Auditei 30 arquivos llms.txt em produção. 5 anti-padrões já estão se formando.
Subi meu terceiro llms.txt este mês e me senti injustamente produtivo. Aquele tipo de produtividade em que você fecha o laptop, toma um café e tem a cara de quem resolveu sozinho o problema de busca por IA.
Depois abri 30 arquivos llms.txt em produção das empresas que a gente cita quando quer convencer alguém de que “olha, os times sérios já fazem isso”. Anthropic. Stripe. Vercel. Cloudflare. Hugging Face. Mintlify. Astro. Linear.
24 dos 30 tinham pelo menos um de cinco problemas. Três desses problemas eu também tinha cometido.
O café esfriou.
Como auditei
A montagem foi vergonhosamente simples. Peguei 30 domínios com llms.txt público que importam para devs em 2026: labs de IA, infra, ferramentas para dev. Fiz curl em cada um. Li cada arquivo com a cabeça de um LLM tentando usar aquilo. Anotei o que estava ruim.
Não é ciência. É segunda à noite com o terminal aberto. Mas os padrões apareceram tão rápido que parei nos 30. Os próximos dez seriam mais do mesmo.
Para contexto: o estudo da SE Ranking com 300 mil domínios em março de 2026 encontrou cerca de 10% de adoção. O guia da codersera de maio de 2026 estima 844 mil sites com crescimento de 500% ao ano. A adoção está ganhando a corrida. A qualidade está perdendo.
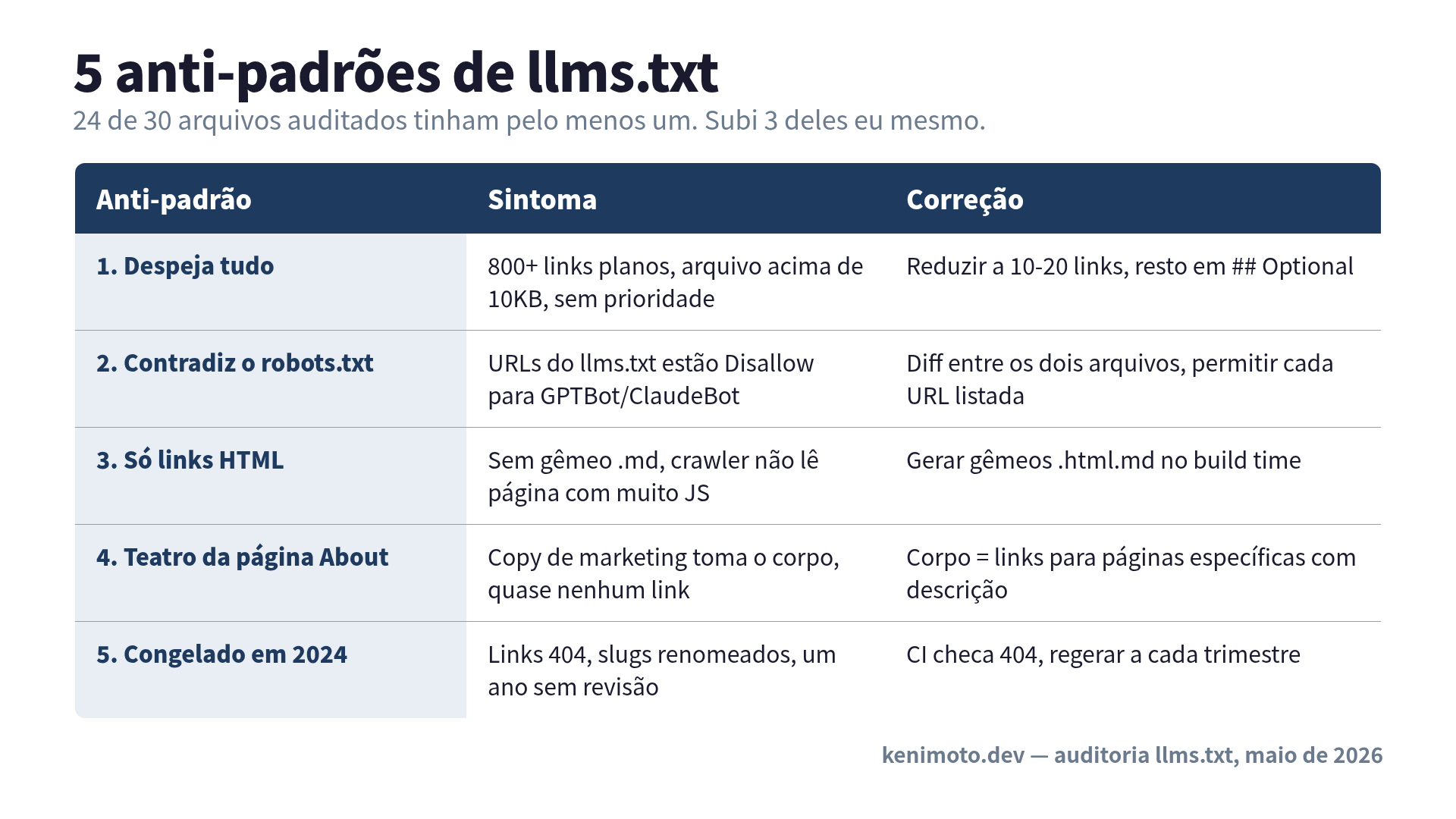
Os cinco anti-padrões
Anti-padrão 1: “Despeja tudo”
O mais comum, e o que eu mais cometi. O autor trata llms.txt como um segundo sitemap. 800 links. 1.200 links. Um arquivo que abri tinha todo post de blog desde 2019, plano, sem prioridade, sem agrupamento.
