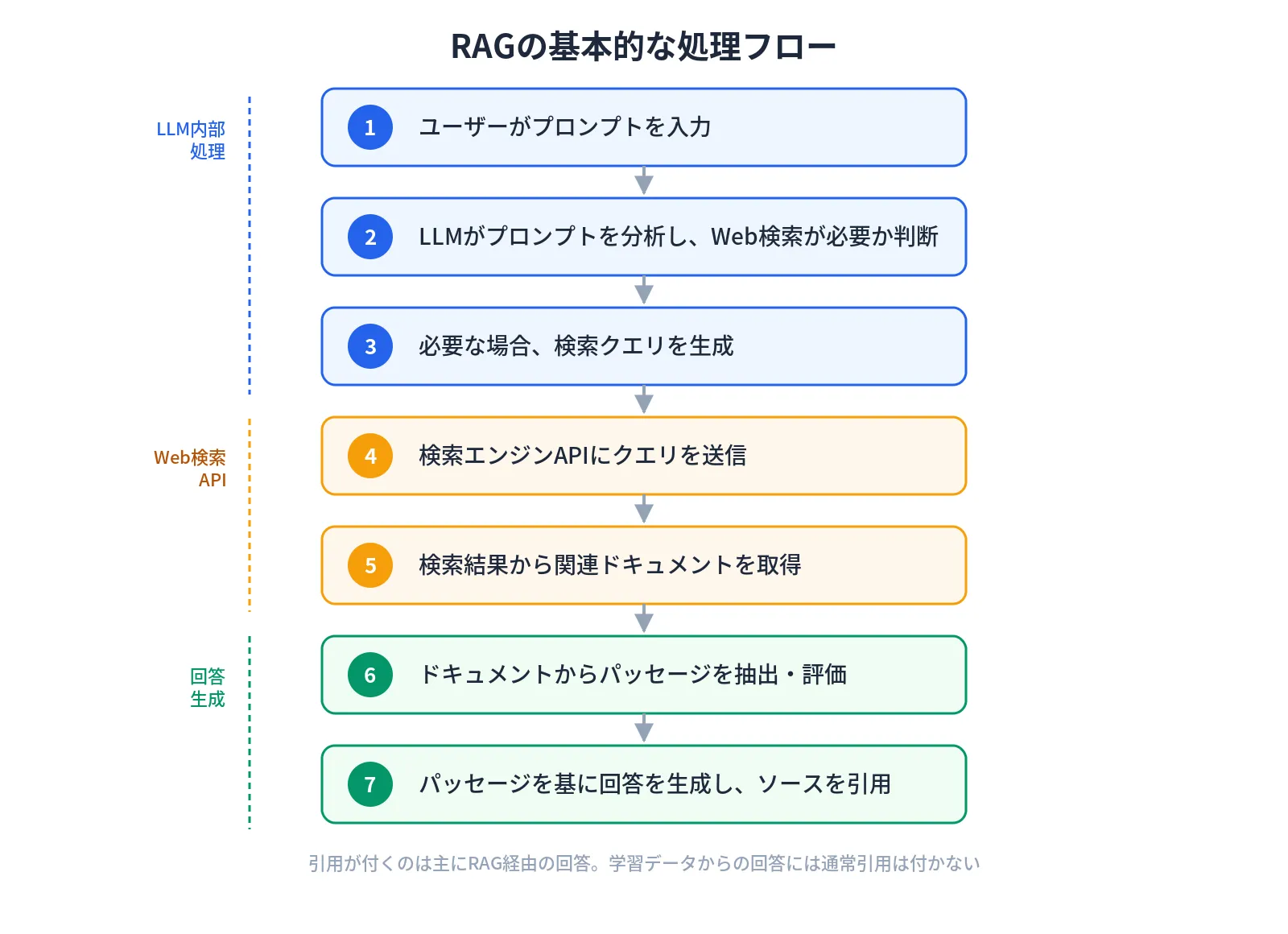
Citations appear primarily in RAG-based responses. Responses drawn from training data typically don’t include citations. This means that for LLMO aimed at “getting cited by AI,” RAG is the most direct target pathway.
Query Fan-out: One Question Becomes Multiple Searches
Within RAG, the most important concept for LLMO is Query Fan-out.
