
音声AIの300ms
人はなぜAIとの会話に違和感を覚えるのか
音声AI レイテンシ 設計 | Pipecat・LiveKit・Deepgram で525msの壁を突破
Zenn累計32,000+ views · 4言語で30冊以上出版 · Kindle 6カ国で販売中
📖 無料で読める章
買う前に3章をその場で読めます。気に入ったらKindleで続きを。
01 前書き: 0.3秒の壁

「こんにちは」
ユウはできるだけ自然に話しかけた。音声AIプロダクトの初回デモ。6ヶ月の開発期間を経て、ついに投資家の前でプレゼンする日が来た。
沈黙。
1秒。2秒。
「フリーズしました?」
投資家の表情が変わった瞬間を、ユウは忘れない。
AIはちゃんと答えた。「こんにちは、何かお手伝いできることはありますか?」音声合成も自然だった。レスポンスの内容も完璧だった。でも、遅すぎた。
その日の夜、オフィスに残ったユウの前にMacBookの画面があった。Googleスプレッドシートに計測結果が並んでいる。
1.8秒。2.1秒。1.9秒。
どのテストケースも、1.5秒を超えていた。
「これじゃ会話にならない」
独り言が、静かなオフィスに響いた。
その瞬間から、ユウの 300ms への挑戦が始まった。
本書は、音声AIエンジニア ユウとUXデザイナー ミサキが、人間らしい会話を実現するために戦った記録です。彼らが直面した問題は、単純でありながら根深いものでした。
本書の内容には、著者がWebRTCを用いたリアルタイム通信プロダクトの開発に長年携わり、さらにAIとの会話プロダクトを設計・構築した際に得た現場の知見を随所に盛り込んでいます。掲載している技術情報やベンダー比較は2026年3月時点の最新状況に基づいており、OpenAI Realtime API、Gemini Live API、Pipecat、LiveKitなど、音声AI領域で急速に進化するエコシステムの「今」を反映しています。
人間同士の会話では、相手が話し終わってから自分が話し始めるまでの沈黙は平均200ミリ秒しかありません。一方、現在の音声AIエージェントは700〜1000ミリ秒の沈黙を挟みます。人間の3〜5倍。この差が「違和感」の正体です。
本書では、ユウとミサキの軌跡を辿りながら、著者の実務経験と最新の技術動向を交えて、音声AIにおけるレイテンシを以下の観点から体系的に解説します。
- 人間の会話はどのくらいの速さで回っているのか (第1章)
- 何秒を超えると体験が崩壊するのか (第2〜4章)
- なぜ遅延が生まれるのか (第5〜6章)
- どうすれば速くできるのか (第7章)
- 速くできないとき、どう誤魔化すのか (第8章)
- 「遮らない」と「遅れない」をどう両立するのか (第9章)
- 既存の音声アシスタントから何を学べるか (第10章)
- エッジAIで300msの壁を越える方法 (第11章)
本書に登場する主な数字は以下の通りです。
