Por qué dejé el prompt engineering por la ingeniería de contexto
Hace más o menos un año, yo estaba convencido de que la habilidad del futuro era escribir mejores prompts. Estudié plantillas, compré dos cursos, anoté frases mágicas tipo “think step by step” y “you are a senior engineer with 20 years of experience”. Resultado: códigos un poco mejores, pero nada que justificara el tiempo gastado reescribiendo el mismo prompt cinco veces al día.
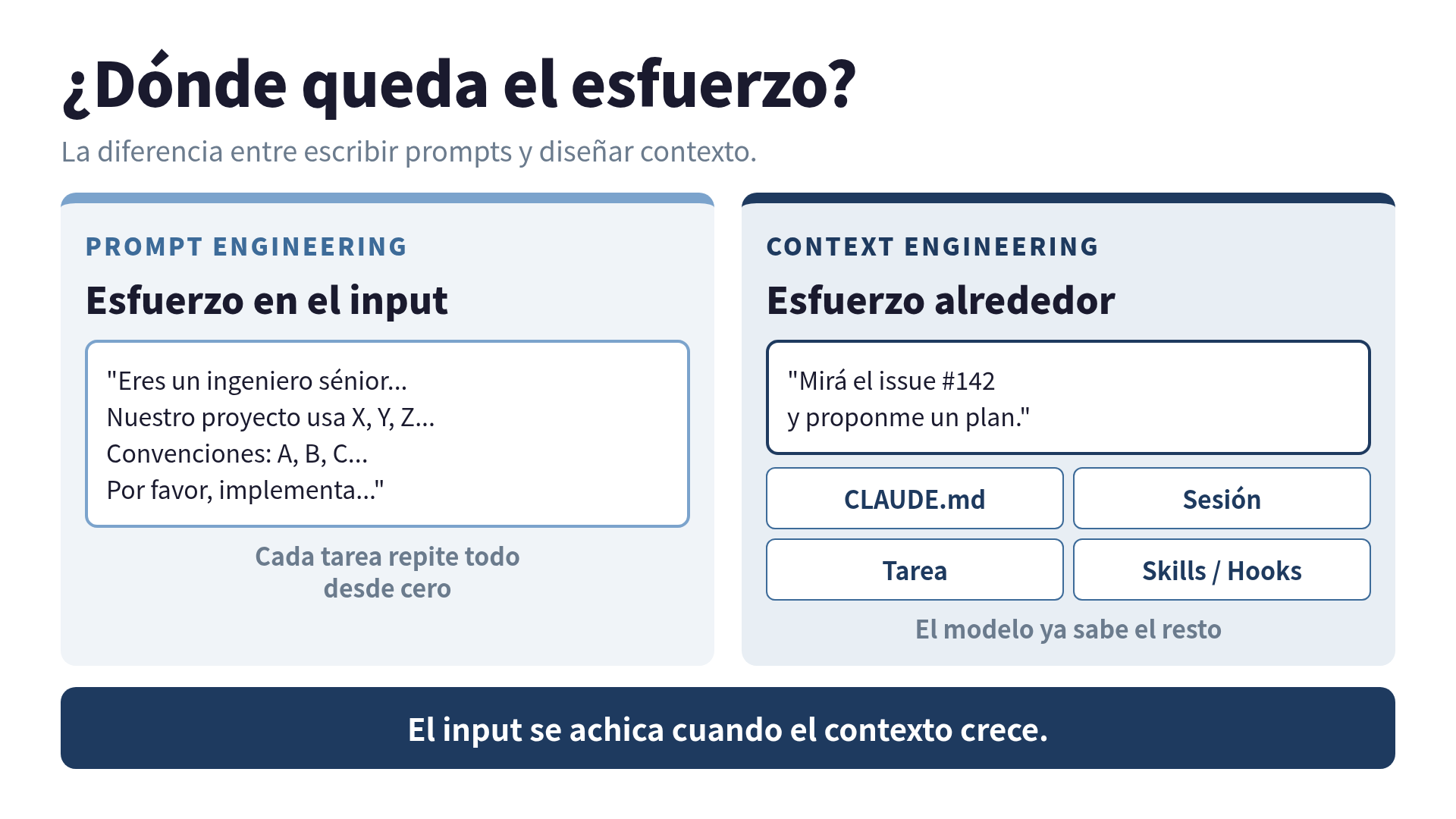
Hoy corro cinco proyectos en paralelo con Claude Code. Ya no escribo prompts largos. Lo que cambió fue la percepción de dónde debe ir el esfuerzo: no en el input que mando ahora, sino en el contexto que el modelo ya tiene antes de que yo abra la boca.
Este texto es sobre ese giro. El nombre tiene rótulo: ingeniería de contexto.
El problema del prompt engineering
La idea central del prompt engineering es simple: si formulo bien la pregunta, el modelo responde mejor. Y eso es verdad hasta cierto punto.
El problema aparece cuando tratas de escalar. Cada tarea exige un prompt distinto. Cada prompt necesita repetir convenciones del proyecto, restricciones de estilo, decisiones arquitecturales que ya fueron tomadas. Terminas manteniendo decenas de “prompts maestros” en archivos de texto, copiando y pegando, y aun así el modelo olvida cosas básicas en la mitad de la sesión.
Yo le llamo a eso economía del prompt único: cada interacción comienza desde cero, y todo el peso recae en lo que logras empacar en ese mensaje. Es como contratar a un sénior nuevo para cada PR y explicarle el proyecto entero antes de pedirle cada cambio.
