Por qué tu sistema multi-agente no escala: la arquitectura de memoria decide el techo (25 agentes contra 1.000.000)
Te confieso el error que cometí y que probablemente vas a cometer también: cuando armé mi primer sistema de varios agentes, a la pregunta de “¿cómo van a recordar lo que pasó?” respondí con la opción más cómoda del mundo. Que se guarden todo el historial de conversación, dije, total el modelo es listo y ya verá qué usa. Funcionó de maravilla con tres agentes. Con quince empezó a arrastrarse. Con cincuenta ya era impagable. Lo que yo creía un detalle de implementación resultó ser la decisión que me había puesto un techo, y yo mismo lo había clavado sin darme cuenta.
Aclaro de entrada de qué trata esto, porque ya escribí antes sobre simulación de agentes y no quiero que se confunda. Aquel artículo iba de no confiar en un solo número cuando un simulador te da una predicción, sobre usar la distribución y no la estimación puntual. Esto es otra cosa: va de la arquitectura de memoria y de cómo esa elección fija, de manera física, cuántos agentes puedes llegar a ejecutar. Es un problema de cimientos, y ningún ajuste de prompt lo resuelve.
La misma idea, dos techos separados por cuatro ceros
Voy a poner los dos extremos sobre la mesa y después explico por qué pasa.
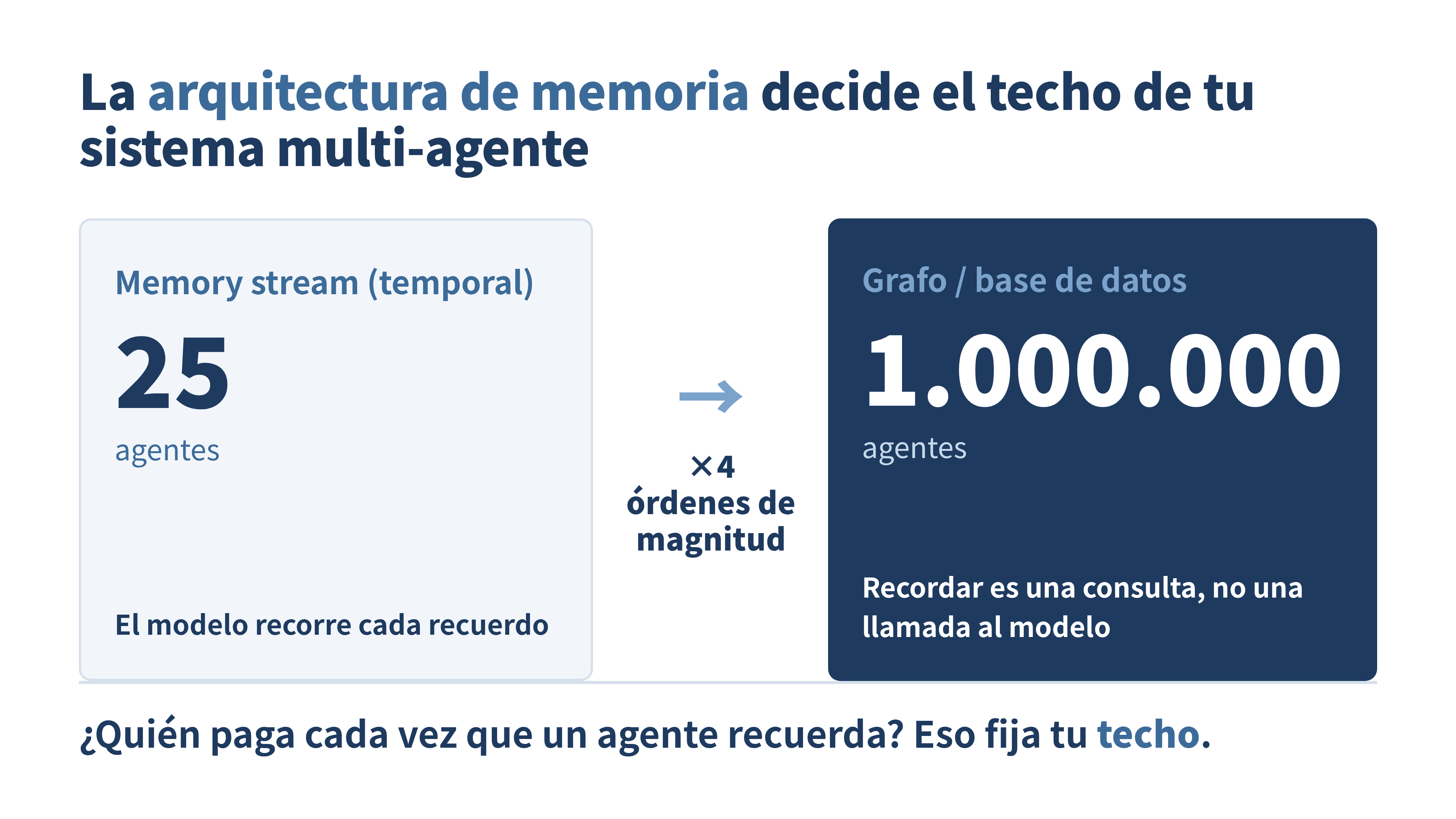
En un extremo está Generative Agents, el proyecto de Stanford que simuló un pueblito con habitantes de IA que se despertaban, desayunaban e iban a trabajar. Su mecanismo de memoria es el memory stream: cada experiencia se anota como un evento en una corriente cronológica, y cuando el agente necesita decidir algo, recupera recuerdos puntuándolos por tres criterios, recencia, importancia y relevancia. Es elegante y es muy humano. También tiene un techo: el sistema está diseñado para unos 25 agentes. Cada agente llama al modelo en cada paso, así que el costo crece con la cantidad de agentes y la corriente de recuerdos se vuelve cara de recorrer.
