Por que troquei prompt engineering por context engineering
Há mais ou menos um ano, eu estava convencido de que a habilidade do futuro era escrever prompts melhores. Estudei templates, comprei dois cursos, anotei frases mágicas tipo “think step by step” e “you are a senior engineer with 20 years of experience”. Resultado: códigos um pouco melhores, mas nada que justificasse o tempo gasto reescrevendo o mesmo prompt cinco vezes por dia.
Hoje eu rodo cinco projetos em paralelo com Claude Code. Não escrevo mais prompts longos. O que mudou foi a percepção de onde o esforço deve ir: não no input que mando agora, mas no contexto que o modelo já tem antes de eu abrir a boca.
Esse texto é sobre essa virada. O nome dela tem rótulo: engenharia de contexto.
O problema do prompt engineering
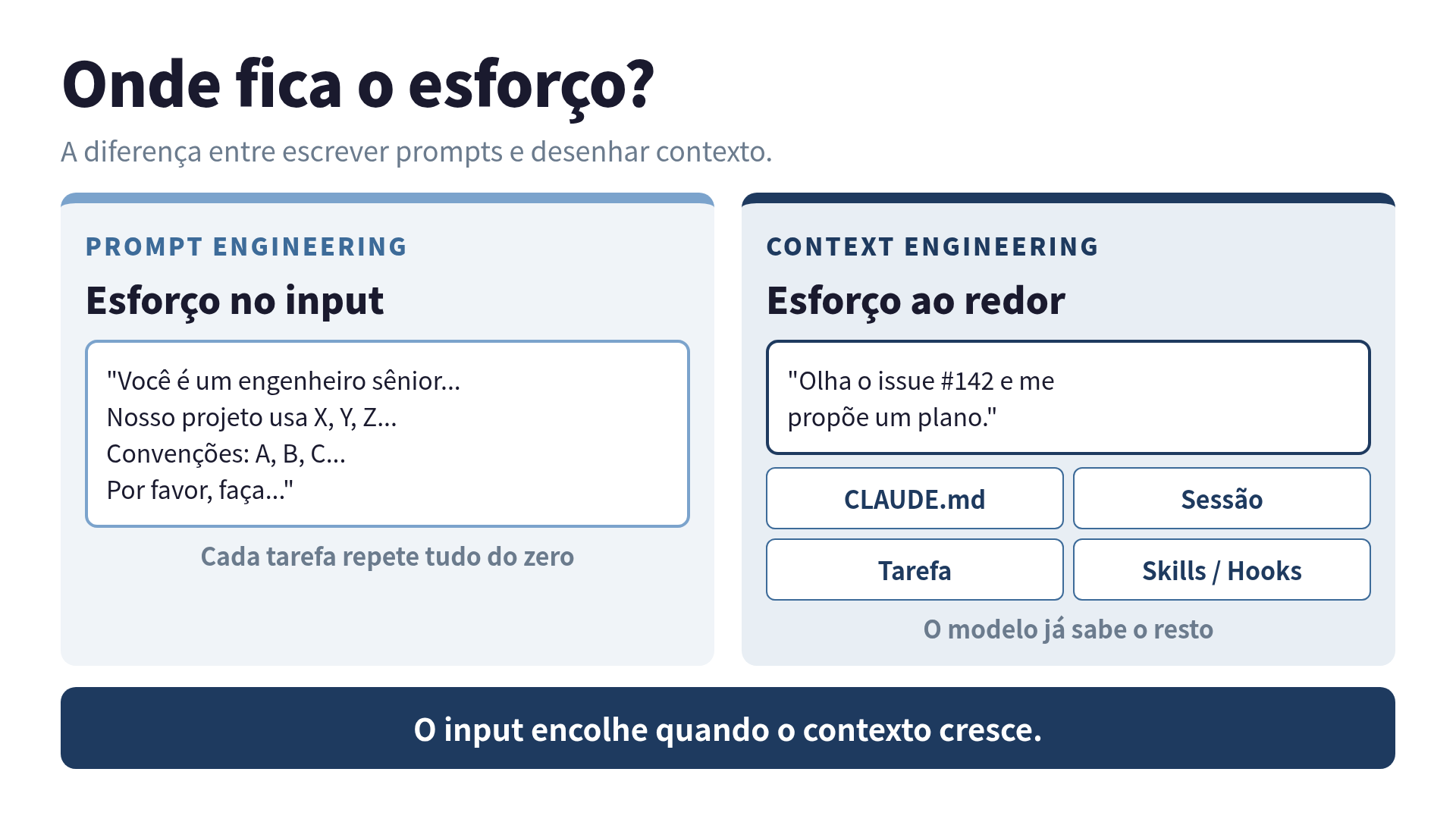
A ideia central do prompt engineering é simples: se eu formular bem a pergunta, o modelo responde melhor. E isso é verdade até certo ponto.
O problema aparece quando você tenta escalar. Cada tarefa exige um prompt diferente. Cada prompt precisa repetir convenções do projeto, restrições de estilo, decisões arquiteturais que já foram tomadas. Você acaba mantendo dezenas de “prompts mestres” em arquivos de texto, copiando e colando, e mesmo assim o modelo esquece coisas básicas no meio da sessão.
Eu chamo isso de economia do prompt único: cada interação começa do zero, e todo o peso recai no que você consegue empacotar naquela mensagem. É como contratar um sênior novo para cada PR e explicar o projeto inteiro antes de pedir cada mudança.
