
Systematizing AI Code Review
The 3-Layer Model for 60% Faster Reviews
The 3-layer model that cut my code review time by 60% — hooks for format, AI for first pass, humans for design judgment
30+ technical books across 4 languages · Sold on Kindle in 6 countries · From a year of real production use
📖 Read for free
Read three full chapters right here before you buy. Liked it? Continue on Kindle.
01 Preface -- Turning Reviews into a System
“Write tests before opening a PR.”
I wrote that in AGENTS.md. A PR showed up without tests anyway.
“Use Conventional Comments labels.”
I shared the convention with the team. A week later, I was the only one using labels.
Requests get forgotten. Rules get broken.
But systems keep running.
I have failed multiple times at making review culture stick.
I wrote documentation. Nobody read it. I ran a workshop. Forgotten by the following week. I sent Slack reminders. People muted the channel.
Yet every Monday, I kept writing review comments like “fix the formatting” and “reorder the imports.” Thirty minutes, every week.
The person writing those comments felt productive. But what about the person on the receiving end?
“Flagged again.” “Another round of fixes.” Formatting comments are pure friction for the recipient. A design discussion teaches you something. “Your indentation isn’t 2 spaces” teaches you nothing. You just fix it. The reviewer gets tired. The reviewee gets tired.
And when both sides are tired, what happens?
Reviews get ignored.
PRs sit open for three days. Nobody comments. Someone clicks Approve and merges. Review becomes a formality. This is the reality for many teams.
The turning point came when I introduced an AI review tool.
The moment CodeRabbit caught every formatting and linter violation, the review thread changed completely. Instead of “fix the indent,” the conversations became “what about this design?” and “should we keep adding this pattern?” Something shifted.
It felt like installing a traffic light so the officer directing traffic could go back to actual police work.
This book is about turning code review from a “request” into a “system.”
Hooks enforce linting. AI handles first-pass review. Humans focus on design and direction.
The approach is straightforward. File structures, configurations, and pipelines are explained at copy-paste granularity.
Some familiarity with harness engineering fundamentals (AGENTS.md, hooks, feedback loops) and basic code review concepts will make the book easier to follow.
Code review is the heartbeat of the harness. When the heart stops, everything else is affected.
Continue this chapter on Kindle →02 Embedding Code Review in the Harness Quality Layer

The 6-Layer Harness Model
Harness engineering designs the operating environment for AI agents across six layers.

Code review sits at the core of Layer 3: Quality Verification.
Think of a house: Layer 1 is the blueprint, Layer 2 is the construction procedure, Layer 3 is the building inspection. Nobody wants to live in a house that was never inspected.
Three Sublayers of the Quality Verification Layer
Breaking the quality verification layer down further reveals three sublayers.
| Sublayer | Owner | Speed | Accuracy |
|---|---|---|---|
| Automated gates | hooks / CI | Seconds | Mechanical precision |
| AI review | CodeRabbit / Copilot | Minutes | Pattern recognition |
| Human review | Team members | Hours | Design judgment and direction |
Speed decreases as you go up, but judgment quality increases. It works like a restaurant kitchen: the dishwasher (automated gate) is the fastest, the sous chef (AI) handles quality checks, and the head chef (human) decides the direction of the flavor.
”Almost Every Time” vs. “Every Single Time”
A SmartScope article nails the point:
Writing “run the linter” in CLAUDE.md vs. enforcing linter execution with a hook is the difference between “almost every time” and “every single time.”
The gap between “almost every time” and “every single time” is wider than it looks. A 90% compliance rate means 1 in 10 PRs ships broken code. With 100 PRs a month, that is 10 uninspected deployments to production.
The same applies to code review.
| Method | Compliance rate |
|---|---|
| Write “write tests before PR” in AGENTS.md | 80-90% |
| Enforce test execution via pre-commit hook | 100% |
| Write “use Conventional Comments” in AGENTS.md | 50-70% |
| Add label reminder in PR template | 70-80% |
Enforcement increases in this order: request, template, hook, CI. This book designs what to enforce and what to keep optional at each layer.
Why Not Enforce Everything?
You might think “why not enforce everything in CI?” But enforcing everything kills development speed.
Just as security has “the convenience vs. security tradeoff,” reviews have “the enforcement vs. velocity tradeoff.” What matters is drawing the line between what to enforce and what to recommend.