| 閾値 | 意味 |
|---|---|
| 200ms | 人間の会話ターン間の平均沈黙 |
| 300ms | 音声AIで「自然な会話」が成立する上限 |
| 400ms | ドハティの閾値。操作と反応が連続的に感じられる限界 |
| 500ms | ユーザーが被せて話し始める閾値 |
| 800ms | 会話が崩壊する閾値 |
| 1.5秒 | 体験が急激に劣化するポイント |
| 4秒 | 体験品質が全面的に崩壊する閾値 |
0.3秒。たったそれだけの時間が、AIとの「対話」と「操作」の分かれ目になります。
ユウとミサキの物語は、技術的な挑戦であると同時に、人間らしさを再定義する旅でもありました。
本書がその壁を越えるための一助となれば幸いです。そして何より、これから音声AIに挑戦する皆さんが、同じ遠回りをしなくて済むことを願っています。
この続きはKindleで →02 第1章: 人間の会話は200msで回っている
ミサキがコーヒーカップを置く音が、静まり返ったオフィスに響いた。
「ユウ、提案があるんだけど」
前日のデモ失敗からまだ立ち直れずにいるユウを見かねて、ミサキは口を開いた。
「人間同士の会話を録音して分析してみない?AIと何が違うのか、数字で見てみよう」
「データがないと始まらないよね。今日の昼間、私たちの会話も録音させて」
世界共通の「間」
人間の会話には、ほぼ全世界共通のリズムがあります。
2009年、Max Planck Institute for Psycholinguisticsの研究チームは、10言語(英語、日本語、デンマーク語、オランダ語、イタリア語、韓国語、ラオ語、ツェルタル語、ユカテコ語、ǂĀkhoe Haiǁom語)を対象に、会話のターンテイキング(話者交代)のタイミングを調査しました。
結果は明確でした。 すべての言語で、話者交代時の沈黙は平均約200ミリ秒 です。
200ms。0.2秒。まばたきよりも短い時間です。
その日の夜、ユウが自分たちの会話を解析したとき、驚きとともに現実を受け入れざるを得なかった。「やっぱり200msだ。俺たちのAIは2秒。10倍遅い」
この研究が示しているのは、ターンテイキングのタイミングが文化によって大きく異なるのではなく、人間の認知処理能力に根ざした普遍的なパターンであるということです。
200msの意味
人間の平均的な反応時間は約220msです。つまり、会話のターン交代は人間の反応限界に近い速度で行われています。
しかし、ここで不思議なことがあります。相手の発話が終わってから200msで応答を開始するには、相手が話し終わる 前に 応答の準備を始めなければ間に合いません。
実際、研究者たちはこう結論づけています。人間は会話中、相手の発話内容を処理しながら、同時に次の発話を準備しているのです。つまり、 聞きながら考える という並列処理を行っています。これは第7章で解説するストリーミング設計の着想源でもあります。
