
なぜあなたのサイトはChatGPTに無視されるのか
LLMO実践ガイド
LLMO 実践ガイド | AI検索最適化・llms.txt・JSON-LD・引用率改善の体系書
Zenn累計32,000+ views · 4言語で30冊以上出版 · Kindle 6カ国で販売中
📖 無料で読める章
買う前に3章をその場で読めます。気に入ったらKindleで続きを。
01 はじめに
あなたのサイトは、ChatGPTに無視されています。
Google検索で1位を取っていても、AIの回答にあなたのサイトは出てきません。なぜか。
はじめに
本書の背景
ある日、自分のAIエージェントのログを眺めていて、奇妙なことに気づきました。
OpenClawというAIエージェントフレームワークをセットアップしていたときのことです。設定画面で「Brave Search APIキー」の入力を求められました。Google APIキーではなく、Brave。日常のリサーチを任せていたAIエージェントがWeb検索に使っていたのは、Googleではなかったのです。
SEO対策をしていた検索エンジンと、AIが実際に情報を取得する検索エンジンがまったく別物だった。この発見が、本書を書くきっかけになりました。
調べてみると、これは私のエージェントだけの話ではありませんでした。検索の主戦場が、Googleの「10本の青いリンク」からAIの「1つの回答」へと移り始めています。そして、従来のSEOだけでは、この新しい戦場で戦えないことが明らかになってきました。
本書の目的
本書は、LLM(大規模言語モデル)に自社のコンテンツを「見つけてもらう」ための実践ガイドです。
私はこの領域を LLMO (Large Language Model Optimization)と呼んでいます。SEOがGoogleの検索アルゴリズムに最適化する技術だとすれば、LLMOはAIの情報取得メカニズムに最適化する技術です。
本書の核となるのは、 3つの経路フレームワーク です。LLMに情報が届く経路は3つしかありません。
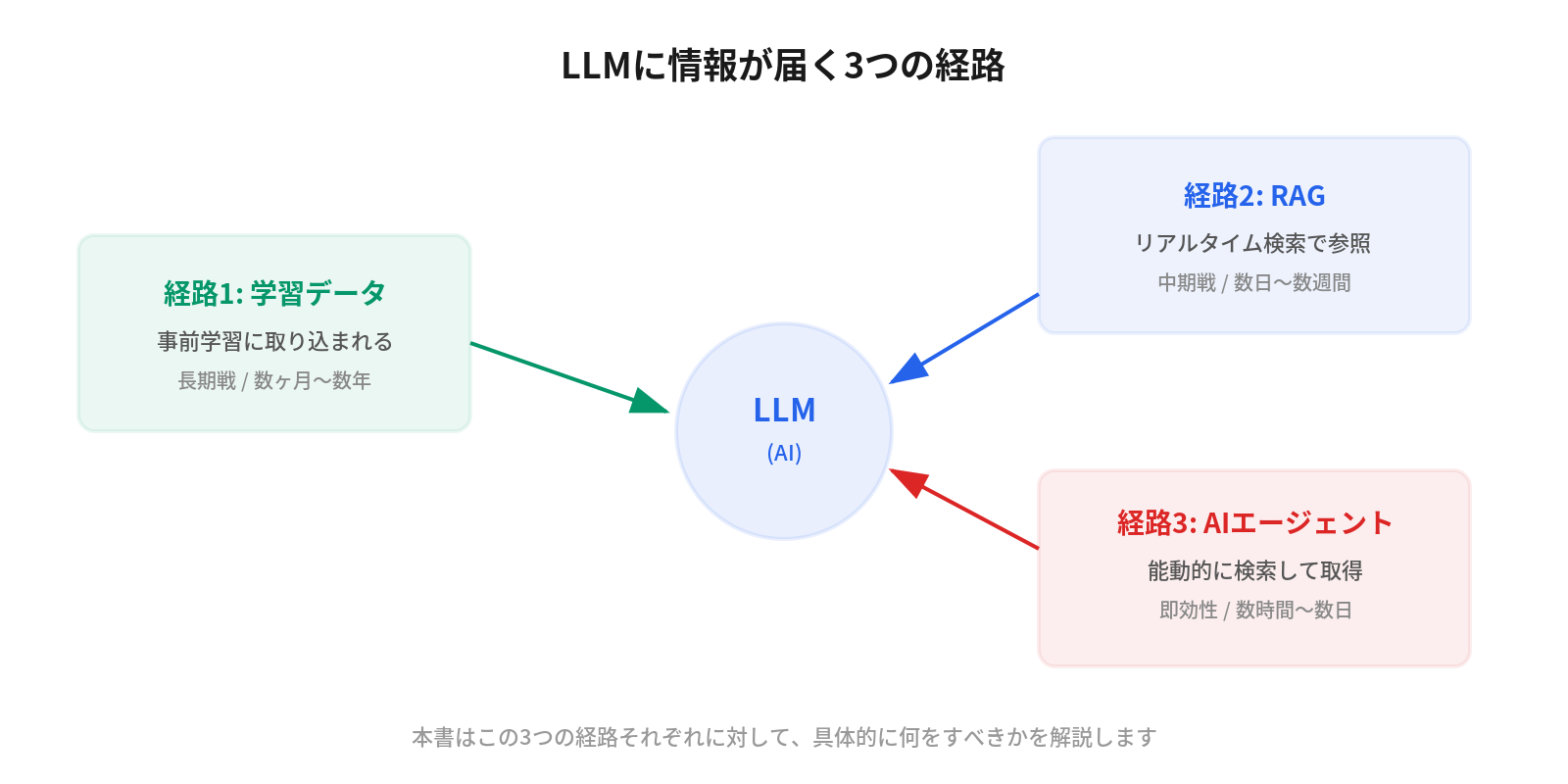
- 学習データ:モデルの事前学習に取り込まれる
- RAG (検索拡張生成):リアルタイム検索で参照される
- AIエージェントの検索行動:CLIツールやエージェントが能動的に検索する
この3つの経路それぞれに対して、具体的に何をすべきかを解説します。
対象読者
- SEOの基本的な知識があるエンジニア・マーケター
- AI検索での可視性を高めたいプロダクト担当者
- ChatGPT、Perplexity、Claude等のAI検索の仕組みを理解したい技術者
- コンテンツ戦略をAI時代にアップデートしたい経営者・ディレクター
本書の読み方
全体を通して読む場合: 第1章から順に読むと、「なぜLLMOが必要か」→「仕組みの理解」→「実装」→「測定・改善」と段階的に理解が深まります。
実装から始めたい場合: 第7章(構造化データ)、第8章(llms.txt / robots.txt)から読み始め、必要に応じて前の章に戻ると効率的です。
意思決定者の場合: 第1章、第11章(ケーススタディ)、第12章(未来展望)を先に読むと、LLMOの全体像と投資判断の材料が得られます。
本書で使用する環境
本書のコード例は以下の環境で動作確認しています。
- Python 3.10以上
- Node.js 18以上
- Claude Code、Gemini CLI、Codex CLI(各最新版)
コード例は基本的にそのまま動作しますが、APIキーの取得など初期設定が必要なものもあります。詳細は各章の説明を参照してください。
それでは、AI検索時代の新しい最適化戦略を一緒に学んでいきましょう。
この続きはKindleで →02 SEOが壊れる日
第1章: SEOが壊れる日
あなたのSEO対策、AIは見ていません。
私のAIエージェントが教えてくれたこと
2026年のある日、私は自分のAIエージェントのログを眺めていて、奇妙なことに気づきました。
私はOpenClawというAIエージェントフレームワークを使っています。日常的なリサーチや情報収集を、Claude(Anthropic社のLLM)ベースのエージェントに任せています。そのエージェント「Iris」がWeb検索を実行するとき、何を使っているのかをふと確認したのです。
Brave Search API。
Googleではありませんでした。
私はフリーランスとしても複数の案件を受けているのですが、そのうちの一つの案件でSEO(Search Engine Optimization)に取り組んでいました。見出し構造を整え、メタディスクリプションを最適化し、内部リンクを設計する。すべてはGoogleの検索結果で上位に表示されるためです。
しかし、私のAIエージェントはGoogleを見ていなかった。
この発見は、私にとって衝撃でした。自分がSEO対策をしていた検索エンジンと、AIが実際に情報を取得する検索エンジンが、まったく別物だったのです。
さらに調べてみると、これは私のエージェントだけの話ではありませんでした。Anthropic社のClaudeはBrave Searchを検索バックエンドとして採用しています。Perplexityも検索ソースの一つとしてBraveを利用しています。AIコーディングアシスタントの多くも、Brave Search APIとの連携機能を提供し始めています。
つまり、2024年から2025年にかけて急速に普及したAIツールの多くが、情報を取得する際にGoogleではなくBrave Searchを使っているのです。
Gemini CLIを使って技術的な質問をすると、Redditのr/programmingのスレッドが回答のソースとして引用されることがあります。Claude in Chromeでは、ブラウザで開いているX(旧Twitter)のタイムライン情報を参照して回答を生成します。
