Anotar conhecimento à mão não escala: montei um pipeline que registrou 300 fontes sozinho em 3 meses
Vou começar pela parte impopular: anotar conhecimento à mão não escala, e a maioria dos sistemas de notas que você monta vira um cemitério bem organizado. Eu sei porque enchi três deles. Notion lindo, Obsidian com grafo de mil bolinhas, uma pasta de bookmarks que passou de 400 links. Em todos, o mesmo final: salvei, nunca mais voltei. O problema nunca foi capturar a informação. Foi conseguir puxar a coisa certa na hora certa, e isso o salvamento manual não resolve. Só acumula.
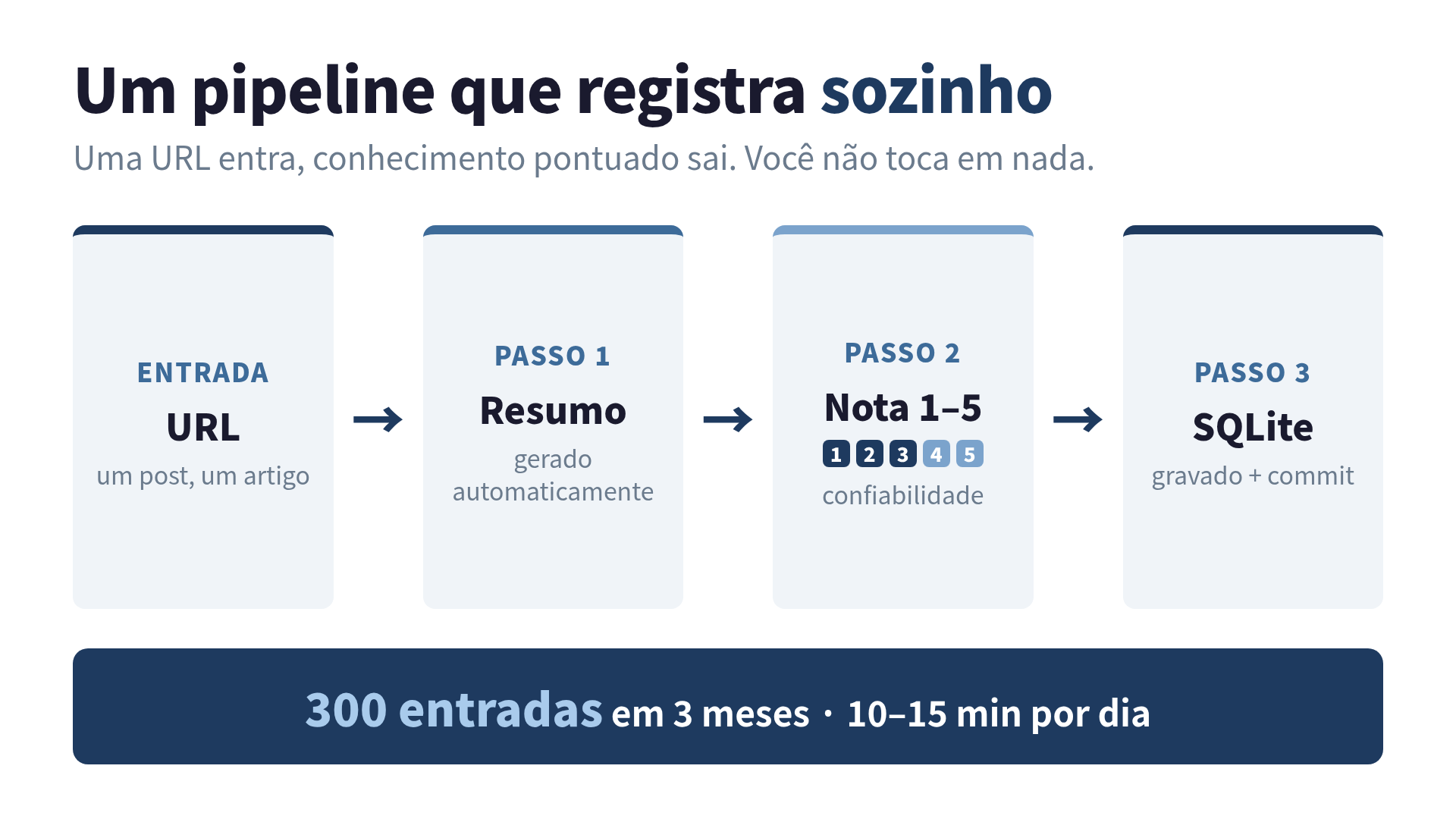
Então parei de me culpar por não ser disciplinado e montei um pipeline que faz o trabalho chato por mim. Hoje ele tem mais de 300 entradas, registradas ao longo de 3 meses, gastando uns 10 a 15 minutos por dia. E sim, eu vou abrir os números do que isso custou, porque achei honesto fazer isso.