「人間は並列処理してるのか」ユウが呟いた。「俺たちのAIは逐次処理。聞く、考える、話すを一個ずつやってる。そりゃ遅いわけだ」
これは音声AI設計における重要なヒントです。人間の会話はシリアル処理(聞く → 考える → 話す)ではなく、パイプライン処理なのです。
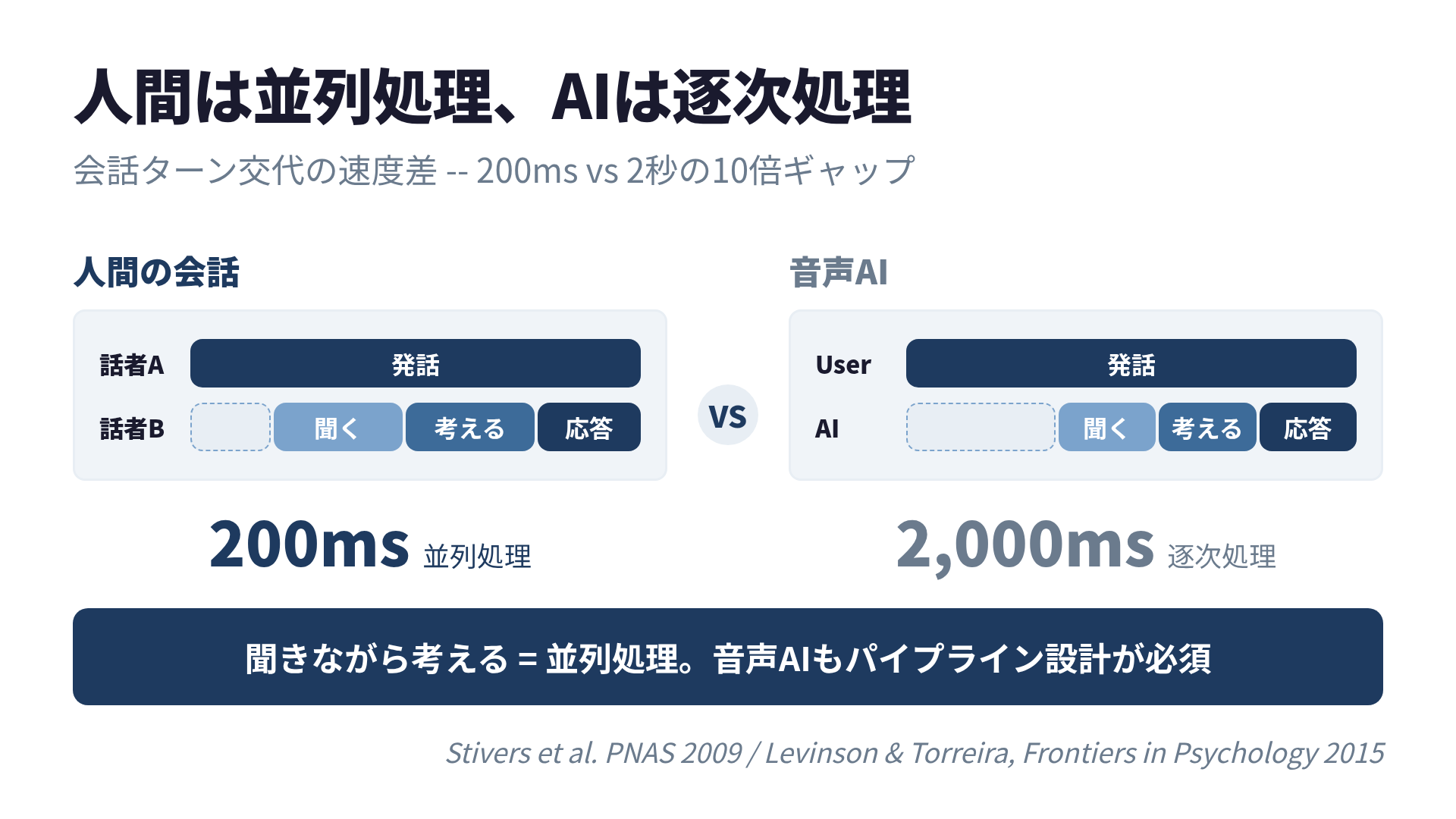 人間は「聞きながら考える」並列処理で200msを実現。AIは「終わってから考える」逐次処理で2秒かかる
人間は「聞きながら考える」並列処理で200msを実現。AIは「終わってから考える」逐次処理で2秒かかる
600msの「考えている」印象
200msが平均ですが、すべてのターン交代がこの速度で行われるわけではありません。
Speechmaticsの研究によると、人間の会話における典型的なポーズは約600ミリ秒です。この長さの沈黙は「考えている」「言葉を選んでいる」という印象を与え、むしろ丁寧で思慮深い印象を持たれます。
逆に、この600msを大きく超えると、聞き手は不安を感じ始めます。「聞こえていないのか?」「理解できなかったのか?」
| 沈黙の長さ | 聞き手の印象 |
|---|---|
| 0-200ms | 即座の応答。自然 |
| 200-600ms | 考えている。丁寧 |
| 600ms-1s | やや間がある。許容範囲 |
| 1-1.5s | 遅い。違和感 |
| 1.5s超 | 故障? フリーズ? |
音声AIへのインプリケーション
この研究から、音声AIの設計者が知るべきことは3つあります。
1. 200msは生物学的な限界値
人間の会話のリズムは、認知処理能力に基づいた普遍的なものです。音声AIが「自然な会話」を目指すなら、この200msに近づける必要があります。
2. 聞きながら考える設計が必須
人間が会話でやっているように、ユーザーの発話を処理しながら応答を準備するパイプライン設計が必要です。発話が完全に終わってから処理を開始する逐次処理では、間に合いません。
3. 600msまでは「人間らしさ」として使える
応答が200msで返せなくても、600msまでは「考えている」印象を活用できます。この時間をフィラー(「そうですね」「えーと」)で埋めることで、AIに人間らしさを持たせることが可能です。
翌朝、ミサキはユウのデスクに厚い論文の束を置いた。「Jakob Nielsenの論文見つけた。これ、ヤバいよ」
この続きはKindleで →参考文献
- Stivers, T. et al. “Universals and cultural variation in turn-taking in conversation.” PNAS, 2009.
- Speechmatics. “Your AI Assistant Keeps Cutting You Off. I’m Fixing That.” 2025.