どのAIツールを見ても、情報取得の経路はGoogleの検索結果ページを経由していません。AIが「情報を探す」行為と、人間が「Googleで検索する」行為は、もはや別の現象なのです。
Google検索の20年支配
話を少し巻き戻しましょう。
Googleが検索市場を支配し始めたのは2000年代初頭です。PageRankアルゴリズム。「多くの良質なサイトからリンクされているページほど重要」という考え方で、Webページの重要度を数値化する仕組み。によって、それまでのディレクトリ型検索を圧倒し、「検索する」=「ググる」という文化を作り上げました。
2024年時点で、Googleのグローバル検索シェアは約90%です。デスクトップで約85%、モバイルで約95%。残りをBing、Yahoo!、DuckDuckGoなどが分け合っています。
Webに関わるエンジニアやマーケターにとって、「検索最適化」とは事実上「Google最適化」を意味してきました。Googleのアルゴリズムアップデートに一喜一憂し、Core Web Vitalsに対応し、E-E-A-T(Experience, Expertise, Authoritativeness, Trustworthiness)を意識してコンテンツを作る。これが20年間の常識でした。
この前提が、いま崩れ始めています。
「10本の青いリンク」から「1つのAI回答」へ
Google検索の結果ページを思い浮かべてください。タイトルとスニペットが並ぶ「10本の青いリンク」。これが検索体験の基本形でした。ユーザーはリンクをクリックし、各サイトを訪問し、自分で情報を統合して判断します。
しかし、ChatGPTの登場以降、ユーザーの情報取得行動が根本的に変わりました。
「ChatGPTに聞く」「Perplexityで調べる」「Geminiに相談する」。こうした行動が、特に技術者の間で急速に一般化しています。複数のサイトを巡回する代わりに、AIに質問して、統合された1つの回答を受け取る。
この変化を裏付けるデータがあります。
- 米国ユーザーの 27% が、日常的な検索をAIチャットボットで代替している(2025年2月調査)
- Gartnerは 2026年までに従来の検索エンジンのトラフィックが25%減少 すると予測している
- AI Overviewsの表示により、Google検索1位のCTR(クリック率)が 34.5%低下 した(Ahrefs調査、300,000キーワード対象)
一方で、AI経由のリファラルトラフィックは前年比 357%増加 しています(SimilarWeb)。つまり、検索トラフィック全体のパイが変わっているのではなく、「どこ経由で情報にたどり着くか」のチャネルが大きくシフトしているのです。
ここで重要なのは、この変化が不可逆であるということです。
一度「AIに聞けば一発で答えが返ってくる」という体験をしたユーザーが、わざわざ「10本の青いリンク」に戻ることはありません。電卓が普及した後にそろばんに戻らないのと同じです。特にエンジニアのように、効率を重視する職種ではなおさらです。
私自身、技術的な疑問が浮かんだとき、最初にやることが変わりました。以前はGoogle検索でStack Overflowの回答を探していました。今は、Claude CodeやGemini CLIに直接聞きます。そのほうが速く、正確で、コンテキストに合った回答が得られるからです。
LLMOという新領域の誕生
この変化に対応するための新しい最適化領域が生まれました。それがLLMO。Large Language Model Optimizationです。
LLMOとは、ChatGPT、Claude、Gemini、Perplexityといった大規模言語モデル(LLM)の回答において、自分のコンテンツが参照・引用されるように最適化する技術です。
従来のSEOが「Googleの検索結果ページで上位に表示される」ことを目指していたのに対し、LLMOは「AIの回答の中で情報源として引用される」ことを目指します。
この違いは、エンジニアにとって根本的に重要です。
SEOでは、Googleのクローラーがサイトをインデックスし、アルゴリズムがランキングを決定します。最適化の対象は明確で、フィードバックループも(Search Consoleなどを通じて)比較的整備されています。
LLMOでは、状況がまったく異なります。
まず、LLMがどのようにコンテンツを「知る」のかが複雑です。学習データとして事前に取り込まれる経路、RAG(Retrieval-Augmented Generation)を通じてリアルタイムに検索される経路、そしてAIエージェントが独自に情報を取得する経路。少なくとも3つの経路が存在します(これについては第2章で詳しく解説します)。
次に、最適化の対象となる「検索エンジン」が1つではありません。ChatGPTはBing(将来的にはSearchGPT)を使い、ClaudeはBrave Searchを使い、GeminiはGoogle Searchを使います。プラットフォームごとに参照する検索インフラが異なるのです。
さらに、AIの回答は確率的です。同じ質問をしても、毎回同じソースが引用されるとは限りません。Temperature(ランダムネス)パラメータ、クエリ時刻、ユーザーの位置情報、モデルバージョンなどによって、回答とその引用元が変動します。
つまりLLMOは、SEOよりも本質的に複雑で、不確実で、マルチプラットフォームな最適化問題なのです。
用語整理: LLMO / GEO / AIO / AEO
ここで、この領域の用語を整理しておきましょう。まだ業界として統一された呼び方が確立していないため、複数の用語が並立しています。
LLMO(Large Language Model Optimization)
大規模言語モデルの回答で引用・参照されるためのコンテンツ最適化。本書ではこの用語をメインで使います。技術的に最も正確で、対象(LLM)が明確だからです。