O ponto inteiro de llms.txt é que o sitemap.xml já faz isso. Quando a spec diz “10KB recomendado”, não está sendo fofa com tamanho de arquivo. Está dizendo: se o LLM não consegue ler o arquivo inteiro dentro de um context window com orçamento sobrando para a pergunta real, você não ajudou, você só mudou o problema de lugar.
A correção é brutal: escolha 10 a 20 links. Não 50. Não “seções principais mais alguns extras”. 10 a 20. Tudo o que sobrar vai para ## Optional ou fica no sitemap.xml.
Se você é um produto com muita documentação, use o padrão da Cloudflare: um llms.txt raiz enxuto que aponta para llms.txt por produto. Cada um cabe no orçamento. O agente busca só o que precisa. Ninguém lê a enciclopédia inteira para consertar uma torneira.
Anti-padrão 2: “Contradiz o robots.txt”
Abra o robots.txt. Abra o llms.txt. Compare os caminhos. Cerca de um terço dos arquivos que auditei listam URLs no llms.txt que estão explicitamente Disallow-ados no robots.txt para os crawlers que mais provavelmente leriam o llms.txt.
O exemplo mais doloroso: um site de documentação que bloqueia GPTBot e ClaudeBot de /docs/ no robots.txt, e depois lista 40 URLs de /docs/* no llms.txt. O arquivo diz “isso aqui importa”. O robots.txt diz “você não pode acessar”. O crawler obedece o robots.txt. O llms.txt é decoração.
Isso geralmente acontece quando os dois arquivos são mantidos por equipes diferentes (ou pela mesma pessoa em meses diferentes). A correção é uma revisão de cinco minutos com os dois arquivos abertos: cada URL no llms.txt precisa estar permitida no robots.txt para cada crawler de IA que você de fato quer lendo aquilo.
Se você genuinamente quer bloquear crawlers de IA, tudo bem, mas então não escreva também para eles um diretório educado das suas páginas favoritas.
Anti-padrão 3: “Só links HTML, sem .md”
A proposta original de Jeremy Howard inclui uma convenção esperta: qualquer URL com .md adicionado deve retornar uma versão Markdown limpa da página, sem nav, sem ads, sem bundle de JavaScript. O padrão .html.md.
Quase ninguém faz isso. Nos meus 30 arquivos, só 6 serviam algum companheiro .md. Os outros 24 entregam ao LLM um link para uma página HTML que o crawler não consegue parsear direito porque não executa JavaScript.
A Stripe faz isso direito: toda URL de docs tem um gêmeo .md e o llms.txt aponta para a versão .md. A seção Reference Templates do llmoframework.com marca isso como a coisa de maior alavancagem que a maioria dos times está pulando, porque é a diferença entre “a IA acha a página” e “a IA realmente lê o que está nela”.
A correção depende da sua stack. Em Astro e Next.js, gerar versões .md em build time são 30 linhas. Em CMS dinâmico, uma edge function que retorna serialização markdown no sufixo .md resolve. De qualquer jeito, é o anti-padrão com a maior diferença entre esforço e resultado.
Anti-padrão 4: “Teatro da página About”
Oito dos 30 arquivos usavam o corpo inteiro do arquivo como pitch de marketing. Três parágrafos sobre a missão da empresa. Uma citação do fundador. A história da marca. E aí dois links. Conteúdo total: “somos líderes visionários no espaço AI-native”.
LLMs não compram a sua vibe. Eles precisam de ponteiros para conteúdo. O H1 e o blockquote de resumo são o lugar para “o que é esse site”. Tudo abaixo deveria ser links para páginas específicas com descrições específicas. Se o seu llms.txt parece uma homepage, você escreveu uma homepage.
O estudo GEO de Princeton sobre os 9 jeitos de ser citado por IA bate na mesma tecla do lado do conteúdo: afirmações vagas não são citadas, afirmações específicas com fontes são. A mesma lógica vale para o próprio llms.txt.
Anti-padrão 5: “Congelado em 2024”
Cinco dos arquivos que auditei tinham sinais visíveis de terem sido subidos uma vez e nunca mais tocados. Links para páginas com 404. Nomes de produtos que não existem mais. Datas que colocam a última atualização significativa em 2024, época em que llms.txt era uma proposta de seis meses de idade e “busca por IA” ainda era algo que o Perplexity precisava explicar.
sitemap.xml é auto-gerado. robots.txt raramente muda. llms.txt mora num meio-termo estranho: curado à mão como documentação, mas com o mesmo risco de obsolescência de um README que diz “usamos Yarn” quando o time migrou para pnpm faz um ano.