When a user asks “Should I use HubSpot for my startup?”, the RAG system internally decomposes this question into multiple sub-queries:
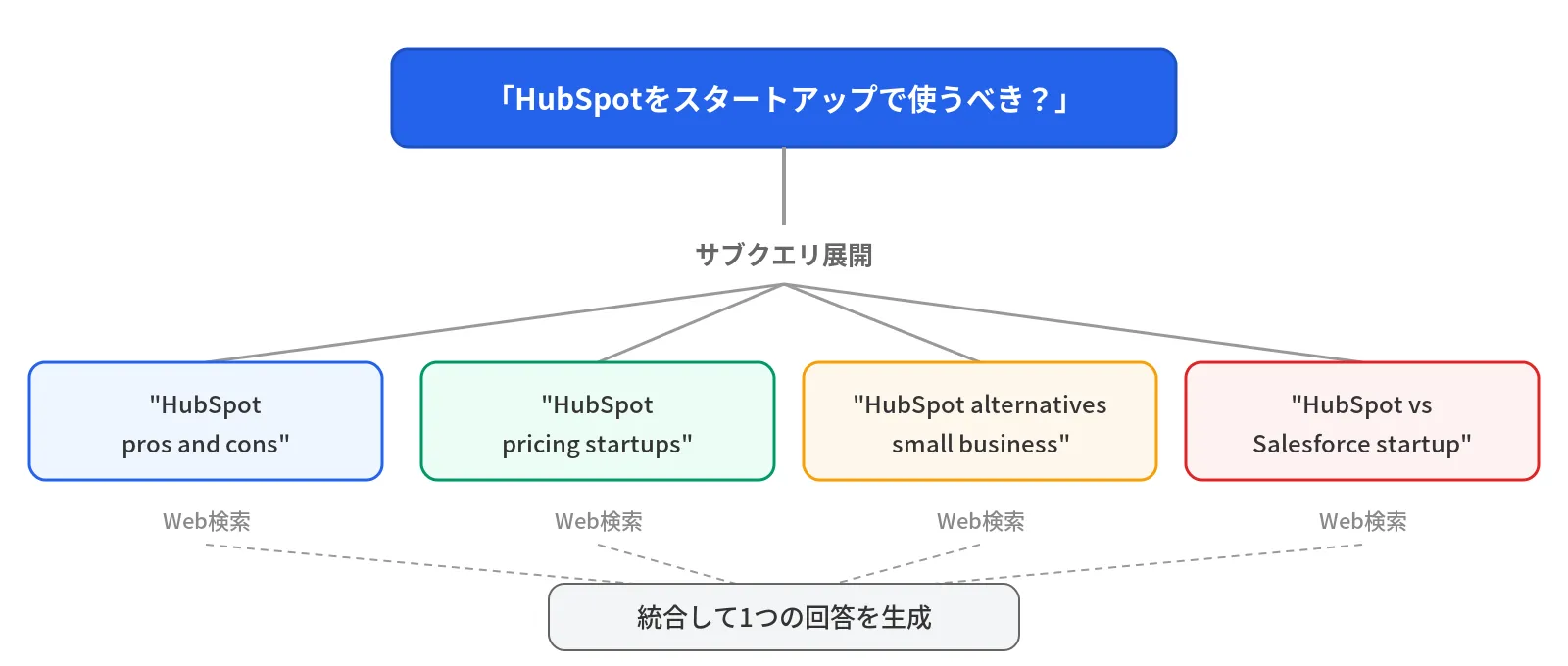
Each sub-query independently executes a web search, and passages are extracted from each set of search results. Finally, these passages are synthesized to generate a single answer.
SurferSEO’s analysis data demonstrates the practical impact of this mechanism:
- Ranking in sub-queries → 49% more likely to be cited than ranking in the main query alone
- Ranking in both the main query AND sub-queries → 161% more likely to be cited
This means that at the content design stage, it’s critical to anticipate “what sub-queries AI will generate for this topic” and include sections that answer each sub-query.
Passage-Level Optimization
There’s another important concept to understand for RAG pathway optimization.
LLMs evaluate and cite content at the passage level (paragraph/section), not at the whole-page level.
According to SurferSEO’s analysis, 67.82% of AI Overviews citation sources are NOT in Google Search’s Top 10. This means that even if a page’s overall SEO ranking is low, specific passages that directly answer a question can be cited by AI.