GEO(Generative Engine Optimization)
生成AIエンジン全体への最適化。2024年にPrinceton大学の研究チームがKDD 2024で発表した論文で定義されました。学術的にはこの用語が標準です。海外のマーケティング業界でも主流になりつつあります。
ただし、日本では「GEO」で検索するとレンタルDVDの「ゲオ」が出てくるという問題があり、用語としての定着にハードルがあります。
AIO(Artificial Intelligence Optimization)
AI全般に対するコンテンツ・サイト構造の最適化。日本では比較的よく使われています。ただし「AI Overviews」(Googleの生成AI回答機能)の略称としても使われるため、文脈によって意味が変わる曖昧さがあります。
AEO(Answer Engine Optimization)
回答エンジン最適化。Google AI Overviews、Bing Copilot、Perplexityなど、AI搭載検索機能の「インスタントアンサー」に表示されることを目指す最適化です。GEOよりやや狭い概念で、「検索エンジンのAI回答機能」に焦点を当てています。
3層モデルでの整理
Jasper社のブログが提唱する3層モデルが、これらの関係を理解するのに便利です。
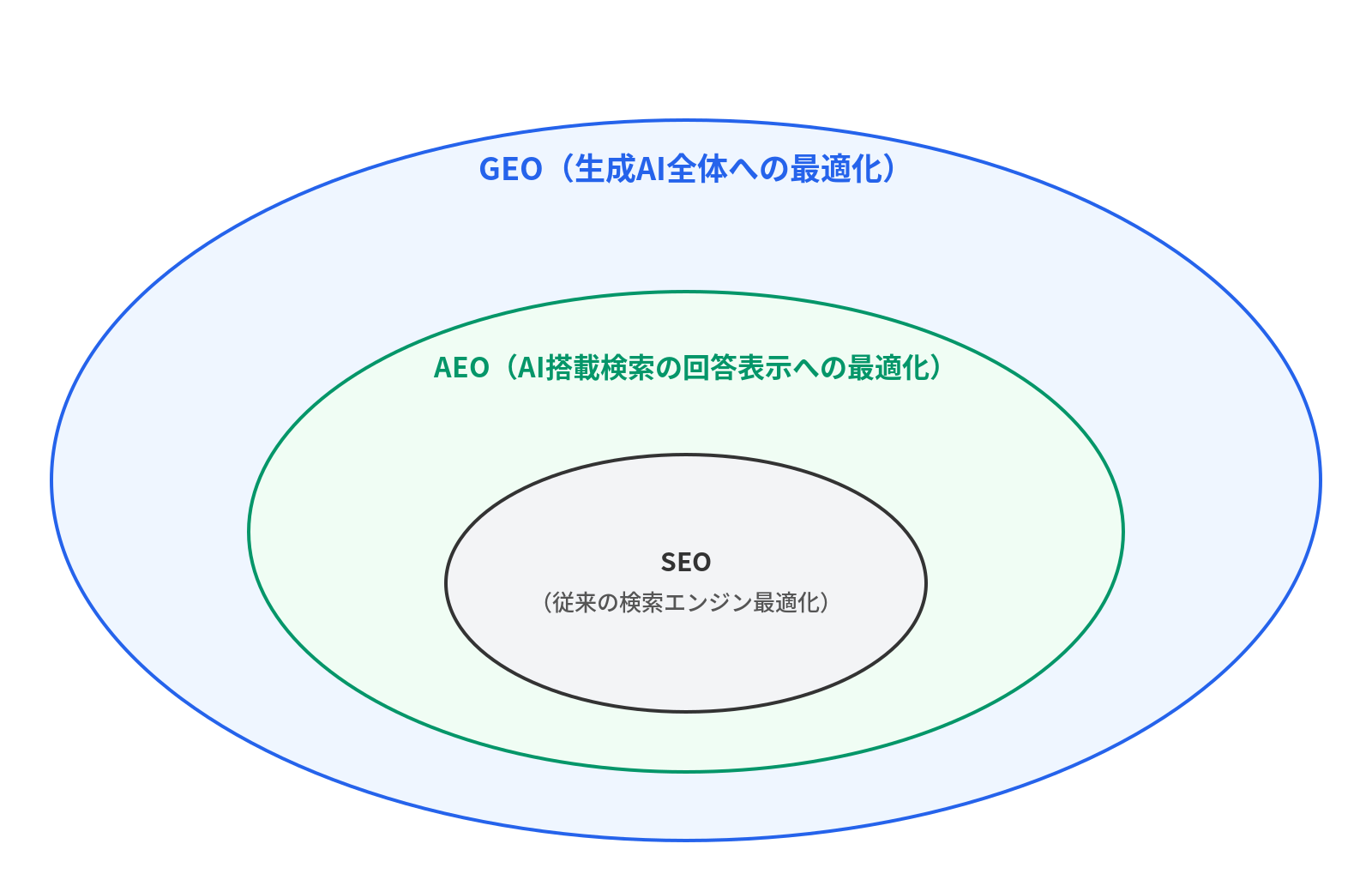
SEOが土台にあり、その上にAEOが、さらにその上にGEOが積み重なる構造です。重要なのは、 GEOやAEOはSEOを置き換えるものではない ということです。SEOの上に追加するレイヤーであり、SEOを捨ててGEOだけやるのは間違いです。
Semrushの調査データもこれを裏付けています。ChatGPTユーザーはGoogle検索を放棄していません。むしろAI利用が全体の検索行動を拡大しているのです。
本書では、技術的正確さの観点から「LLMO」を主に使いますが、文脈に応じてGEOやAEOも使い分けます。どの用語が出てきても、本質的には「AIの回答で自分のコンテンツが参照される」ための最適化を指していると理解してください。
なぜ今なのか。2025年が転換点である理由
「AIが検索を変える」という話は、数年前から言われていました。では、なぜ「今」が重要なのか。
2025年が転換点と言える具体的な理由があります。
第一に、 Bing Search APIの外部提供廃止 (2025年8月)。これにより、AIプロバイダーが利用可能な独立系検索APIが事実上Brave Searchだけになりました。検索バックエンドの多様性が一気に失われ、Brave最適化の重要性が急上昇しています。
第二に、 AIエージェント市場の爆発的成長。OpenClawのようなエージェントフレームワーク、Cursor・Windsurf等のAIコーディングアシスタント、企業内のカスタムAIエージェント。これらが日常業務に組み込まれ始めています。エージェントはユーザーの代わりに情報を検索し、判断材料を集めます。人間がGoogleを開かなくても、AIがWeb検索を実行する時代が来ています。
第三に、 Apple Intelligenceの展開。iPhoneにAI機能が標準搭載されることで、モバイルユーザーの検索行動が大きく変わる可能性があります。世界で10億台以上のiPhoneが、デフォルトでAI検索を提供するようになれば、インパクトは計り知れません。
これらの変化が2025年に同時に起きている。これこそが、今LLMOに取り組むべき理由です。SEOだけで戦い続けるのは、スマホ時代にFAXで営業するようなものです。機能はする。しかし、届く先が限られる。
エンジニアにとってのLLMO
ここまで読んで、「これはマーケターの仕事では?」と思った方もいるかもしれません。
違います。LLMOは本質的にエンジニアリングの問題です。
従来のSEOは、コンテンツ企画やキーワードリサーチといったマーケティング的な要素が大きく、技術的な実装(構造化データ、Core Web Vitals、サイトアーキテクチャ)はその一部でした。
LLMOでは、技術の比重がはるかに大きくなります。
- LLMがどのように情報を取得し、処理し、回答を生成するかのアーキテクチャ理解
- RAGシステムのクエリ展開(Query Fan-out)を意識したコンテンツ構造設計
- JSON-LDによる構造化データの実装
llms.txtやrobots.txtによるAIクローラー制御- Brave Search API、Google Search Grounding、Bing APIといった検索基盤の違いの理解
- AI可視性の測定自動化(Pythonスクリプトによるモニタリング)
これらは、マーケターではなくエンジニアのスキルセットに属する仕事です。
さらに言えば、私たちエンジニアは、LLMOの「当事者」でもあります。
Gemini CLIを使ってコードを書くとき、Claude Codeで技術調査をするとき、Perplexityでライブラリの比較をするとき。私たちはAI検索の「ユーザー」です。同時に、技術ブログやOSSドキュメントを書くとき、APIリファレンスを整備するとき。私たちはAI検索の「コンテンツ提供者」でもあります。
両方の立場を持つエンジニアこそが、LLMOの実態を最もよく理解できるし、最も効果的に実践できるのです。
SEOは死なない、でも変わる
最後に、大切なことを強調しておきます。
SEOは死にません。
Googleの検索シェアは依然として90%です。大半のユーザーは、まだGoogleで検索しています。AI経由のトラフィックは急成長していますが、全体の1%未満です(Ahrefs調査)。
しかし、その1%未満のトラフィックが持つ質は、桁違いに高い。