03 第2章: Nielsenの3閾値を音声UIに翻訳する
朝9時のMTGルーム。ミサキは厚い論文をテーブルに広げていた。
「ユウ、Jakob Nielsenって知ってる?UX界の大御所よ。この論文、1993年のなんだけど、今でも通用する」
昨日の200msショックでまだ混乱しているユウの前に、ミサキは数字の表を示した。
「100ms、1秒、10秒の3つの壁がある。うちは1秒超えちゃってるから、“体験が途切れる”ゾーンにいる」
ユウが目を細めた。「これ、音声UIにも当てはまるの?」
「それを確かめたいの」
GUIの古典を音声に適用する
1993年、ヤコブ・ニールセンは「Usability Engineering」で、UIの応答時間に関する3つの閾値を定義しました。この法則は30年以上経った今でも、UXデザインの基礎として広く参照されています。
| 閾値 | GUI での意味 |
|---|---|
| 0.1秒(100ms) | 操作が瞬時に反映された感覚。直接操作している実感 |
| 1秒 | ユーザーの思考フローが維持される限界。遅延は感じるが集中は途切れない |
| 10秒 | ユーザーの注意が完全に離れる。タスク放棄のリスク |
これらの数字は、コンピュータの性能ではなく人間の認知特性に基づいています。そのため、1968年のMiller、1991年のCard、1993年のNielsenと、研究者が変わっても数字は変わっていません。
音声UIでは閾値が「縮む」
GUIでは1秒の遅延が許容されます。ユーザーは画面を見ながらローディングインジケーターを確認できるからです。
音声UIでは事情が異なります。
音声は「巻き戻し」ができません。
テキストチャットであれば、1秒待っても画面上に「入力中…」の表示があり、その間に前のメッセージを読み返すこともできます。音声には、そのような視覚的フィードバックがありません。沈黙は、ただの沈黙です。
「そうか」ユウが頷いた。「画面がないから、手がかりがない。音だけの世界は厳しいな」
そのため、音声UIでは各閾値が以下のように縮小されます。
| GUI | 音声UI | 理由 |
|---|---|---|
| 0.1秒 | 変わらず | 人間の認知限界は同じ |
| 1秒 | 300-500ms | 視覚フィードバックがないため、沈黙がより長く感じる |
| 10秒 | 4秒 | 音声は待っている間「何もできない」ため、注意がより早く離れる |
ACM CUI 2025の研究では、 4秒を超えるレイテンシは体験品質を著しく低下させる ことが実験的に確認されています。GUIの10秒に相当する閾値が、音声では4秒に縮むのです。
ミサキがホワイトボードに数字を書き出した。「目標が見えた」とユウが呟いた。「300msから500msの間で、何らかの反応を返す。それが音声UIの生命線だ」