Por que bookmark vira cemitério
Bookmark vira cemitério porque salvar e recuperar são problemas diferentes, e a gente só resolve o primeiro. Apertar Ctrl+D custa meio segundo. Achar de novo aquele post sobre “aquela técnica de cache” três semanas depois custa quinze minutos de busca por palavra que você não lembra mais. A conta não fecha, então você para de voltar, e o acervo morre.
Os sistemas de notas tradicionais não foram pensados para trabalhar junto com um agente de IA. Eram quatro furos que me incomodavam. Primeiro, registro manual não dura: você marca para ler depois e o depois nunca chega. Segundo, a busca é fraca: palavra-chave não acha “aquele papo lá”. Terceiro, a IA não consegue acessar: passar dado do Notion para o Claude Code dá um trabalho que desanima. Quarto, e o pior, tudo fica no mesmo nível: um artigo com mil curtidas e o desabafo de um desconhecido aparecem lado a lado, com o mesmo peso.
Esse último ponto é o que mais me irritava. Número de curtida não é confiabilidade. Tem post com 900 curtidas vendendo fumaça e tem artigo com 170 curtidas, baseado em experiência real, que vale ouro. Se o seu sistema trata os dois igual, ele está mentindo para você de forma educada.
O pipeline, em uma frase
O pipeline é isto: eu jogo uma URL para o Claude Code e ele faz o resto sozinho. Quando vejo um post que presta no X, no Zenn, num blog gringo, eu não salvo o link. Eu mando a URL e falo “registra isso”. A partir daí o agente busca o conteúdo, gera um resumo, extrai os metadados (autor, data, engajamento), pontua a confiabilidade de 1 a 5, classifica em categorias, gera um arquivo Markdown e grava tudo num banco SQLite. No fim, faz o commit no Git. Eu não toco em nada.
O coração disso é um banquinho SQLite com um gerenciador em Python que roda por linha de comando. Como é CLI, o próprio Claude Code dispara os comandos para registrar e buscar. Nada de servidor, nada de nuvem cara, nada de assinatura mensal. Um arquivo .db na minha máquina e uns scripts. Para quem desenvolve sozinho e olha o custo de nuvem de perto, essa simplicidade é metade do valor.
# registrar uma fonte
python3 manager.py add \
--path "knowledge/cache-strategy.md" \
--title "Estratégia de cache sem servir dado velho" \
--source-type "zenn" \
--categories "Backend,Cache"
# buscar por categoria
python3 manager.py list --category "Cache"A pontuação de confiabilidade é o pulo do gato
A peça que muda tudo é a pontuação de confiabilidade em 5 níveis, porque é ela que me protege de me deixar levar pelo número de curtidas. Toda entrada entra no banco com uma nota de 1 a 5, atribuída automaticamente segundo alguns critérios.