Ahrefsの調査では、LLM経由の訪問者のコンバージョン率がオーガニック検索の 最大23倍 に達するケースが報告されています(AI検索からの訪問が全体の0.5%なのに、サインアップの12.1%を占めた)。SimilarWebのグローバルECデータでも、AI経由のコンバージョン率は 11.4% に対しオーガニック検索は 5.3% と、約2倍の差がついています。Semrushのデータでは、LLMからの訪問者の平均コンバージョン率は従来検索トラフィックの 4.4倍 です。
量は少ないが質が圧倒的に高い。これがAI検索トラフィックの特徴です。
そして、この「量」は、毎年数百パーセントの勢いで増加しています。Gartnerの予測通り2026年に従来検索が25%減少するなら、そのトラフィックの多くはAI経由に流れることになります。
エンジニアとして、技術ブログやOSSプロジェクトの可視性を気にするなら、今からLLMOに取り組む価値は十分にあります。SEOを捨てる必要はありません。SEOの上にLLMOを積む。それが、これからのWebにおける情報発信の基本戦略です。
本書は、そのための実践的なガイドです。LLMの内部メカニズムから逆算し、エンジニアの視点で、何をどう最適化すればよいのかを解説していきます。
次の第2章では、LLMに情報が届く3つの経路。学習データ、RAG、AIエージェントのリアルタイム検索。を技術的に掘り下げます。
Key Takeaways
- AIエージェントはGoogleではなくBrave Searchで検索している 。SEO対策の前提が崩れている
- ユーザーの情報取得行動が「10本の青いリンク」から「1つのAI回答」へ不可逆的にシフト している。2026年までに従来検索トラフィック25%減(Gartner予測)
- LLMO/GEO/AIO/AEOは同じ現象を指す異なる名前。本質は「AIの回答で自分のコンテンツが引用される」ための最適化
- SEOは死なないが、SEOだけでは不十分。SEOの上にLLMOを積むハイブリッド戦略が必要
- LLMOは本質的にエンジニアリングの問題。LLMアーキテクチャ、RAG、構造化データ、クローラー制御。技術的な理解が不可欠
03 LLMに情報が届く3つの経路
第2章: LLMに情報が届く3つの経路
ChatGPTに聞いたとき、あなたのサイトが出ない理由。
あなたが技術ブログを書いたとします。SEO対策も施し、Googleで上位に表示されている。しかし、ChatGPTに関連する質問をしても、あなたの記事は一切引用されない。
なぜか。
答えは単純です。LLMがあなたのコンテンツを「知る」経路と、Googleがあなたのコンテンツをインデックスする経路は、まったく異なるからです。
この章では、LLMに情報が届く3つの経路を技術的に解剖します。各経路の仕組みを理解することが、LLMO戦略の出発点になります。
ここで、図書館のたとえを使って全体像を掴んでおきましょう。
SEOは、図書館の目録にあなたの本を正しく登録することです。一方LLMOは、司書(AI)がお客さんに「この本がおすすめですよ」と薦めてくれる状態を作ることです。目録に載っていても、司書が知らなければ薦められません。
LLMに情報が届く3つの経路は、司書の情報源に対応します。学習データは司書が過去に読んだ本の記憶。RAGはその場で棚を探すこと。エージェント検索は隣の図書館まで走って調べに行くことです。
3つの経路の全体像
LLMがコンテンツを「知る」経路は、大きく3つに分類できます。

それぞれ、情報が届くまでの時間スケール、最適化の手法、そして効果の持続性がまったく違います。順に見ていきましょう。
経路1: 学習データ: 長期戦
LLMの「記憶」の正体
GPT-4o/o3やClaude Sonnet 4/4.5といった最新のLLMは、膨大なテキストデータで事前学習(pre-training)されています。この学習データに含まれた情報が、モデルのパラメータにエンコードされ、いわばLLMの「記憶」になります。
ユーザーが「ReactのuseEffectの使い方を教えて」と聞いたとき、LLMが学習データの中で読んだReactのドキュメントやブログ記事の知識を使って回答を生成します。この場合、回答にソースの引用は付きません。LLMの「記憶」から直接出力されるからです。
GPT-3の学習データ構成
LLMの学習データがどのようなソースから構成されているかを具体的に見てみましょう。GPT-3の学習データ構成はOpenAIの論文(“Language Models are Few-Shot Learners”, 2020, Table 2.2)で公開されており、その後のモデルもおおむね似た構造を踏襲しています。
| データソース | トークンシェア | 学習ウェイト |
|---|---|---|
| CommonCrawl | 80%以上 | 60%(削減) |
| WebText2 | 少量 | 約22%(6倍に増加) |
| Books | 少量 | 約8%(増加) |
| Wikipedia | 少量 | 約3%(5倍に増加) |
ここで注目すべきは、 トークンシェアと学習ウェイトの乖離 です。
CommonCrawlはデータ量こそ最大ですが、学習ウェイトは60%に抑えられています。一方、WikipediaとWebText2は、データ量に対して学習ウェイトが5〜6倍に引き上げられています。
つまり、LLMの学習において、 すべてのWebページが平等に扱われているわけではない のです。品質が高いと判断されたソースには、より大きな重みが与えられます。
各データソースへの影響経路
CommonCrawl
Webの広範なクロールデータです。あなたのWebサイトがCCBot(CommonCrawlのクローラー)にブロックされていなければ、収集対象になります。ただし、サニタイゼーション(品質フィルタリング)の工程で除外される可能性もあります。
技術的には最もハードルが低い経路ですが、学習ウェイトが抑えられているため、ここに入っただけでは大きな影響力を持ちません。
Wikipedia(学習ウェイト5倍)
