Dei WebSearch ao meu Strategist. 5 temas levaram 20 minutos. Separar em 3 agentes baixou pra 3.
Eu achava que um agente fazendo tudo era elegante. Uma chamada claude -p, “escolha os temas de hoje e escreva o principal”, pronto. Levava 20 minutos pra escolher 5 temas.
Separei em três agentes e o mesmo trabalho passou a levar 3 minutos. O custo em tokens caiu uns 60%. Cada agente sozinho ficou mais burro. O pipeline inteiro ficou mais rápido.
O truque não é “mais agentes”. O truque é tirar o WebSearch do agente que decide.
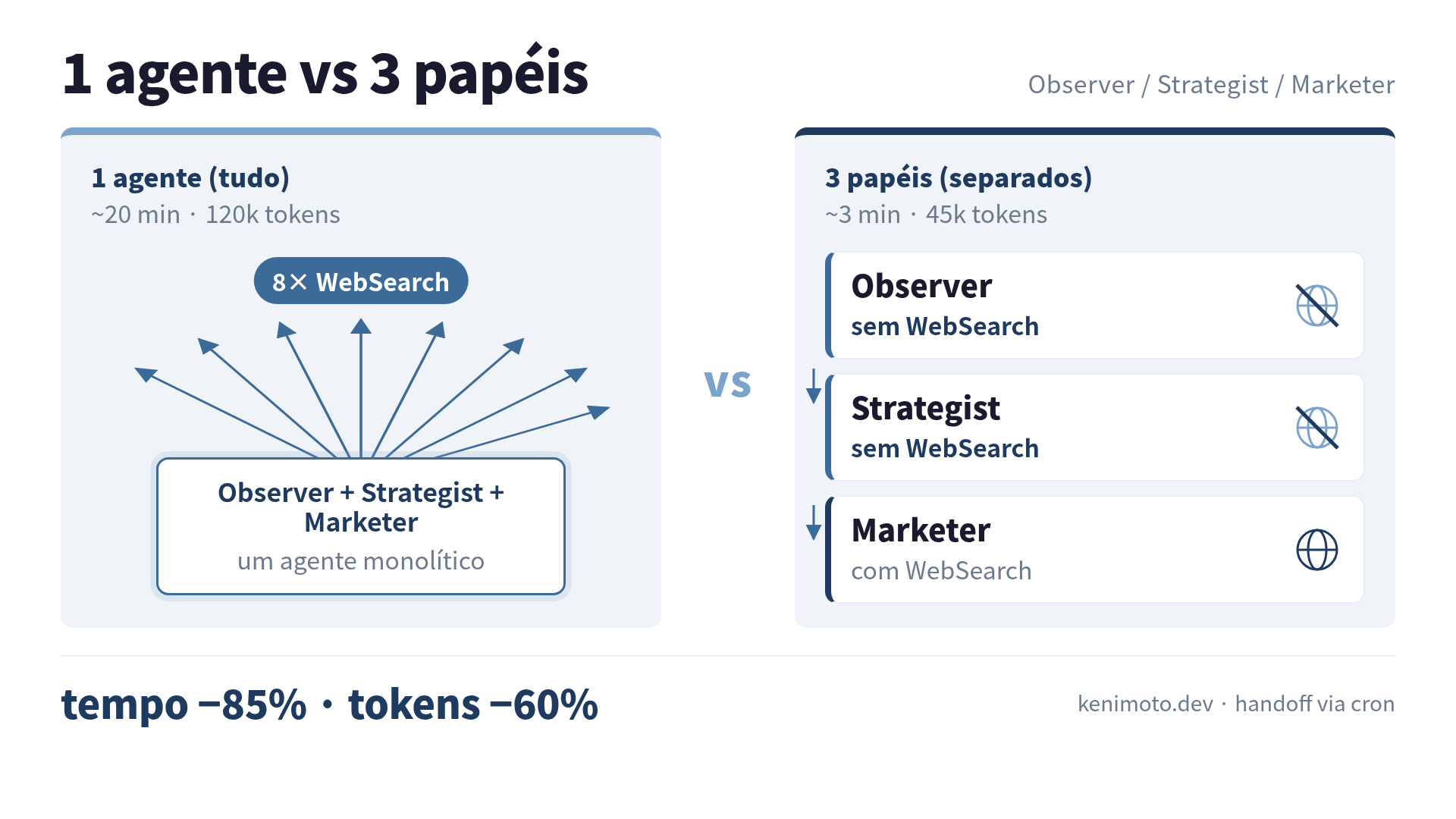
O setup de 1 agente que levava 20 minutos
A configuração original era um prompt, um agente, uma execução:
“Olha os dados do GA4 de ontem, escolhe 5 temas pra hoje e escreve o de maior prioridade.”