ドハティの閾値 — もう1つの基準線
1982年、IBMのWalter DohertyとAhrvind Thadaniは、コンピュータの応答時間が0.4秒以内であれば、ユーザーの生産性が大幅に向上することを報告しました。これが「ドハティの閾値」です。
400ms以内の応答では、ユーザーは操作と反応を連続的な一つのアクションとして認識します。 「待っている」という意識が生まれない のです。この閾値の心理学的な背景は、第3章でさらに掘り下げます。
音声AIの文脈では、この400msはASR(音声認識)の処理時間として許容される上限と考えることができます。ユーザーが話し終わってから400ms以内に何らかの反応(フィラーでも可)が返れば、「聞こえている」という安心感を与えられます。
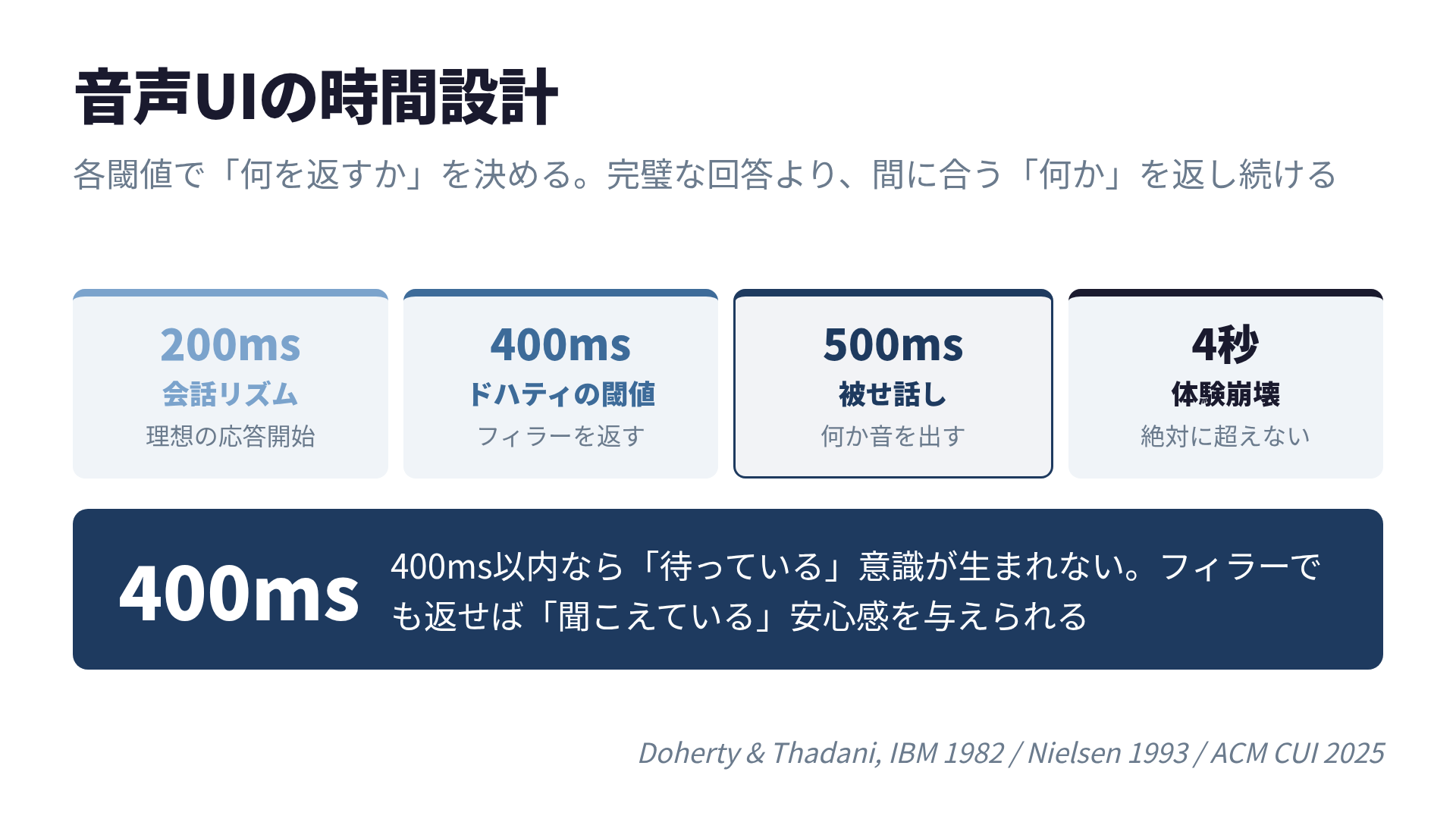 400ms以内に何らかの反応を返せば「待っている」意識が生まれない。音声AIの時間設計の全体像
400ms以内に何らかの反応を返せば「待っている」意識が生まれない。音声AIの時間設計の全体像
まとめ: 音声UIの時間設計
| 閾値 | 音声AIでの意味 | 設計指針 |
|---|---|---|
| 100ms | 瞬時の反応 | 音声入力の受信確認(ビープ音等) |
| 200ms | 人間の会話リズム | 理想的な応答開始タイミング |
| 400ms | ドハティの閾値 | フィラーか最初の音声を返す |
| 500ms | 被せ話し閾値 | ここまでに何か音を出す |
| 1秒 | フロー維持限界 | これを超えたら説明が必要 |
| 4秒 | 体験崩壊 | 絶対に超えてはならない |
音声AIの時間設計とは、これらの閾値を意識しながら「どの段階で、何を返すか」を決めることです。完璧な回答を待って全部返す設計では、ほぼ確実に1秒を超えます。
重要なのは、 完璧な回答を速く返す ことではなく、 各閾値に間に合う「何か」を返し続ける ことです。
「でも、理論だけじゃダメ」ミサキがペンを置いた。「実際にユーザーがどう感じるか、テストしてみよう」
この続きはKindleで →参考文献
- Nielsen, J. “Response Times: The 3 Important Limits.” Nielsen Norman Group, 1993/2024.
- Doherty, W. J. and Thadani, A. J. “The Economic Value of Rapid Response Time.” IBM Systems Journal, 1982.
- ACM CUI 2025. “Mitigating Response Delays in Free-Form Conversations with LLM-powered IVAs.”