ほぼすべてのLLMが、Wikipediaに特別な重みを与えています。半構造化されたコンテンツ、厳格なモデレーション、多言語対応、セマンティックなクロスリンク。LLMの学習データとして理想的な特性を持っているからです。
実務上の示唆は明確です。あなたのプロダクトや技術がWikipediaの記事で言及されていれば、LLMの「記憶」に刻まれる確率が大幅に上がります。ただし、Wikipedia編集はその難しさで知られています。ノータビリティ(特筆性)の基準を満たさなければ記事は削除されますし、宣伝的な編集は逆効果になるリスクがあります。
WebText2(学習ウェイト6倍)
これはあまり知られていませんが、極めて重要なデータソースです。
WebText2は、 Redditで3つ以上のupvoteを受けた投稿に含まれるアウトバウンドリンクのページ をスクレイピングして構築されたデータセットです。
つまり、Redditコミュニティが「価値がある」と判断したコンテンツが、6倍の学習ウェイトでLLMに取り込まれているのです。
これは、技術系コンテンツにとって非常に重要な示唆を持ちます。あなたの技術ブログがRedditのr/programmingやr/javascriptでシェアされ、upvoteを獲得すれば、将来のLLMの学習データに高い重みで取り込まれる可能性があるということです。
カットオフの壁
学習データ経路の最大の制約は、 カットオフ日 です。
LLMの学習データには明確な期限があります。たとえばGPT-4oの学習データは2024年10月まで、Claude Sonnet 4.5は2025年4月までです(いずれも執筆時点。モデルのバージョンにより異なります)。カットオフ以降に公開されたコンテンツは、学習データには含まれません。
さらに、モデルの再学習は頻繁には行われません。GPT-3からGPT-4への更新に約3年かかっています。つまり、今日公開したコンテンツが学習データに反映されるのは、早くても数ヶ月後、一般的には1〜2年後です。
これが「長期戦」と呼ぶ理由です。学習データへの組み込みは、LLMOの中で最も時間がかかりますが、一度取り込まれれば、モデルの「記憶」として長期間持続します。
学習データ最適化の実践
学習データに取り込まれやすいコンテンツの共通特徴をまとめます。
- 権威あるドメインでの公開: 大手メディア(NYT、Bloomberg等)に掲載されたコンテンツは、CommonCrawl(直接)+ Wikipedia引用(間接)+ Reddit upvote(WebText2)の3経路で学習データに影響する
- Redditでの自然な共有: スパムではなく、コミュニティに価値を提供する形でリンクが共有されること
- Wikipediaでの言及: 信頼性の高い出典として引用されること
- 独自データの公開: 他では得られない一次情報は、引用・共有されやすく、結果的に学習データに入りやすい
経路2: RAG: 中期戦
RAGの仕組み
RAG(Retrieval-Augmented Generation)は、LLMが「記憶」にない情報を補完するために、リアルタイムでWeb検索を行い、取得した情報を基に回答を生成する仕組みです。
ChatGPTの「Browse with Bing」、PerplexityのWeb検索、Google AI OverviewsのSearch Grounding。これらはすべてRAGの実装です。
RAGの基本的な処理フローは以下の通りです。
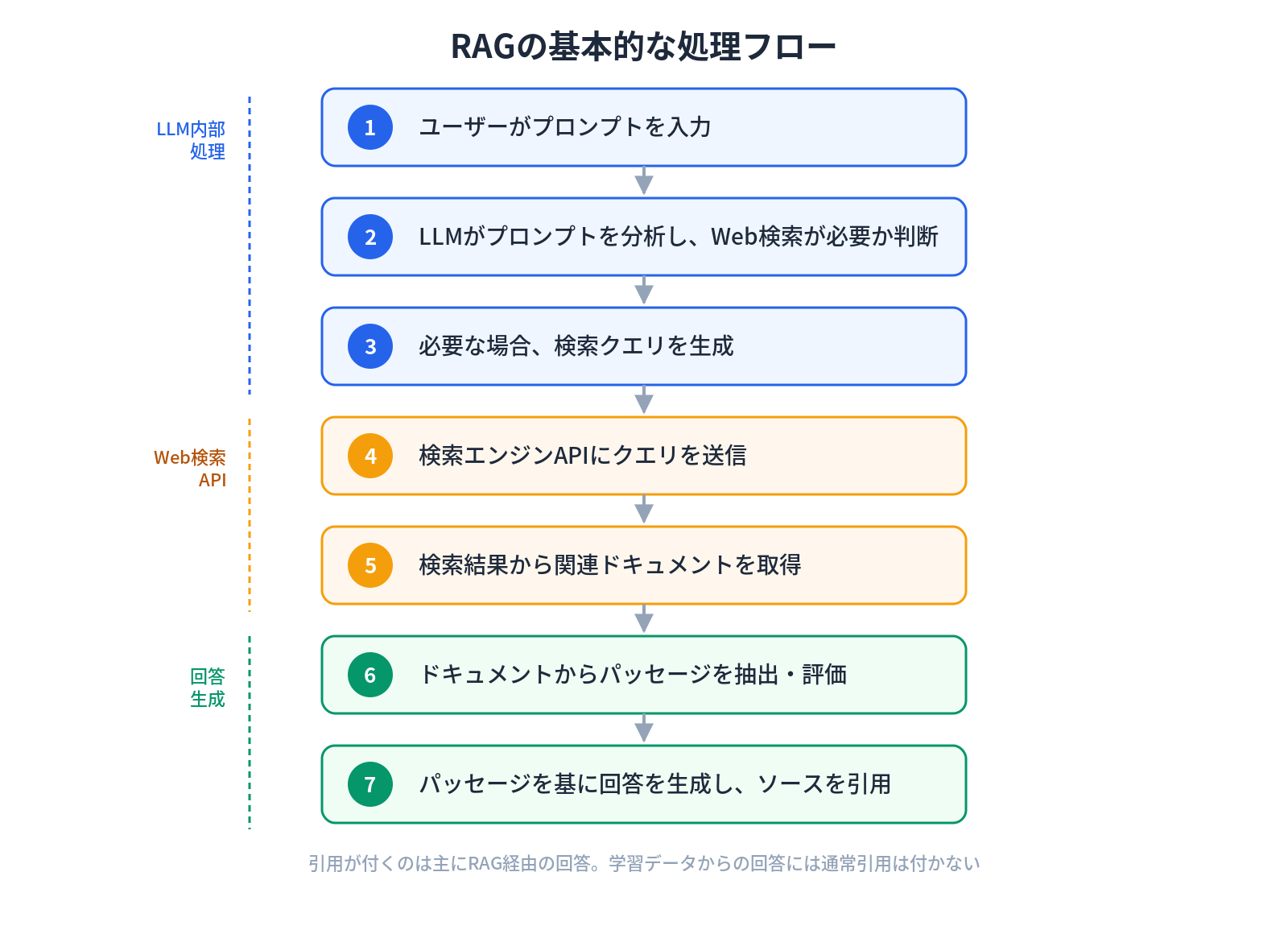
引用が付くのは、主にRAG経由の回答です。 学習データからの回答には通常、引用は付きません。つまり、「AIに引用される」ことを目指すLLMOにおいて、RAGは最も直接的なターゲットとなる経路です。
Query Fan-out: 1つの質問が複数の検索になる
RAGの中で、LLMOにとって最も重要な概念が Query Fan-out です。
ユーザーが「HubSpotをスタートアップで使うべき?」と聞いたとき、RAGシステムは内部でこの質問を複数のサブクエリに分解します。
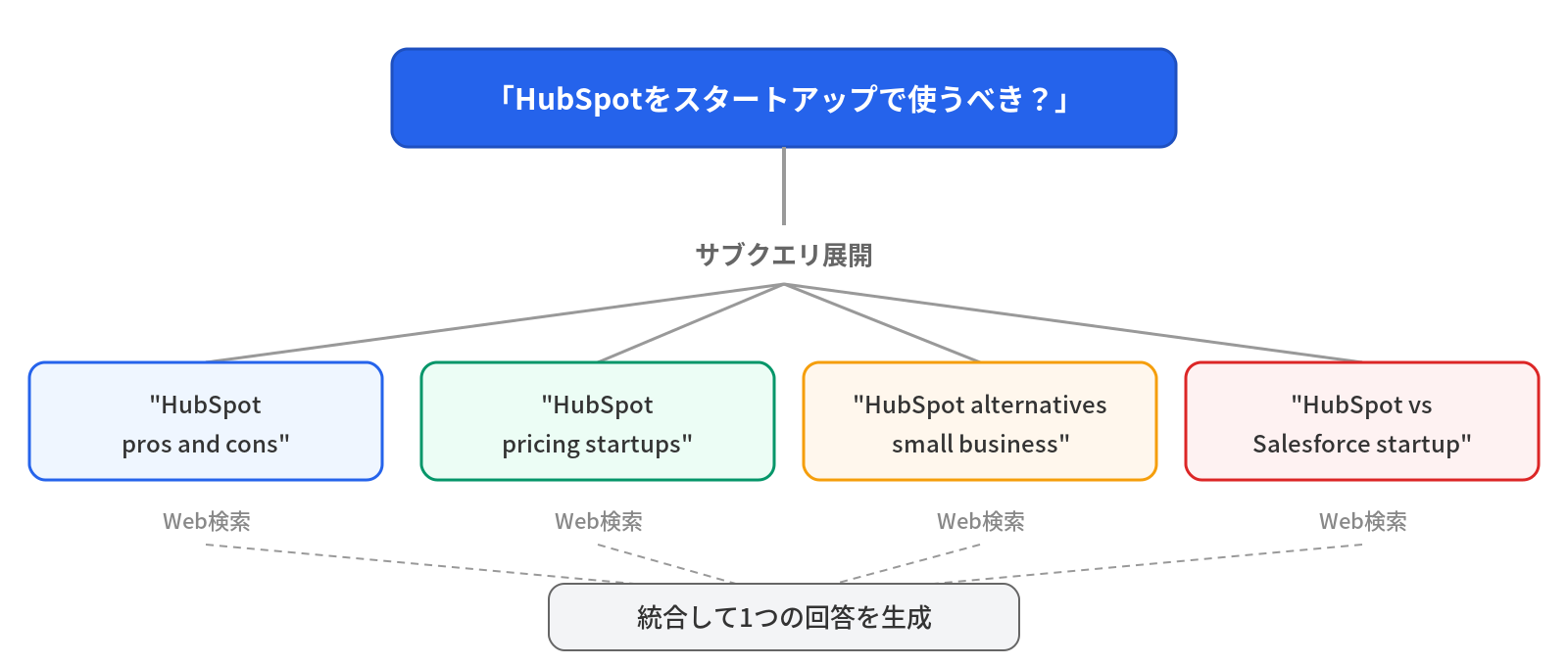
各サブクエリが独立してWeb検索を実行し、それぞれの検索結果からパッセージが抽出されます。最終的に、これらのパッセージを統合して1つの回答が生成されます。
SurferSEOの分析データが、この仕組みの実務的なインパクトを示しています。
- サブクエリでランクイン → メインクエリのみよりも 49%引用されやすい
- メインクエリ+サブクエリの両方でランクイン → 161%引用されやすい
つまり、コンテンツを設計する段階で、「AIがこのトピックに対してどんなサブクエリを生成するか」を想定し、各サブクエリに回答するセクションを含めることが重要なのです。
パッセージレベルの最適化
もう一つ、RAG経路の最適化で理解すべき重要な概念があります。
LLMは、ページ全体ではなく パッセージ単位(段落・セクション)でコンテンツを評価し、引用します。
SurferSEOの分析によると、 67.82%のAI Overviews引用元がGoogle検索のTop 10に入っていません。つまり、ページ全体のSEOランキングが低くても、特定のパッセージが質問に的確に回答していれば、AIに引用される可能性があるのです。
逆に言えば、SEOで1位のページでも、回答が長文の中に埋もれていたり、曖昧な表現だったりすると、AIに引用されないことがあります。
パッセージレベルの最適化で意識すべきポイントは以下の通りです。
## 質問形式の見出し
[1〜2文で直接的な回答]
[補足説明、データ、根拠]各セクションを「自己完結的な回答」として設計する。見出しが質問になっていて、直後に端的な回答があり、その下に根拠やデータが続く構造です。
引用されるコンテンツの特徴
Ahrefsが約6万サイトを分析して明らかにした、LLMに引用されやすいコンテンツの構造的特徴があります。
1. 新鮮さ(Freshness)