This book’s approach:
- Enforce: formatting, linting, type checks, tests — things machines can judge
- Recommend: Conventional Comments labels, PR size limits — things involving human judgment
File Structure Overview
Here is the file structure of the harness review system this book builds:

Starting from the next chapter, we will design each of the three sublayers in order.
Continue this chapter on Kindle →03 The 3-Layer Review Model -- Automated / AI / Human

In the previous chapter, we established that code review belongs in Layer 3 (Quality Verification) of the harness. This chapter breaks that layer into three sublayers. This structure is the backbone of the entire book.
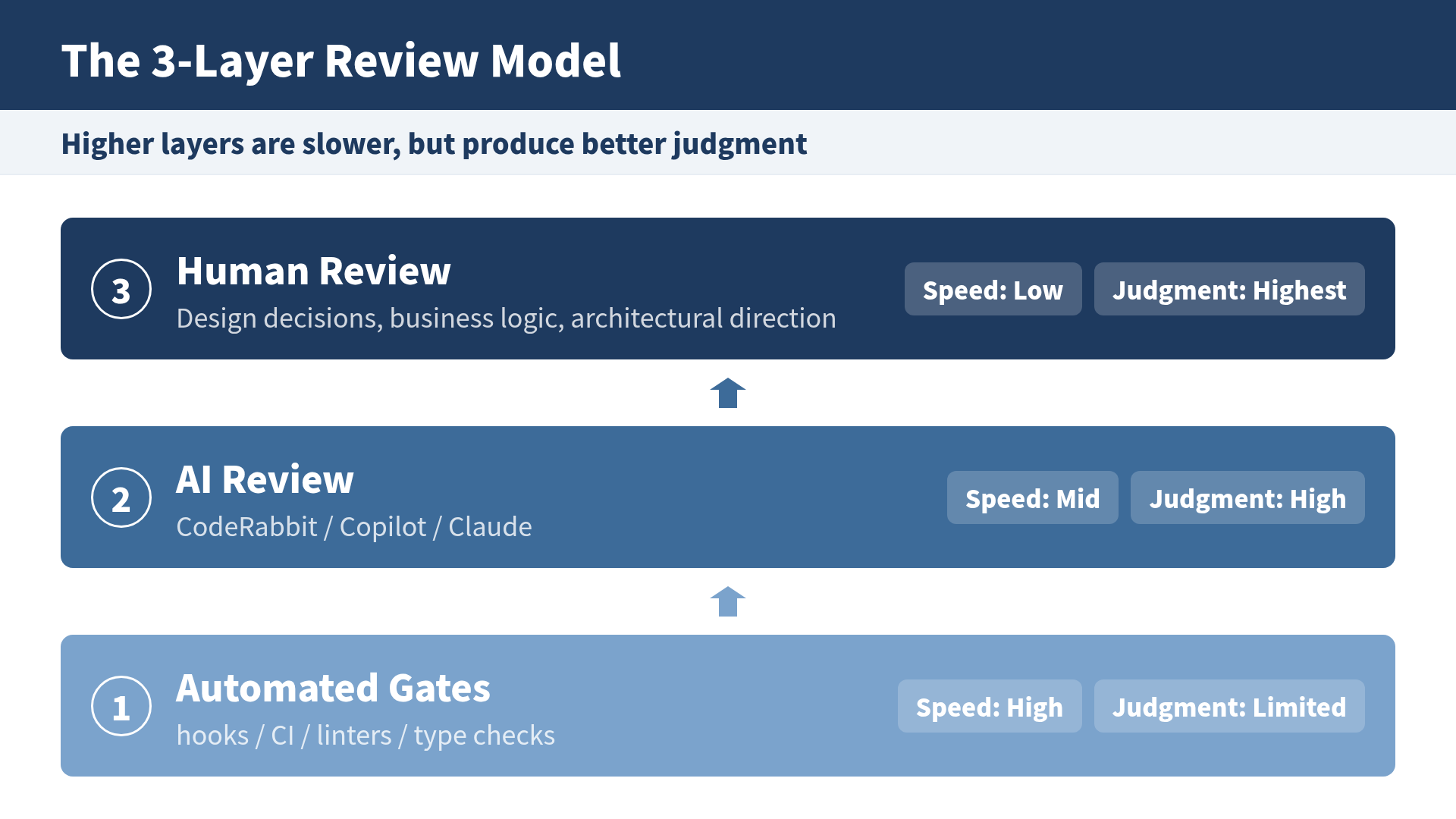
Dividing Roles Across Three Layers
The biggest problem with code review is trying to have humans do everything.