En el otro extremo está OASIS, una simulación de redes sociales que llegó a un millón de agentes. Su memoria no es una corriente cronológica que el modelo lee; son las acciones de los agentes guardadas en una base de datos SQLite, con un sistema de recomendación que filtra qué ve cada uno. Ningún agente necesita leer todo. La base de datos guarda, el recomendador filtra, y el modelo solo se invoca cuando hace falta.
Veinticinco contra un millón. Cuatro órdenes de magnitud. Y la idea de fondo, “agentes que actúan y recuerdan”, es la misma en los dos. Lo único que cambió fue dónde y cómo vive la memoria.
Por qué la forma de recordar pone el techo
La clave está en una pregunta incómoda: ¿quién paga cada vez que un agente recuerda?
En el memory stream, recordar significa que el modelo recorre la corriente de experiencias, las puntúa y elige. Eso es trabajo del modelo, y el trabajo del modelo cuesta dinero y tiempo en cada paso. Si cada uno de tus 25 agentes hace eso en cada turno, ya estás cómodo en el límite. Multiplica por 40 para llegar a mil y la cuenta se vuelve absurda. El memory stream es precioso para estudiar comportamiento humano con pocos agentes, y por eso Generative Agents y Concordia viven en el rango de decenas. No fue un descuido; fue el objetivo de diseño.
En la memoria de base de datos o de grafo, recordar es una consulta. La base de datos guarda el estado, un índice o un recomendador decide qué fragmento es relevante, y el modelo recibe solo ese pedazo. El costo de guardar no escala con el costo de pensar. Por eso OASIS puede tener un millón de habitantes: la mayoría de las “memorias” nunca tocan el modelo, viven en disco y se consultan como cualquier dato. Cambias llamadas al modelo por consultas a una base, y las consultas son baratas.
En el medio hay un espectro entero. MiroFish usa memoria en grafo (con Zep) y trabaja en el orden de cientos de agentes; el cuello de botella ahí es el costo de actualizar el grafo. AgentSociety maneja más de mil agentes pero necesita un entorno distribuido con GPU. La regla que se repite es clara: cuanto más trabajo de recordar le pasas al modelo, más bajo es tu techo; cuanto más lo mueves a una base de datos o un grafo, más alto sube.
| Proyecto | Tipo de memoria | Techo de agentes |
|---|---|---|
| Generative Agents | Memory stream (cronológico) | ~25 |
| Concordia | Memoria por componentes | decenas |
| MiroFish | Grafo (Zep) | cientos |
| AgentSociety | Atributos de red social | 1.000+ |
| OASIS | Base de datos (SQLite) | 1.000.000 |
Lo que el 2026 agregó a la conversación
Esto no es historia congelada; el campo se está moviendo rápido. En 2026 aparecieron arquitecturas de memoria pensadas justamente para subir el techo sin perder lo bueno del stream. Zep popularizó un grafo de conocimiento consciente del tiempo, con tres niveles, episódico, semántico y resúmenes de comunidad, que estructura los recuerdos en lugar de dejarlos como una corriente plana. Mem0 ataca el problema de mantener consistencia en conversaciones largas con una memoria de largo plazo escalable. Y en enero de 2026 salió MAGMA, una arquitectura de memoria basada en varios grafos. Hasta hay trabajo académico sobre estructuras de memoria adaptativas, que básicamente proponen elegir la forma de recordar según la tarea en lugar de casarte con una sola.
Lo que todos comparten es el reconocimiento de que la memoria monolítica, meter todo en un único almacén de largo plazo, es precisamente lo que no escala. El error que cometí al principio, “que se guarde todo el historial”, tiene nombre en la literatura ahora: memoria monolítica. Me hace sentir un poco mejor saber que mi mala decisión era lo bastante común como para merecer un término técnico.
Cómo elegir antes de chocar contra la pared
La parte práctica cabe en una pregunta que conviene hacerse el primer día, no el día que la factura asusta: ¿cuántos agentes voy a necesitar de verdad?
Si la respuesta son cinco o diez agentes ricos, con personalidad, que razonan a fondo sobre su pasado, el memory stream es la herramienta correcta y el techo no te va a molestar. No te compliques con grafos distribuidos para simular una oficina de seis personas. Si la respuesta son cientos o miles de agentes más simples, donde lo que importa es el comportamiento agregado y no el alma de cada uno, necesitas memoria en base de datos o en grafo desde el inicio, porque migrar de un stream a una base de datos con el sistema ya en marcha es de esas cirugías que uno posterga hasta que duele.
El punto que quiero que te lleves es incómodo por lo simple: la pregunta “¿cómo van a recordar mis agentes?” no es un detalle de implementación que resuelves al final. Es la decisión que fija tu techo, y la tomas quieras o no. Si no la eliges a conciencia, la eliges por descuido, y por descuido casi siempre sale el memory stream, que es lo que parece más natural. Yo elegí por descuido y me topé con la pared a los cincuenta agentes. Tú todavía estás a tiempo de elegir a propósito, que sale mucho más barato que elegir a los golpes.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?