A virada
Em algum ponto eu percebi uma coisa: o modelo não precisa ler tudo de novo a cada vez. Se eu colocar as informações certas no lugar certo, ele as encontra sozinho.
Foi aí que comecei a pensar em camadas de contexto. Em vez de um prompt gigante, eu agora desenho quatro tipos de contexto que coexistem:
1. Contexto persistente (CLAUDE.md): convenções do projeto, decisões arquiteturais, comandos de build, “por que isso está assim”. Esse arquivo vive no repositório e é lido automaticamente toda vez que o Claude Code abre o projeto. Eu não preciso repetir nada disso em prompt.
2. Contexto de sessão: o que está aberto no editor, histórico recente da conversa, arquivos que foram lidos. O modelo já tem isso na janela de contexto.
3. Contexto de tarefa: só o que é específico daquele pedido. “Faz autenticação com JWT” em vez de “faz autenticação com JWT seguindo nosso padrão de erro centralizado em utils/errors.ts e usando bcrypt para hash de senha como descrito em CLAUDE.md”.
4. Contexto de ferramenta: Skills, hooks, MCP servers. Capacidades que o modelo invoca quando precisa, sem que eu peça.

A diferença prática: meu prompt típico hoje tem três linhas. O modelo já sabe o resto.
O que entra no CLAUDE.md
Esse é o pulo do gato. CLAUDE.md é tipo um README escrito para o modelo, não para humanos. Ele responde perguntas que o Claude faria se pudesse:
- Como rodar testes nesse projeto?
- Qual é o estilo de erro? Throw, return tuple, Result type?
- Tem alguma decisão arquitetural não óbvia que eu deveria respeitar?
- Quais comandos eu devo evitar? (drop database, force push, etc.)
- Onde fica a documentação de domínio que explica o “porquê” das coisas?
O meu CLAUDE.md de um dos projetos tem 180 linhas. Cobre estrutura de pastas, comandos de teste, padrões de commit, três decisões arquiteturais com explicação curta, e uma seção de “comportamentos a evitar”. Esse arquivo me poupa cinco minutos por interação. Multiplica por 50 interações por dia em cinco projetos: economia real de tempo.
CLAUDE.md como contrato
Tem um detalhe que demorou para eu entender: CLAUDE.md não é só uma lista de regras. Ele é um contrato bidirecional.
Do meu lado, eu prometo manter o arquivo atualizado quando decisões mudam. Do lado do modelo, ele se compromete a respeitar o que está escrito ali. Isso muda o tipo de feedback que eu recebo: se ele faz algo fora do padrão, eu agora reclamo apontando o trecho específico do CLAUDE.md. O modelo aceita melhor uma correção ancorada em “você violou a regra X” do que “isso está errado”.
Outro lado: se ele faz algo certo seguindo o contexto, eu paro de elogiar. Não preciso. Está fazendo o trabalho dele.
Meu workflow típico
Vou contar como uma manhã minha funciona, para ficar concreto.
Acordo, abro um dos projetos no terminal. Claude Code carrega o CLAUDE.md. Eu mando: “olha o issue #142 e me propõe um plano em 4 ou 5 etapas.”
O modelo lê o issue, lê os arquivos relevantes, e me devolve um plano em markdown com 4 ou 5 etapas. Eu reviso o plano (não o código ainda), corrijo uma decisão se necessário, e digo “execute.”
Enquanto isso, eu abro o segundo projeto e faço a mesma coisa. Depois o terceiro. Os três modelos trabalham em paralelo, cada um no seu repositório, cada um com seu CLAUDE.md.
Quando o primeiro termina, eu volto, leio o diff, faço review. Aqui é onde o humano agrega valor: julgar se o que foi feito faz sentido no contexto maior do produto. O modelo escreve código, eu decido se esse código entra ou não.
Em um dia bom, fecho 8 a 12 PRs assim. Em um dia ruim, descubro que eu deveria ter atualizado o CLAUDE.md de um projeto antes de começar. Sempre é minha culpa: o modelo só sabe o que eu deixei escrito.
O que eu deixei de fazer
Algumas coisas pararam de existir no meu workflow:
- Prompts com mais de 5 linhas
- “Você é um engenheiro sênior…” e companhia
- Re-explicar a estrutura do projeto
- Repetir convenções de naming
- Pedir para o modelo “lembrar” de algo da conversa anterior
- Cursores múltiplos no IDE (terminal venceu)
Algumas começaram:
- Atualizar CLAUDE.md como hábito (igual atualizar README)
- Pensar em Skills reutilizáveis para tarefas que repito
- Configurar hooks para automatizar verificações
- Discutir decisões com o modelo antes de pedir código
Onde isso te leva
Se você está hoje na fase de “escrever prompts melhores”, o próximo passo provável é parar de escrever prompts e começar a escrever contexto. CLAUDE.md é o ponto de entrada mais barato. 30 minutos investidos no arquivo costumam economizar horas na semana seguinte.
Abre o seu projeto agora, cria um CLAUDE.md com cinco linhas sobre como rodar os testes e qual é o padrão de erro. Veja o que muda na próxima sessão. Costuma ser óbvio.
Quer ir mais fundo?
Este artigo introduz a ideia de trocar prompt por contexto. O sistema completo — RAG, MCP, CLAUDE.md, Agentic RAG, validado em benchmark próprio com ganho de 4,6× — está em Transformando LLMs de Mentirosos em Especialistas: Engenharia de Contexto na Prática.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?