Conversely, a page that ranks #1 for SEO might not be cited by AI if the answer is buried in lengthy text or expressed ambiguously.
Key considerations for passage-level optimization:
## Question-format heading
[1-2 sentence direct answer]
[Supporting explanation, data, evidence]Design each section as a “self-contained answer.” The heading is the question, followed immediately by a concise answer, with evidence and data below.
Characteristics of Citable Content
Ahrefs analyzed roughly 60,000 sites and revealed structural characteristics of content that LLMs tend to cite:
1. Freshness
AI assistants prioritize content that is 25.7% newer than organic search results (Ahrefs study). On Perplexity, freshness accounts for approximately 40% of ranking factors.
However, “fake freshness” where only the date is changed without updating text is detected by AI. Substantive content updates are necessary.
2. Domain Authority
Analysis of the top 1,000 sites cited by ChatGPT shows that sites with DR (Domain Rating) 60+ are dominant. LLMs don’t directly evaluate DR, but since the search engines used in RAG factor DR into their rankings, it has an indirect effect.
3. Original Data
Content containing primary information not available on other sites: proprietary research data, experimental results, benchmarks. Ahrefs’ most cited page being “How Much Does SEO Cost?” (an article based on their own survey data) confirms this.
4. Structured Format
Clear headings, bullet points, tables, numbered lists: structures that make it easy for AI to extract passages. Microsoft’s official guide also recommends “clear meaning, consistent context, clean formatting.”
Citation and Traffic Are Different Things
One important caveat here.
According to Ahrefs’ analysis, only 10% of the top 1,000 most-cited pages also appear among the top pages for ChatGPT traffic.
Being cited and receiving traffic are not necessarily the same thing. AI may cite your article’s information while presenting it to the user as an integrated part of its answer, meaning users often don’t bother clicking through to the original article.
However, citations carry value beyond traffic. LLM-driven traffic, while low in volume, achieves conversion rates of 4.4x (Semrush) to up to 23x (Ahrefs) compared to organic search. And the very fact that AI repeatedly cites “this source is trustworthy” builds brand authority.
Pathway 3: AI Agent Real-Time Search: Immediate Impact
This is where this book’s unique perspective comes in.
Training data (Pathway 1) and RAG (Pathway 2) are covered in many LLMO-related books. However, the third pathway, AI agent real-time search behavior, is almost never discussed in depth.
This is a phenomenon I observe daily through developing and operating AI agents.
AI Agents Search via Brave API
As mentioned in Chapter 1, my AI agent (Iris on OpenClaw) retrieves information using the Brave Search API.
But this isn’t unique to my agent. As the AI agent market grew rapidly from 2024 to 2025, Brave Search became the de facto default search backend.
Why Brave?
Three main reasons:
- API availability stability: After Microsoft discontinued external Bing Search API access in August 2025, Brave became effectively the only independent search API option
- Zero Data Retention (ZDR): The Brave Search API has a policy of not storing any search queries. For AI providers, the fact that user queries aren’t accumulated by third parties is a crucial privacy requirement
- LLM Context API: In February 2026, Brave released a new API optimized for AI. It converts HTML into structured data and returns “smart chunks” broken down to the JSON-LD and table-row level
Why this third pathway matters for LLMO is that Google’s search index and Brave’s search index are different.
A page that ranks #1 on Google might be on page 5 of Brave. Conversely, a page buried on Google might rank highly on Brave. Brave Search has its own index (300 billion pages, with 100 million pages updated daily) and employs a user-behavior-based natural index construction called the Web Discovery Project.
In other words, if you want to capture traffic via AI agents, you need to ensure visibility on Brave Search in addition to Google SEO.
The Daily Reality of Using Gemini CLI to Reference Reddit
One of my daily workflows involves using Gemini CLI.
Gemini CLI is Google’s command-line version of Gemini, with built-in Google Search Grounding. When you ask technical questions, it automatically performs Google searches and generates responses based on the results.
What’s interesting is that when you look closely at Gemini’s answer sources, Reddit technical threads are frequently cited.
When I ask Gemini CLI about practical problems like “Caching not working with Next.js 15’s App Router,” Reddit’s r/nextjs threads sometimes get cited over Stack Overflow answers. This is likely due to both Google Search’s increasing valuation of Reddit (the Reddit IPO data deal from 2024 being one factor) and the fact that Reddit threads contain raw, practical answers to real-world questions.