O agente tinha Bash, Read, Write, Edit, Grep, Glob, WebSearch, WebFetch liberados. Tudo o que ele pudesse precisar.
Pra cada tema candidato, o agente fazia mais ou menos a mesma coisa: WebSearch pra ver “o que está bombando nesse nicho agora”, WebSearch de novo pra confirmar a tendência, WebSearch uma terceira vez pra cruzar com o que o concorrente publicou. Cinco temas, três ou quatro buscas em cada, 15 a 20 buscas por execução. Cada busca despejava alguns milhares de tokens de resultado no contexto.
Quando o agente estava escolhendo o terceiro tema, o contexto de decisão já tinha mais de 40 mil tokens de resultados de busca dos temas 1 e 2. A relação sinal/ruído colapsava. O agente começava a escolher temas que “soavam confirmados pelas notícias recentes”, em vez de temas que casavam com o material que eu realmente tinha em estoque.
O sintoma visível era o tempo: cerca de 20 minutos por execução. O sintoma escondido era a deriva. Toda semana, na revisão, eu sobrescrevia as escolhas do agente, porque não batiam com o conteúdo que eu tinha pronto.
Por que WebSearch no loop de decisão é uma armadilha
WebSearch tudo bem. WebSearch dentro do loop de decisão é a armadilha.
Duas coisas acontecem quando você deixa o juiz buscar:
Tempo: uma busca leva de 5 a 20 segundos. Cinco temas vezes quatro buscas dão 100 segundos só esperando, antes de contar leitura e raciocínio. Pra um humano fazendo uma pergunta, é nada. Pra um job diário automatizado, isso acumula rápido.
Poluição de contexto: cada resultado joga de 2 mil a 5 mil tokens de texto raspado de página HTML dentro do contexto de decisão. Nada disso foi estruturado pra responder “esse tema serve pro meu conteúdo?”. Foi estruturado pra SEO. O juiz acaba raciocinando em cima de uma pilha de copy de marketing, em vez de raciocinar em cima dos próprios dados.
A correção é sem graça. O juiz não deve ter WebSearch. WebSearch é coisa do escritor.
Papel 1: Observer — só coleta
O trabalho do Observer é “puxar os números de ontem e gravar num arquivo”. É só isso.
Entrada: GA4, API do Zenn, API do Dev.to, logs de ontem. Saída: domains/<nome>/data/snapshot-YYYY-MM-DD.json.
Ferramentas permitidas:
claude -p "$(cat scripts/prompts/observer-prompt.txt)" \
--allowed-tools "Bash,Read,Write"Sem WebSearch, sem WebFetch, sem Edit. O Observer chama três APIs com curl e escreve um único arquivo JSON. Se ele tenta ser esperto e “interpretar os dados”, o prompt manda parar. O schema também segura: os campos são total_views, top_performers_3, errors_yesterday. Não existe campo recommendation, então não tem onde encaixar uma decisão mesmo que quisesse opinar.
Parece um downgrade. É, no mesmo sentido em que uma função de propósito único é “downgrade” em relação a um god object. Quando o Observer quebra, eu sei exatamente qual API caiu, porque é só o que ele faz.