A correção é automação, não disciplina. Adicione um check de CI que sinaliza 404 nas URLs que o seu llms.txt lista. Regere a seção de “artigos em destaque” a partir do analytics a cada trimestre. Trate o arquivo como artefato de config, não como entregável de lançamento.
A análise da Mintlify sobre exemplos reais de llms.txt marcou esse como o segundo padrão mais comum na base de clientes deles. O primeiro foi o Anti-padrão 1. Esses são os dois para arrumar essa semana.
Contexto brasileiro
Fiz curl em alguns domínios brasileiros também. globo.com não tem llms.txt (snapshot de maio de 2026). mercadolivre.com.br também não. nubank.com.br idem. magazineluiza.com.br idem. TabNews tem? Não na raiz, no momento da auditoria.
Isso pode ser lido de dois jeitos. “O Brasil está atrasado” é a leitura desanimada. “Quem subir um agora ainda pega vantagem de early adopter no mercado local” é a leitura construtiva. Eu fico com a segunda. No mercado brasileiro de produtos de software, llms.txt em maio de 2026 é praticamente terreno virgem.
Os três que eu mesmo subi
Seção da honestidade. Dos meus três llms.txt:
- Um tinha 47 links. Anti-padrão 1.
- Um apontava só para URLs HTML porque eu não tinha configurado o gêmeo
.mdainda. Anti-padrão 3. - Um estava sem atualização há 4 meses e listava um post com slug que eu já tinha renomeado. Anti-padrão 5 mais uma cadeia de 301 de sobremesa.
Eu não tinha notado nada disso até estar três quartos do caminho lendo arquivos dos outros. A auditoria era pra ser sobre eles. Virou sobre mim. Tem alguma lição aí dentro, mas ainda estou na fase do constrangimento e não consegui formular.
O que mudou depois que arrumei dois
Arrumei dois. O de 47 links virou 16 links mais uma seção ## Optional. O que só apontava para HTML ganhou gêmeos .md para as 16 URLs em destaque via build hook do Astro (umas 25 linhas, mais fácil do que eu esperava).
Não posso te dizer “as citações de IA subiram X%” porque o arquivo tem uma semana de vida e medir citação nesse volume é ruidoso. O que posso dizer é que o arquivo agora passa num teste de cheirinho que eu deveria ter aplicado no dia um: “um modelo com context window de 200K e dez outras abas abertas preferiria esse arquivo ao anterior?” Sim. Obviamente sim. O anterior era ilegível.
A posição honesta sobre llms.txt
Os céticos têm parte de razão. O estudo da SE Ranking com 300K domínios não achou um lift mensurável de citação. Os LLMs principais não confirmam publicamente que buscam o arquivo. A spec não tem carimbo do W3C.
Os céticos também estão parcialmente errados. Agentes de IDE (Cursor, Cline, Continue), parte dos mecanismos de busca por IA, e uma lista crescente de integrações MCP leem llms.txt hoje. A opcionalidade é real e o custo é quinze minutos.
A pergunta real para 2026 não é “devo subir um llms.txt”. Essa pergunta já foi resolvida pela conta de custo-benefício. A pergunta é se o arquivo que você subir dá algo útil para um LLM ou treina ele a ignorar o seu domínio. Os anti-padrões 1 a 5 são a diferença entre esses dois desfechos.
O que fazer essa semana
Se você ainda não subiu um, comece pelas bases. Se já subiu, rode o seu pelo audit de cinco perguntas:
- Está abaixo de 10KB e abaixo de 20 links (excluindo
## Optional)? - Todas as URLs listadas passam no
robots.txtparaGPTBoteClaudeBot? - Pelo menos as 5 URLs do topo têm gêmeo
.md? - O corpo aponta para páginas específicas, não para copy genérico de marketing?
- Foi atualizado nos últimos 90 dias?
Se você bater 5 de 5, está no top 6 dos 30 sites que olhei, ou seja, no top 20% de uma amostra já auto-selecionada. Se bater 3 ou menos, você tem a mesma tarde de segunda à minha frente.
Estou escrevendo meu quarto llms.txt essa semana. Vou rodar essa lista antes de publicar. Não vou me sentir produtivo depois. Vou me sentir como alguém que aprendeu a mesma lição em três auditorias seguidas.
Dizem que engenharia é assim mesmo.
Referências
- Especificação llms.txt (Answer.AI): proposta original de Jeremy Howard
- Estudo SE Ranking de 300K domínios: adoção e efeito de citação
- Mintlify exemplos reais: padrões e erros de empresas líderes
- llmoframework.com: framework LLMO completo com Reference Templates
Quer ir mais fundo?
Este artigo cataloga os 5 anti-padrões. O guia completo de LLMO — padrões de llms.txt prontos pra copiar, exemplos de JSON-LD, KPIs de citação, comparação ChatGPT/Perplexity/Brave — está em LLMO Quickstart: Otimização para Busca por IA para Engenheiros.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?