本書の概要
音声AIの体験は『速さ』で9割決まる。人の会話ターンは平均200ms、300msを超えると違和感、800msを超えると会話が崩壊する。Pipecat・LiveKit・Deepgramの最新スタックで、カスケードパイプラインの525msの壁を、ストリーミング設計・知覚ハック・エッジAIで突破する方法を解説。
この本でできるようになること
- Nielsen のレスポンスタイム閾値を音声UXに翻訳して設計判断できるようになる
- カスケードパイプライン (STT → LLM → TTS) の各段で何msかかるか分解できる
- Pipecat / LiveKit / Deepgram を組み合わせて 300ms 未満の応答を実装できる
- ストリーミングTTS と知覚ハック (filler words 等) で体感速度を上げられる
- エッジAI (Whisper Tiny / Llama 1.5B 等) でクラウドラウンドトリップを削れる
対象読者
- 【音声AI開発者】カスケードパイプラインの遅延に悩んでいる人
- 【WebRTCエンジニア】既存のVoIP/SIP知見をAI音声に応用したい人
- 【UX設計者】会話の自然さを定量設計したい人
- 【スタートアップCTO】音声AI製品の競争優位を「速さ」で取りたい人
- 【リサーチ志向】Nielsen応答時間閾値・人間会話学・心理音響を融合したい人
この本で解決できる悩み
- 音声AIを実装したが「会話のキャッチボール感」が出ない
- TTFB を測ったらやけに遅いが、どこがボトルネックか分からない
- Pipecat と LiveKit と Deepgram、どれを選ぶべきか判断できない
- TTS のレイテンシが大きくて全体が崩れる
- エッジAIで音声処理したいが、現実的な構成が分からない
- ユーザーから「会話が機械的」と言われるが、改善の手がかりがない
この本の立ち位置
- 実装重視 (Pipecat / LiveKit / Deepgram の具体スタック)
- 音声特化 (チャットボットではなく対話型音声AIだけ)
- 中級者向け (WebRTC / TTS の基礎知識前提)
- 横断統合 (心理学・UX・実装・エッジAI を1冊で)
なぜこの本か
- 300ms / 500ms / 800ms の3つの崖を Nielsen 応答時間閾値ベースで定量化
- Pipecat・LiveKit・Deepgram の最新3スタックを比較して使い分け提示
- ストリーミング設計と知覚ハックを同時に扱う唯一のリソース
- エッジAI (Whisper Tiny / 量子化LLM) でクラウドゼロを目指す章を含む
- Zenn 12,000PV の解釈比較記事の発展版
他のAI本との違い
| 比較対象 | 本書の違い |
|---|---|
| 汎用AI実装書 | 音声特化。テキストチャットの遅延設計とは別レイヤーの問題を扱う。 |
| WebRTC / SIP 解説書 | 通信プロトコル中心ではなく、AI推論を含めたE2Eレイテンシ設計。 |
| ベンダー個別ドキュメント (Pipecat / LiveKit 等) | 1社視点ではなく、複数スタックを比較・組み合わせて使う設計知見。 |
目次
- 01 はじめに 無料公開
- 02 なぜ300msなのか — Nielsen の応答時間閾値 無料公開
- 2-1 世界共通の「間」
- 2-2 200msの意味
- 2-3 600msの「考えている」印象
- 2-4 音声AIへのインプリケーション
- 03 3つの崖 — 300ms / 500ms / 800ms 無料公開
- 3-1 GUIの古典を音声に適用する
- 3-2 音声UIでは閾値が「縮む」
- 3-3 ドハティの閾値 — もう1つの基準線
- 04 カスケードパイプライン分解 — STT / LLM / TTS
- 05 Pipecat による実装
- 06 LiveKit による実装
- 07 Deepgram + ストリーミング
- 08 Turn-taking 検出
- 09 Filler words と知覚ハック
- 10 ストリーミングTTS
- 11 エッジAI で TTFB を削る
- 12 音響的同期と心理
- 13 ベンチマーク設計
- 14 本番運用パターン
- 15 未来編
- 16 おわりに
- 17 参考文献
人と話していて、相手の返事が0.5秒遅れたら「あれ?」と思いますよね。AIと話していても同じ。むしろAI相手の方が、遅延を強く感じます。
人間の会話ターンは平均200ms。300msを超えた瞬間に違和感が始まり、800msを超えると会話そのものが崩壊する。本書ではその根拠を Nielsen の応答時間閾値で固めつつ、Pipecat / LiveKit / Deepgram の最新スタックを使ったE2E設計を、ストリーミング・知覚ハック・エッジAIまで扱います。
「速さは機能ではない。前提条件である。」
シリーズ・関連書籍

Kindleで購入する
Kindle Unlimited 対象
Kindleで読む (¥1,200)※ 本ページにはAmazonアソシエイトリンクが含まれます。クリック先での購入により著者に紹介料が入る場合があります。