Papel 2: Strategist — só julga, sem WebSearch
O Strategist lê o que o Observer escreveu, lê o strategy.md pras regras, lê os últimos 30 dias de temas publicados pra montar a lista de exclusão e escolhe 5 temas. Só isso.
claude -p "$(cat scripts/prompts/strategist-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob"Repara no que sumiu: WebSearch, WebFetch. Tirados fisicamente do allow-list. O Strategist literalmente não consegue acessar a internet.
Foi a parte que eu mais resisti. “Como ele vai julgar os temas de hoje sem ver o que está em alta?” A pergunta era errada. A certa é: eu estou escrevendo temas que estão bombando em outro lugar ou temas que casam com meu estoque de conteúdo?
O Strategist enxerga:
- Três meses dos meus próprios dados de performance (o que foi lido)
- Meu estoque de conteúdo (capítulos de livro, rascunhos não publicados)
- Lista de exclusão de 30 dias (o que já escrevi)
- O meu próprio
strategy.md
Isso basta pra escolher 5 temas em uns 90 segundos, não 20 minutos. O consumo de tokens por execução do Strategist caiu de uns 80 mil pra uns 20 mil, porque não tem mais resultado de WebSearch pra ler.
“Adicionar evidência com WebSearch” soava como boa ideia. Na prática, adicionou 8 buscas redundantes e 40 mil tokens de ruído.
Papel 3: Marketer — executa, com WebSearch liberado
O Marketer lê a saída do Strategist, pega o tema de maior prioridade e escreve o artigo. É aqui que o WebSearch aparece:
claude -p "$(cat scripts/prompts/marketer-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob,WebSearch,WebFetch"O Marketer usa WebSearch pra pesquisa de execução:
- “Versão estável mais recente do LangGraph em 2026”
- “URL oficial do Building Effective Agents da Anthropic”
- “Plano de preços do Inngest pra workflows com cron”
Isso é citação e checagem de versão, não decisão. “Devo escrever esse tema?” já foi resolvido. O WebSearch do Marketer fica limitado ao artigo da frente.
Daí caem duas consequências:
- O custo se localiza. Gasto com WebSearch vive dentro do Marketer, onde produz saída visível. O custo por execução do Strategist agora é pequeno o suficiente pra rodar várias vezes por semana sem pensar.
- A falha se localiza. Quando o WebSearch está instável ou fora do ar, só o escritor quebra. O Strategist continua entregando os temas do dia. O Observer continua registrando os números de ontem. O pipeline degrada, não para.
A cadeia cron: como os três papéis se conectam
Os três agentes não compartilham conversa. Compartilham arquivos.
07:00 Observer → grava snapshot-2026-05-14.json
09:00 Strategist → lê snapshot, grava strategist-2026-05-14.md
10:00 Marketer → lê strategist.md, grava rascunho + agenda publicação 22:00
22:00 Observer → registra tração inicial do dia → entrada de amanhãRodo isso como cron puro num VPS pequeno. A versão curta é uma linha por job com set -euo pipefail, trap ... ERR, um ping de falha no Telegram e um lock file. Cerca de 30 linhas de shell por papel.
Se preferir durabilidade gerenciada em vez de cron, Temporal Schedules, trigger cron do Inngest e GitHub Actions cron cabem todos no mesmo formato. A arquitetura não liga pra qual deles carrega ela. Eu uso cron porque o modo de falha é “o servidor está desligado”, e isso eu noto rápido.
A passagem de bastão é sempre um arquivo em disco. JSON pro snapshot, Markdown pro log do strategist, Markdown pro log do marketer. Legível por humano, com data, replayável. Eu consigo rodar o Marketer de ontem em cima do arquivo do Strategist de ontem mudando uma variável de ambiente. Backfill de graça, sem herdar Airflow.