El giro
En algún momento me di cuenta de algo: el modelo no necesita leer todo de nuevo cada vez. Si pongo la información correcta en el lugar correcto, él la encuentra solo.
Fue ahí donde empecé a pensar en capas de contexto. En vez de un prompt gigante, ahora diseño cuatro tipos de contexto que coexisten:
1. Contexto persistente (CLAUDE.md): convenciones del proyecto, decisiones arquitecturales, comandos de build, “por qué esto está así”. Este archivo vive en el repositorio y se lee automáticamente cada vez que Claude Code abre el proyecto. No tengo que repetir nada de eso en el prompt.
2. Contexto de sesión: lo que está abierto en el editor, historial reciente de la conversación, archivos que fueron leídos. El modelo ya tiene eso en la ventana de contexto.
3. Contexto de tarea: solo lo que es específico de ese pedido. “Implementa autenticación con JWT” en vez de “implementa autenticación con JWT siguiendo nuestro patrón de error centralizado en utils/errors.ts y usando bcrypt para hash de contraseña como descrito en CLAUDE.md”.
4. Contexto de herramienta: Skills, hooks, MCP servers. Capacidades que el modelo invoca cuando necesita, sin que yo se las pida.

La diferencia práctica: mi prompt típico hoy tiene tres líneas. El modelo ya sabe el resto.
Qué entra en el CLAUDE.md
Ese es el truco. CLAUDE.md es como un README escrito para el modelo, no para humanos. Responde preguntas que Claude haría si pudiera:
- ¿Cómo correr los tests en este proyecto?
- ¿Cuál es el estilo de error? Throw, return tuple, Result type?
- ¿Hay alguna decisión arquitectural no obvia que yo deba respetar?
- ¿Qué comandos debería evitar? (drop database, force push, etc.)
- ¿Dónde está la documentación de dominio que explica el “por qué” de las cosas?
Mi CLAUDE.md de uno de los proyectos tiene 180 líneas. Cubre estructura de carpetas, comandos de prueba, patrones de commit, tres decisiones arquitecturales con explicación corta, y una sección de “comportamientos a evitar”. Ese archivo me ahorra cinco minutos por interacción. Multiplica por 50 interacciones al día en cinco proyectos: ahorro real de tiempo.
CLAUDE.md como contrato
Hay un detalle que me costó entender: CLAUDE.md no es solo una lista de reglas. Es un contrato bidireccional.
De mi lado, prometo mantener el archivo actualizado cuando cambian las decisiones. Del lado del modelo, se compromete a respetar lo que está escrito ahí. Eso cambia el tipo de feedback que recibo: si hace algo fuera del patrón, ahora reclamo apuntando al fragmento específico de CLAUDE.md. El modelo acepta mejor una corrección anclada en “violaste la regla X” que en “esto está mal”.
Otro lado: si hace algo bien siguiendo el contexto, dejo de elogiar. No necesito. Está haciendo su trabajo.
Mi flujo típico
Te cuento cómo funciona una mañana mía, para que quede concreto.
Despierto, abro uno de los proyectos en la terminal. Claude Code carga el CLAUDE.md. Mando: “mirá el issue #142 y proponme un plan en 4 o 5 etapas.”
El modelo lee el issue, lee los archivos relevantes, y me devuelve un plan en markdown con 4 o 5 etapas. Reviso el plan (no el código todavía), corrijo una decisión si es necesario, y digo “ejecuta.”
Mientras tanto, abro el segundo proyecto y hago lo mismo. Después el tercero. Los tres modelos trabajan en paralelo, cada uno en su repositorio, cada uno con su CLAUDE.md.
Cuando el primero termina, vuelvo, leo el diff, hago review. Aquí es donde el humano agrega valor: juzgar si lo que se hizo tiene sentido en el contexto mayor del producto. El modelo escribe código, yo decido si ese código entra o no.
En un día bueno, cierro 8 a 12 PRs así. En un día malo, descubro que debería haber actualizado el CLAUDE.md de un proyecto antes de empezar. Siempre es mi culpa: el modelo solo sabe lo que dejé escrito.
Lo que dejé de hacer
Algunas cosas dejaron de existir en mi flujo:
- Prompts con más de 5 líneas
- “Eres un ingeniero sénior…” y compañía
- Re-explicar la estructura del proyecto
- Repetir convenciones de naming
- Pedirle al modelo que “recuerde” algo de la conversación anterior
- Cursores múltiples en el IDE (la terminal ganó)
Algunas empezaron:
- Actualizar CLAUDE.md como hábito (igual que actualizar README)
- Pensar en Skills reutilizables para tareas que repito
- Configurar hooks para automatizar verificaciones
- Discutir decisiones con el modelo antes de pedir código
Adónde te lleva esto
Si estás hoy en la fase de “escribir mejores prompts”, el siguiente paso probable es dejar de escribir prompts y empezar a escribir contexto. CLAUDE.md es el punto de entrada más barato. 30 minutos invertidos en el archivo suelen ahorrar horas en la semana siguiente.
Junté lo que aprendí en estos meses en un libro llamado Practical Claude Code: La Ingeniería de Contexto que Transforma tu Desarrollo, enfocado en ingeniería de contexto aplicada. Cubre CLAUDE.md, Skills, hooks, multi-agente, y los tropiezos que vale la pena evitar. Está en Kindle Unlimited.
Pero no necesitas el libro para empezar. Abre tu proyecto ahora, crea un CLAUDE.md con cinco líneas sobre cómo correr los tests y cuál es el patrón de error. Mira lo que cambia en la siguiente sesión. Suele ser obvio.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?