AIアシスタントはオーガニック検索結果より 25.7%新しいコンテンツ を優先します(Ahrefs調査)。Perplexityでは新鮮さがランキング要因の約 40% を占めます。
ただし、日付だけ変更してテキストを更新しない「偽の新鮮さ」はAIに検出されます。実質的なコンテンツの更新が必要です。
2. ドメインオーソリティ
ChatGPTの引用上位1,000サイトを分析すると、 DR(Domain Rating)60以上のサイトが支配的 です。LLMが直接DRを評価しているわけではありませんが、RAGで使う検索エンジンのランキングにDRが影響するため、間接的に効いてきます。
3. 独自データ
他のサイトにない一次情報。自社調査データ、実験結果、ベンチマーク。を含むコンテンツは引用されやすい。Ahrefsの最も引用されるページが「How Much Does SEO Cost?」(自社調査データに基づく記事)であることが、これを裏付けています。
4. 構造化されたフォーマット
明確な見出し、箇条書き、テーブル、番号リスト。AIがパッセージを抽出しやすい構造です。Microsoftも公式ガイドで「明確な意味、一貫した文脈、クリーンなフォーマット」を推奨しています。
引用とトラフィックは別物
ここで、ひとつ重要な注意点があります。
Ahrefsの分析によると、 最も引用されるページ上位1,000件のうち、ChatGPTからのトラフィック上位ページにも入っているのはわずか10% です。
引用されることとトラフィックが来ることは、必ずしもイコールではありません。AIがあなたの記事の情報を引用しつつ、ユーザーにはその情報を回答の中に統合して提示するため、ユーザーがわざわざ元記事をクリックしないケースも多いのです。
しかし、引用にはトラフィック以上の価値があります。LLM経由のトラフィックは量こそ少ないものの、コンバージョン率がオーガニック検索の 4.4倍 (Semrush)から 最大23倍 (Ahrefs)に達します。そして、AIが「この情報源は信頼に値する」と繰り返し引用すること自体が、ブランドの権威を構築します。
経路3: AIエージェントのリアルタイム検索: 即効性
ここからが、本書の独自の視点です。
学習データ(経路1)とRAG(経路2)は、多くのLLMO関連書籍で解説されています。しかし、 第3の経路。AIエージェントのリアルタイム検索行動。に踏み込んだ解説は、ほとんどありません。
これは、私自身がAIエージェントの開発・運用を通じて日常的に観察している現象です。
AIエージェントはBrave APIで検索する
第1章で触れた通り、私のAIエージェント(OpenClaw上のIris)はBrave Search APIで情報を取得しています。
しかしこれは私のエージェントだけの話ではありません。2024年から2025年にかけて、AIエージェント市場が急成長する中で、Brave Searchは事実上のデフォルト検索バックエンドになりました。
なぜBraveなのか。
理由は主に3つです。
- API提供の安定性: 2025年8月にMicrosoftがBing Search APIの外部提供を廃止したことで、独立系の検索APIはBraveが事実上唯一の選択肢になりました
- Zero Data Retention(ZDR): Brave Search APIは検索クエリを一切保存しないポリシーを持っています。AIプロバイダーにとって、ユーザーのクエリがサードパーティに蓄積されないことは重要なプライバシー要件です
- LLM Context API: Braveは2026年2月に、AI向けに最適化された新しいAPIをリリースしました。HTMLを構造化データに変換し、JSON-LDやテーブル行レベルまで分解した「スマートチャンク」を返すAPIです
この第3の経路がLLMO的に重要なのは、 Googleの検索インデックスとBraveの検索インデックスが異なる からです。
Googleで1位のページが、Braveでは5ページ目かもしれません。逆に、Googleで埋もれているページが、Braveでは上位に来ることもあります。Brave Searchは独自のインデックス(300億ページ、日次1億ページ更新)を持ち、Web Discovery Projectというユーザー行動ベースの自然なインデックス構築を行っています。
つまり、AIエージェント経由のトラフィックを獲得したいなら、Google SEOだけでなく、 Brave Searchでの可視性 も確保する必要があるのです。
Gemini CLIでRedditの技術情報を参照する日常
私の日常的なワークフローの一つに、Gemini CLIの利用があります。
Gemini CLIは、Google社が提供するコマンドライン版Geminiで、Google Search Groundingを内蔵しています。技術的な質問をすると、自動的にGoogle検索を実行し、その結果を基に回答を生成します。
面白いのは、Geminiの回答のソースをよく見ると、 Redditの技術スレッドが頻繁に引用されている ことです。
「Next.js 15のApp Routerでキャッシュが効かない」といった実務的な問題をGemini CLIに聞くと、Stack Overflowの回答よりも、Redditのr/nextjsのスレッドのほうが引用されることがあります。これは、Google SearchがRedditを高く評価するようになったこと(2024年のReddit IPO以降のデータ契約も一因でしょう)と、Redditのスレッドが実務的な質問に対する生の回答を含んでいることの、両方が理由と考えられます。
エンジニアとして認識すべきは、 自分がGemini CLIやChatGPTを使って技術調査をするとき、その回答のソースとなっている「情報の経路」が、従来の検索とは異なる ということです。
Claude in ChromeでXの情報を取得する