What engineers should recognize is that when you use Gemini CLI or ChatGPT for technical research, the “information pathways” sourcing those answers differ from traditional search.
Claude in Chrome: Retrieving Information via Browser Sessions
Here’s another phenomenon I observe daily.
When using Claude (the Claude in Chrome extension) in the Chrome browser, it can leverage browser session information to access data from services that require login.
Specifically, when you have an X (formerly Twitter) timeline open and ask Claude a question, it reads the content of posts on the timeline and generates responses that reference them.
This is a different mechanism from typical RAG. It’s not calling a web search API; it’s directly reading the browser’s DOM (Document Object Model). In other words, it accesses web information directly through the “browser” without going through a “search engine.”
This behavioral pattern will become increasingly common as AI agents evolve. Through MCP (Model Context Protocol) tool integrations, web browsing for real-time information retrieval, and even direct API calls for data collection: the means by which AI retrieves information are no longer limited to “search engines.”
From “Search Engine” to “Information Retrieval Method”
Traditional SEO was a technology for optimizing for “search engines.” The target was a single platform called Google, and you just needed to optimize for its index and algorithms.
LLMO in the AI agent era is optimization for “information retrieval methods” as a whole.
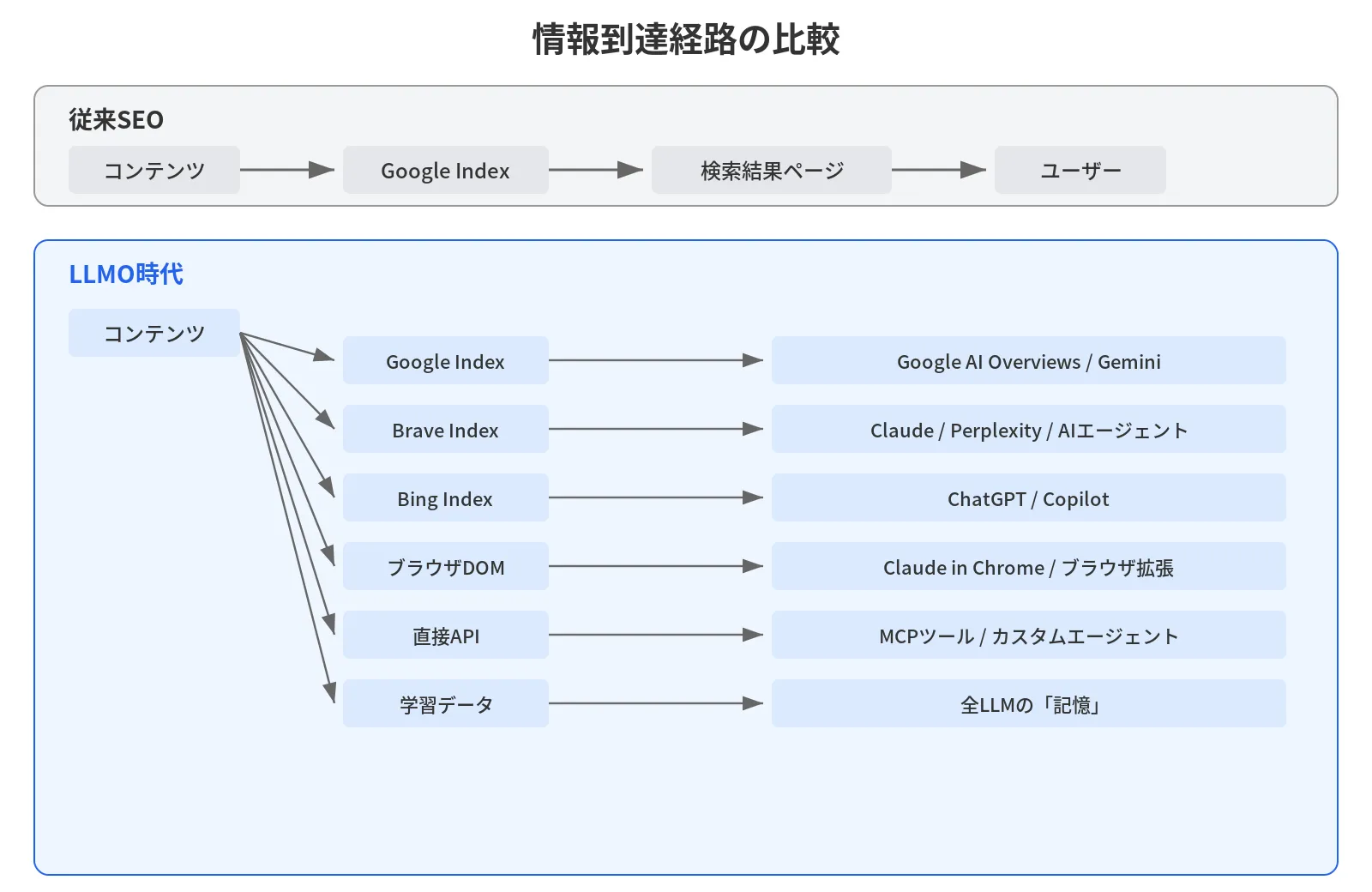
The pathways through which content reaches information consumers (humans or AI) have become dramatically more diverse.