| Nota | Critério | Exemplo |
|---|---|---|
| 5 | Doc oficial, artigo revisado por pares | Blog oficial da Anthropic |
| 4 | Baseado em experiência prática, alto engajamento | Artigo técnico com autor que entrega |
| 3 | Artigo técnico comum, blog pessoal | Post de tutorial mediano |
| 2 | Afirmação não verificada, título sensacionalista | ”Ganhei X por mês com Y” |
| 1 | Procedência duvidosa | Repost de fonte desconhecida |
O julgamento pesa quatro coisas: a autoridade da fonte (oficial ou pessoal, histórico de quem escreve), o engajamento (curtidas e principalmente taxa de salvamento, que mente menos que curtida), a verificabilidade (tem código, tem demo, dá para reproduzir?) e o viés (é link de afiliado? é discurso de quem vende aquilo?).
Um exemplo concreto de como isso me salvou. Apareceu um post dizendo que dava para montar “um modelo financeiro nível Goldman Sachs” com 12 prompts. Os números eram lindos: 906 curtidas, 887 salvamentos, 160 mil impressões. O pipeline olhou para aquilo, viu que a reprodutibilidade era zero e nenhuma demo sustentava a promessa, e carimbou nota 2. Do outro lado, um artigo sobre princípios de design de skills, com 170 curtidas e 196 salvamentos, números modestos, mas baseado em uso real, levou nota 4. Hoje, quando puxo um tema, leio primeiro os 4 e 5 e trato os 2 como “tem gente afirmando isso, mas não verifiquei”. Esse julgamento ficou automático.
Os números honestos do que custou
Agora a parte que ninguém gosta de contar: montar a base custou um dia inteiro, mais ou menos 8 horas. Modelar o esquema do SQLite, escrever a CLI, montar o pipeline de registro automático. A maior parte desse código quem escreveu foi o próprio Claude Code, mas o tempo passou do mesmo jeito no meu relógio.
Depois disso, a operação são uns 10 a 15 minutos por dia. As 300 entradas vieram ao longo de uns 3 meses. Somando tudo: as 8 horas iniciais mais umas 22 horas de operação ao longo dos três meses dão cerca de 30 horas de investimento. Em troca, a velocidade de escrever artigos e de tomar decisão técnica subiu, na minha percepção, de 3 a 5 vezes. Esse “3 a 5 vezes” é sensação medida no olho, não cronômetro de laboratório, então te peço para tratar como relato de campo, não como lei da física.
Vale a pena? Para mim valeu, porque o ganho não está em nenhuma entrada isolada, está no acúmulo. Quando vou escrever sobre um assunto e busco no banco, o que era confiável já vem separado do que era ruído, com a nota do lado. Eu não pesquiso de novo o que já pesquisei uma vez.
Como começar sem copiar a minha complicação
Você não precisa copiar nada disso para começar, e é aqui que eu queria ter parado lá no início em vez de superdimensionar. O mínimo que funciona é uma pasta com arquivos Markdown e um CLAUDE.md dizendo “esta pasta é minha base de conhecimento”. Nem SQLite precisa. O Claude Code acha as coisas com grep e find numa boa enquanto a base é pequena.
minha-base/
├── CLAUDE.md # "esta pasta é a base de conhecimento"
├── conhecimento/ # joga os .md aqui
└── README.md # lista de categoriasQuando passar de umas dezenas de arquivos e a busca começar a engasgar, aí você migra para o SQLite. A pontuação de confiabilidade dá para começar na mão, marcando um número no topo de cada arquivo. O importante é começar pequeno e deixar o acúmulo te puxar. Quando bater a décima entrada e você pensar “opa, isso eu já tinha estudado” e puxar na hora, essa sensação vira o combustível para continuar.
O que eu aprendi no fim das contas é simples: o problema nunca foi a sua falta de disciplina para anotar. Foi pedir disciplina para uma tarefa que devia ser automática. Tira o registro chato das suas costas, deixa só a parte de pensar, e a base cresce sozinha enquanto você dorme.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?