もう一つ、私が日常的に目にしている現象があります。
ChromeブラウザでClaude(Claude in Chrome拡張機能)を使うと、ブラウザのセッション情報を利用して、ログインが必要なサービスの情報も取得できます。
具体的には、X(旧Twitter)のタイムラインを開いた状態でClaudeに質問すると、タイムライン上の投稿内容を参照して回答を生成します。
これは厳密にはRAGとは異なるメカニズムです。Web検索APIを叩いているのではなく、 ブラウザのDOM(Document Object Model)を直接読み取っている のです。つまり、「検索エンジン」を経由せずに、「ブラウザ」を通じて直接Webの情報を取得しています。
この行動パターンは、AIエージェントの進化とともに、ますます一般的になるでしょう。MCP(Model Context Protocol)を通じたツール連携、Webブラウジングによるリアルタイム情報取得、さらにはAPIを直接叩く情報収集。AIが情報を取得する手段は、「検索エンジン」に限定されなくなりつつあります。
「検索エンジン」から「情報取得メソッド」へ
従来のSEOは、「検索エンジン」に最適化する技術でした。対象はGoogleという単一のプラットフォームで、そのインデックスとアルゴリズムに対して最適化すればよかった。
AIエージェント時代のLLMOは、「情報取得メソッド」全体に対する最適化です。
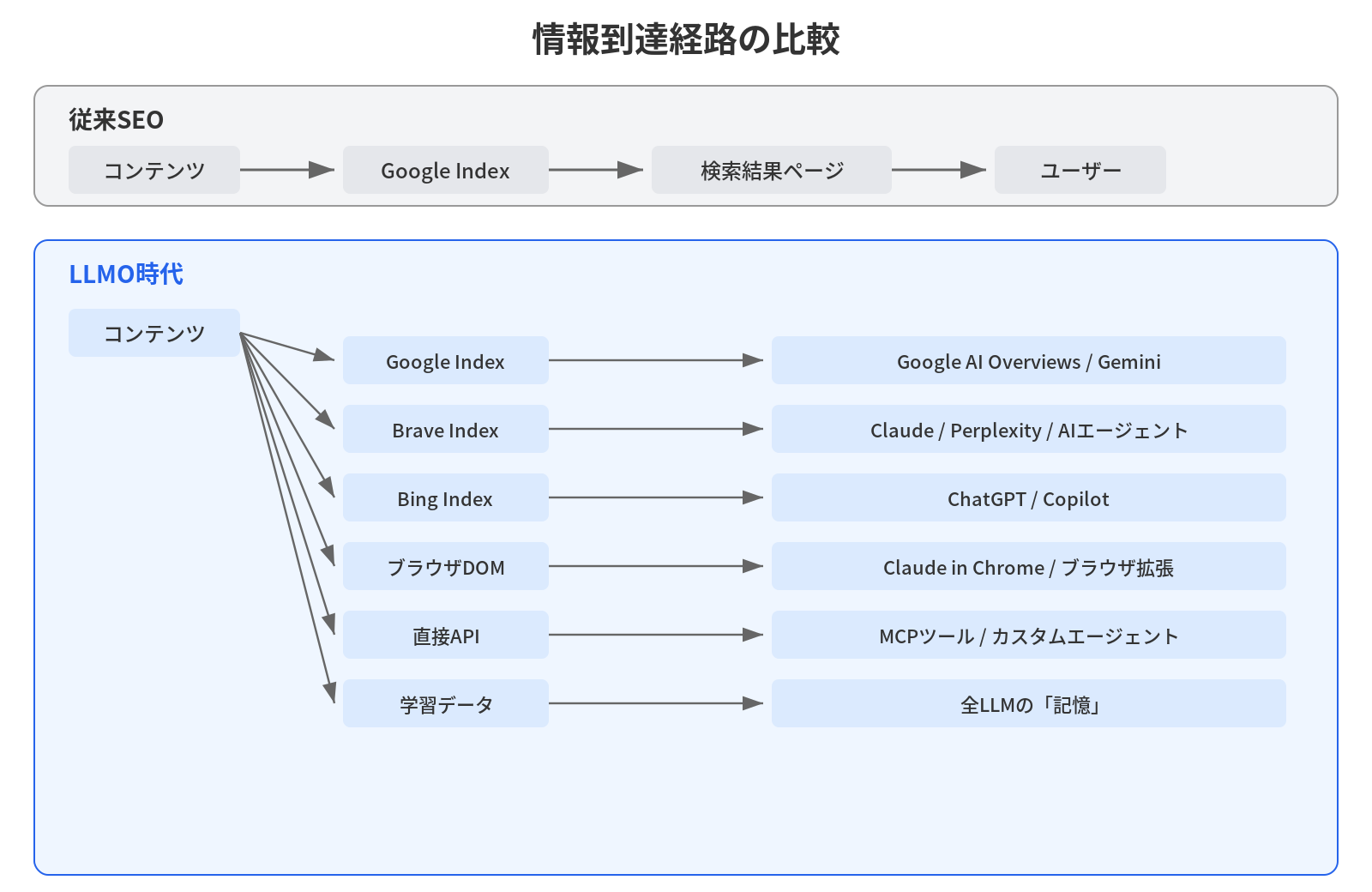
コンテンツが情報の消費者(人間またはAI)に届く経路が、劇的に多様化しているのです。
3経路の最適化優先順位フレームワーク
3つの経路を理解したところで、実務的な問いに答えましょう。 どの経路の最適化を優先すべきか。
これは、あなたの目的とタイムラインによって異なります。
即効性を求めるなら: 経路2(RAG)と経路3(エージェント検索)
すでに公開済みのコンテンツがあるなら、まずRAGとエージェント検索からの引用を狙うのが効率的です。コンテンツの構造を改善し(見出し、リスト、テーブル)、パッセージレベルで「質問に直接回答する」形に整えるだけで、AIからの引用率は上がります。
具体的なアクション:
- 各記事に構造化データ(JSON-LD)を追加する
- 見出しを質問形式にし、直後に端的な回答を配置する
- 独自データ・統計を明記する(「当社の調査では〜」のように)
- コンテンツを四半期ごとに更新し、新鮮さを維持する
中長期で投資するなら: 経路1(学習データ)
独自データの公開、権威あるメディアでの記事掲載、Redditコミュニティでの自然なプレゼンス構築、Wikipedia上での存在感。これらは時間がかかりますが、一度達成されれば、LLMの「記憶」として持続的に効果を発揮します。
具体的なアクション:
- 業界の調査レポートやベンチマークデータを定期的に公開する
- 技術カンファレンスでの発表内容を記事化する
- OSSプロジェクトのドキュメントを充実させる
- 技術記事をRedditやHacker Newsで自然にシェアする(スパムは厳禁)
AIエージェント時代に備えるなら: 経路3(エージェント検索)
Brave Searchでの可視性を確認し、llms.txt を整備し、AIクローラーに適切にアクセスを許可する。さらに、構造化データを充実させてBrave LLM Context APIでの抽出精度を上げる。
具体的なアクション:
- Brave Searchで自社の主要キーワードを検索し、現状の可視性を確認する
robots.txtでAIクローラー(GPTBot、ClaudeBot、Applebot-Extended等)を適切に許可するllms.txtを作成し、AIがサイトのコンテンツを効率的に理解できるようにする- JSON-LD構造化データを実装する(Brave LLM Context APIがJSON-LDを優先抽出する)
優先順位マトリクス
| 条件 | 優先経路 | 期待効果が出るまで |
|---|---|---|
| 既存コンテンツが豊富 | 経路2(RAG最適化) | 1〜3ヶ月 |
| 新規コンテンツ計画中 | 経路2 + 経路3 | 3〜6ヶ月 |
| ブランド認知を高めたい | 経路1(学習データ) | 6ヶ月〜2年 |
| 技術ツール・OSSを運営 | 経路3(エージェント検索) | 1〜3ヶ月 |
| すべてやりたい | 経路2 → 経路3 → 経路1 | 段階的に |
重要なのは、 3つの経路は排他的ではない ということです。RAG最適化のためにコンテンツ構造を改善すれば、それはエージェント検索経路にも効きます。独自データを公開すれば、RAGでの引用率が上がると同時に、将来の学習データにも取り込まれやすくなります。
最も効率が良いのは、 経路2(RAG)の最適化を起点に、経路3(エージェント検索)と経路1(学習データ)に波及させる アプローチです。
LLMが検索を実行するタイミング
最後に、そもそもLLMがWeb検索(RAGやエージェント検索)を「実行する」タイミングについて整理しておきます。
LLMは常にWeb検索を行うわけではありません。以下の条件に該当する場合に、検索が発動します。
- 最新情報が必要な場合: 時事ニュース、現在の価格、最新のリリース情報
- 学習データにないトピック: ニッチな技術、新しいライブラリ、最近のセキュリティ脆弱性
- 統計やデータの要求: 具体的な数値、市場調査、ベンチマーク結果
- YMYL(Your Money or Your Life)トピック: 医療、金融、法律に関する情報(正確性が求められるため)
- ユーザーの明示的要求: 「最新の情報を検索して」「Webで調べて」といった指示
逆に言えば、 LLMが学習データだけで自信を持って回答できる一般的な質問 については、Web検索は実行されず、引用も付きません。
このことは、LLMO戦略に重要な示唆を与えます。