Sub-agent vs separação em papéis — não confunde
Eu tenho outro post sobre rodar três sub-agentes do Claude Code no mesmo PR e ver eles discordarem em 41% dos comentários. Volta e meia me perguntam se é a mesma coisa que estou descrevendo aqui.
Não é. Parecem iguais num slide e se comportam de formas opostas na prática.
| Sub-agent (Task tool do Claude Code) | Separação em papéis (cron) | |
|---|---|---|
| Escopo | Mesma sessão, mesmo agente pai | Três processos, três execuções |
| Estado | Pai passa o contexto na entrada | Arquivo em disco |
| Tempo | Síncrono, o pai espera | Assíncrono, com horas de distância |
| Falha | Pai cuida do retry | Cada job tenta de novo sozinho |
| Caso de uso | ”Explore esse repo em paralelo" | "Roda o PDCA de ontem toda manhã” |
Sub-agent serve pra paralelismo dentro de uma tarefa. Separação em papéis serve pra pipeline deslocado no tempo. Misturar os dois te dá o pior dos dois mundos: a superfície de debug do cron, mais a deriva de contexto compartilhado dos sub-agents.
A regra que eu uso: se a resposta tem que voltar na mesma conversa, é sub-agent. Se a resposta tem que sobreviver a um reboot do servidor, é cron com job separado.
Dentro do Brasil
Aqui dentro do Brasil, agente de IA já não é assunto de hype: o iFood já tem 9 mil agentes de IA em produção e redesenhou 32% das atividades com tarefas executadas por agentes em vez de gente. A Hotmart montou um agente de vendas treinado com a voz do creator. A RD Station acoplou agentes de IA no produto Conversas. O que essas equipes não estão fazendo é deixar um único agente rodar observação, decisão e execução num único loop. Em escala, separar os papéis é o que vira pipeline confiável em vez de demo.
Em conta direta: na minha operação, o Strategist consumia uns USD 30 (R$ 150) por mês quando era um agente único com WebSearch. Depois da separação, caiu pra uns USD 12 (R$ 60). Pra um time pequeno, isso é o suficiente pra justificar a reestruturação numa tarde.
Números medidos
São os meus números rodando os dois setups em cima do mesmo estoque de conteúdo.
| Métrica | 1 agente | 3 papéis | Mudança |
|---|---|---|---|
| Tempo pra escolher 5 temas | ~20 min | ~3 min | -85% |
| Tokens por execução diária | ~120k | ~45k | -62% |
| Gasto mensal de API | ~USD 60 (R$ 300) | ~USD 22 (R$ 110) | -63% |
| Re-escolha de tema (revisão semanal) | 2-3/sem | 0-1/sem | desce |
| Queda do WebSearch derruba pipeline | sim | não | resolvido |
| Tempo médio pra debugar falha | 30-60 min | 5-10 min | -80% |
A conta dos tokens foi o que me surpreendeu. Eu chutava que separar em três agentes ia aumentar o consumo total, por causa de contexto duplicado. Não aumentou. O tráfego de WebSearch que sumiu era maior que o overhead novo por papel.
O tempo de debug é o que pesa no dia a dia. Com um agente só, “o job falhou às 09
” não me diz nada. Com três papéis, “o Strategist falhou às 09” me diz qual script de 30 linhas eu preciso abrir.“Adicionar agentes deixou mais rápido” soa errado na cara. Só ficou mais rápido porque tirei o WebSearch do loop de decisão. A divisão foi o que permitiu remover na prática: no momento em que o Observer e o Strategist deixaram de alcançar a internet, a tentação de “só mais uma busca” sumiu.
A separação em papéis é uma das peças da “harness” que mantém o agente dentro de um trilho previsível. O livro com 19 capítulos sobre como desenhar essa harness — allow-list por papel, AGENTS.md de 2 a 100 linhas, hooks pre-commit / pre-tool-use, e os 5 frameworks que falam sobre isso de forma diferente — está em Harness Engineering: De Usar IA a Controlar IA.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?