Optimization Priority Framework for the Three Pathways
Now that we understand the three pathways, let’s address the practical question: which pathway should you prioritize for optimization?
This depends on your goals and timeline.
For immediate results: Pathway 2 (RAG) and Pathway 3 (Agent Search)
If you already have published content, starting with RAG and agent search citation optimization is most efficient. Simply improving content structure (headings, lists, tables) and restructuring passages to “directly answer questions” can increase your AI citation rate.
Specific actions:
- Add structured data (JSON-LD) to each article
- Use question-format headings with concise answers immediately following
- Clearly state original data and statistics (e.g., “Our research found that…”)
- Update content quarterly to maintain freshness
For medium-to-long-term investment: Pathway 1 (Training Data)
Publishing original data, getting articles in authoritative media, building a natural presence in Reddit communities, establishing a presence on Wikipedia. These take time but, once achieved, deliver lasting effects as part of the LLM’s “memory.”
Specific actions:
- Regularly publish industry research reports and benchmark data
- Turn conference presentations into articles
- Enhance OSS project documentation
- Share technical articles naturally on Reddit and Hacker News (no spam)
To prepare for the AI agent era: Pathway 3 (Agent Search)
Verify your visibility on Brave Search, set up llms.txt, properly allow access for AI crawlers, and enrich structured data to improve extraction precision with the Brave LLM Context API.
Specific actions:
- Search your key terms on Brave Search and assess current visibility
- Properly allow AI crawlers (GPTBot, ClaudeBot, Applebot-Extended, etc.) in
robots.txt - Create
llms.txtso AI can efficiently understand your site’s content - Implement JSON-LD structured data (Brave LLM Context API prioritizes JSON-LD extraction)
Priority Matrix
| Condition | Priority Pathway | Expected Time to Results |
|---|---|---|
| Abundant existing content | Pathway 2 (RAG optimization) | 1-3 months |
| Planning new content | Pathway 2 + Pathway 3 | 3-6 months |
| Building brand awareness | Pathway 1 (Training data) | 6 months - 2 years |
| Running tech tools/OSS | Pathway 3 (Agent search) | 1-3 months |
| Want to do everything | Pathway 2 → Pathway 3 → Pathway 1 | Phased approach |
The key point is that the three pathways are not mutually exclusive. Improving content structure for RAG optimization also helps with the agent search pathway. Publishing original data increases RAG citation rates while also making content more likely to enter future training data.
The most efficient approach is to start with Pathway 2 (RAG) optimization and let it cascade into Pathway 3 (Agent Search) and Pathway 1 (Training Data).
When LLMs Execute Searches
Finally, let’s clarify when LLMs actually “execute” web searches (RAG or agent search).
LLMs don’t always perform web searches. Searches are triggered under the following conditions:
- When current information is needed: Breaking news, current prices, latest release information
- Topics not in training data: Niche technologies, new libraries, recent security vulnerabilities
- Requests for statistics or data: Specific numbers, market research, benchmark results
- YMYL (Your Money or Your Life) topics: Medical, financial, and legal information (where accuracy is critical)
- Explicit user requests: Instructions like “search for the latest information” or “look this up on the web”
Conversely, for general questions that the LLM can confidently answer from training data alone, no web search is executed and no citations are provided.
This has an important implication for LLMO strategy.
If your content includes “fresh original data,” “niche domain expertise,” or “specific statistics,” the probability of an LLM triggering a web search increases, which in turn increases the chances of your content being cited. Content that merely rehashes generic knowledge gives the LLM no reason to search, so citation opportunities never arise.