あなたのコンテンツが「最新の独自データ」「ニッチな専門知識」「具体的な統計」を含んでいれば、LLMがWeb検索を実行する確率が高まり、あなたのコンテンツが引用される機会が増えるのです。汎用的な知識を繰り返すだけのコンテンツは、LLMが検索を実行する動機がないため、引用の機会自体が生まれません。
次の第3章では、AIエージェントのデフォルト検索エンジンとなったBrave Searchについて、そのアーキテクチャとLLMOにおける意味を深掘りします。
Key Takeaways
- LLMに情報が届く経路は3つ: 学習データ(長期戦)、RAG(中期戦)、AIエージェントのリアルタイム検索(即効性)
- 学習データの重みは均等ではない: WikipediaとWebText2(Redditリンク由来)は学習ウェイトが5〜6倍。Redditでの自然なプレゼンスが将来のLLM「記憶」に影響する
- RAGではQuery Fan-outとパッセージ単位の最適化が鍵: AIは1つの質問を複数サブクエリに展開し、ページ全体ではなく段落単位でコンテンツを評価・引用する
- AIエージェントはGoogle以外の検索エンジンを使う: Brave Searchが事実上のデフォルト。Google SEOだけでは、AIエージェント経由の可視性を確保できない
- 最適化の起点はRAG(経路2): コンテンツ構造の改善から始め、エージェント検索対応と学習データ投資に波及させるのが効率的
本書の概要
Google SEO だけでは ChatGPT / Perplexity に届かない。LLMO (LLM Optimization = AI検索最適化) の考え方と実装パターンを、構造化データ・llms.txt・JSON-LD・引用率最適化まで体系的に解説。AI検索時代に「拾われるサイト」を作るための実践書。
この本でできるようになること
- LLMO (LLM Optimization) の基礎概念と Google SEO との違いを理解できる
- llms.txt と JSON-LD を実装してAI検索エンジンに拾われやすくできる
- ChatGPT / Perplexity / Brave の引用ロジックを理解して逆算設計できる
- AI引用率を測定する KPI を設計できる
- 実例ケーススタディから自社サイトの改善点を抽出できる
対象読者
- 【ウェブ担当者】ChatGPT/Perplexityで自社サイトが出てこない悩みを抱える人
- 【マーケター】Google SEO の次のレイヤーを掴みたい人
- 【テックブログ運営者】記事のAI引用率を上げたい人
- 【プロダクトマネージャー】AI検索時代のSEO戦略を立てたい人
- 【LLMO初心者】用語と概念を体系的に学びたい人
この本で解決できる悩み
- ChatGPT検索で、自社サイトが全く出てこない
- Perplexity の引用元に入りたいが、何を最適化すれば良いか不明
- llms.txt とは何か、必要なのか判断できない
- Google SEO で稼いだ評価が、AI検索では評価されない
- AI引用率を測定する方法が分からない
- Schema.org / JSON-LD の実装が機能しているか自信が無い
この本の立ち位置
- 実装重視 (構造化データ・llms.txt の具体記述例)
- 中級者向け (HTML/SEOの基礎は前提、AI検索時代の上乗せ)
- Google SEO 卒業者向け (SEO は知っている前提でLLMOを体系化)
- 横断比較 (ChatGPT / Perplexity / Brave の挙動差を扱う)
なぜこの本か
- 「LLMO」という用語を体系化した最初期の本
- llms.txt の実装パターンと検証結果を含む
- AI引用率という新しいKPI設計を提示
- ChatGPT / Perplexity / Brave 各社の引用挙動を比較
- Schema.org JSON-LD の具体記述例を多数収録
他のAI本との違い
| 比較対象 | 本書の違い |
|---|---|
| Google SEO 解説書 | Google SEO の延長ではなく、AI検索エンジン向けの最適化に特化。 |
| AI / LLM 入門書 | 技術論ではなく、AI検索エンジンに拾われるサイト作りの実装書。 |
| ChatGPT 活用本 | ChatGPTを「使う側」ではなく、「使われる側 (引用される側)」になる方法。 |
目次
- 01 はじめに — なぜLLMOなのか 無料公開
- 1-1 本書の背景
- 1-2 本書の目的
- 1-3 対象読者
- 1-4 本書の読み方
- 1-5 本書で使用する環境
- 02 AI検索エンジンの仕組み 無料公開
- 03 Google SEO と LLMO の違い 無料公開
- 04 llms.txt の設計と実装
- 05 JSON-LD / Schema.org 実装パターン
- 06 コンテンツ最適化
- 07 引用率を上げる構造化
- 08 ChatGPT 引用ロジック
- 09 Perplexity 引用ロジック
- 10 Brave Search の挙動
- 11 AI引用率 KPI 設計
- 12 実例ケーススタディ
- 13 未来編
- 14 おわりに
Google SEO で1位を取っても、ChatGPT は引用してくれません。AI検索エンジンが見ているのは、Google のランキングシグナルとは別の世界です。
本書はその別世界の地図、LLMO (LLM Optimization) を、llms.txt / JSON-LD / 構造化データ / 引用率 KPI まで実装レベルで扱います。
「Google に1位 ≠ ChatGPT に引用される。」
シリーズ・関連書籍


Kindleで購入する
Kindle Unlimited 対象
Kindleで読む (¥1,000)※ 本ページにはAmazonアソシエイトリンクが含まれます。クリック先での購入により著者に紹介料が入る場合があります。