In Chapter 3, we’ll take a deep dive into Brave Search, which has become the default search engine for AI agents, examining its architecture and implications for LLMO.
Key Takeaways
- There are three pathways through which information reaches LLMs: Training data (long game), RAG (medium game), and AI agent real-time search (immediate impact).
- Training data weights are not equal: Wikipedia and WebText2 (derived from Reddit links) have 5-6x training weight. A natural presence on Reddit influences future LLM “memory.”
- For RAG, Query Fan-out and passage-level optimization are key: AI expands a single question into multiple sub-queries and evaluates/cites content at the paragraph level, not the page level.
- AI agents use search engines other than Google: Brave Search is the de facto default. Google SEO alone cannot secure visibility via AI agents.
- Start optimizing from RAG (Pathway 2): Begin with content structure improvements, then cascade into agent search readiness and training data investment for maximum efficiency.
Overview
Google SEO won't get you cited by ChatGPT or Perplexity. This book maps LLMO (LLM Optimization) — the patterns and implementations for AI search era. From llms.txt and JSON-LD to citation-rate KPIs, this is the field guide for being seen by AI search engines.
What you will be able to do
- Understand LLMO basics and how it differs from Google SEO
- Implement llms.txt and JSON-LD to be picked up by AI search engines
- Reverse-engineer citation logic of ChatGPT, Perplexity, and Brave
- Design KPIs to measure AI citation rate
- Extract concrete improvement points from real case studies
Who is this book for
- [Web Owner] My site doesn't show in ChatGPT or Perplexity
- [Marketer] Need the next layer beyond Google SEO
- [Tech Blogger] Want to lift AI citation rates
- [PM] Building SEO strategy for the AI search era
- [LLMO Beginner] Need terminology and concepts laid out systematically
Problems this book solves
- ChatGPT search never shows my site
- Want to be in Perplexity's citations but don't know what to optimize
- Unsure if llms.txt is necessary or what it means
- Hard-earned Google SEO authority doesn't carry over to AI search
- No idea how to measure AI citation rate
- Not confident my Schema.org / JSON-LD implementation is working
Where this book stands
- Implementation-focused (concrete examples for structured data and llms.txt)
- Intermediate (HTML/SEO basics assumed; LLMO is the next layer)
- For Google SEO graduates (we don't reteach SEO; we go beyond)
- Cross-engine (ChatGPT / Perplexity / Brave behavior compared)
Why this book
- One of the first books to systematize the term LLMO
- Includes llms.txt implementation patterns with verification results
- Introduces AI citation rate as a new KPI
- Compares citation behavior across ChatGPT, Perplexity, and Brave
- Rich Schema.org JSON-LD examples
How this differs from other AI books
| Compared to | This book's difference |
|---|---|
| Google SEO books | Not an extension of Google SEO. Specifically optimizes for AI search engines. |
| AI / LLM intro books | Not theory. Implementation-focused on making sites discoverable by AI. |
| ChatGPT how-to books | Not about using ChatGPT — about being used by it (cited by it). |
Table of contents
- 01 Preface — Why LLMO? Free preview
- 1-1 Background
- 1-2 Purpose of This Book
- 1-3 Target Audience
- 1-4 How to Read This Book
- 1-5 Technical Environment
- 02 How AI Search Engines Work Free preview
- 03 Google SEO vs LLMO Free preview
- 04 llms.txt Design and Implementation
- 05 JSON-LD / Schema.org Patterns
- 06 Content Optimization
- 07 Structuring for Citation Rate
- 08 ChatGPT Citation Logic
- 09 Perplexity Citation Logic
- 10 Brave Search Behavior
- 11 AI Citation Rate KPI Design
- 12 Case Studies
- 13 The Future
- 14 Afterword
Ranking #1 on Google won’t get you quoted by ChatGPT. AI search engines look at a different signal landscape.
This book maps that other landscape, LLMO (LLM Optimization), through llms.txt, JSON-LD, structured data, and citation-rate KPIs. Implementation-level, not theory-level.
“#1 on Google ≠ cited by ChatGPT.”
Related books


Read on Kindle
Included in Kindle Unlimited
Read on Kindle* This page contains Amazon Associates links. Purchases may earn the author a referral fee.