Style checks, linter violations, type errors, test coverage, security vulnerabilities, design decisions, directional discussions. When one reviewer handles all of that in a single PR, review fatigue is inevitable.
The 3-layer model divides the labor.
Layer 1: Automated Gates (No Human Involvement)
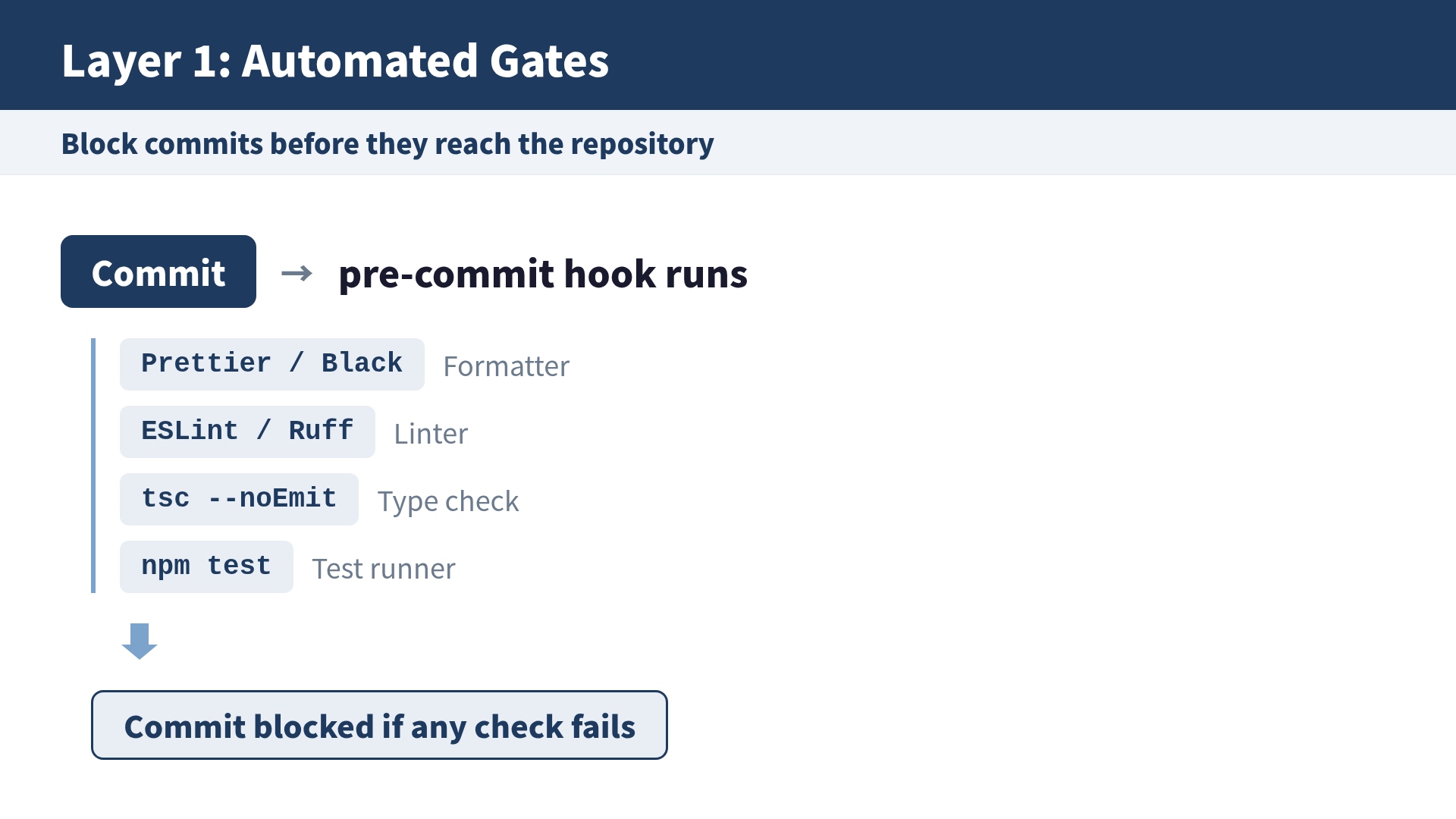
Anything caught here never reaches the PR. It is resolved before a reviewer ever sees it.
Principle: if a machine can judge it, let the machine handle it.
Layer 2: AI Review (Pattern Recognition)
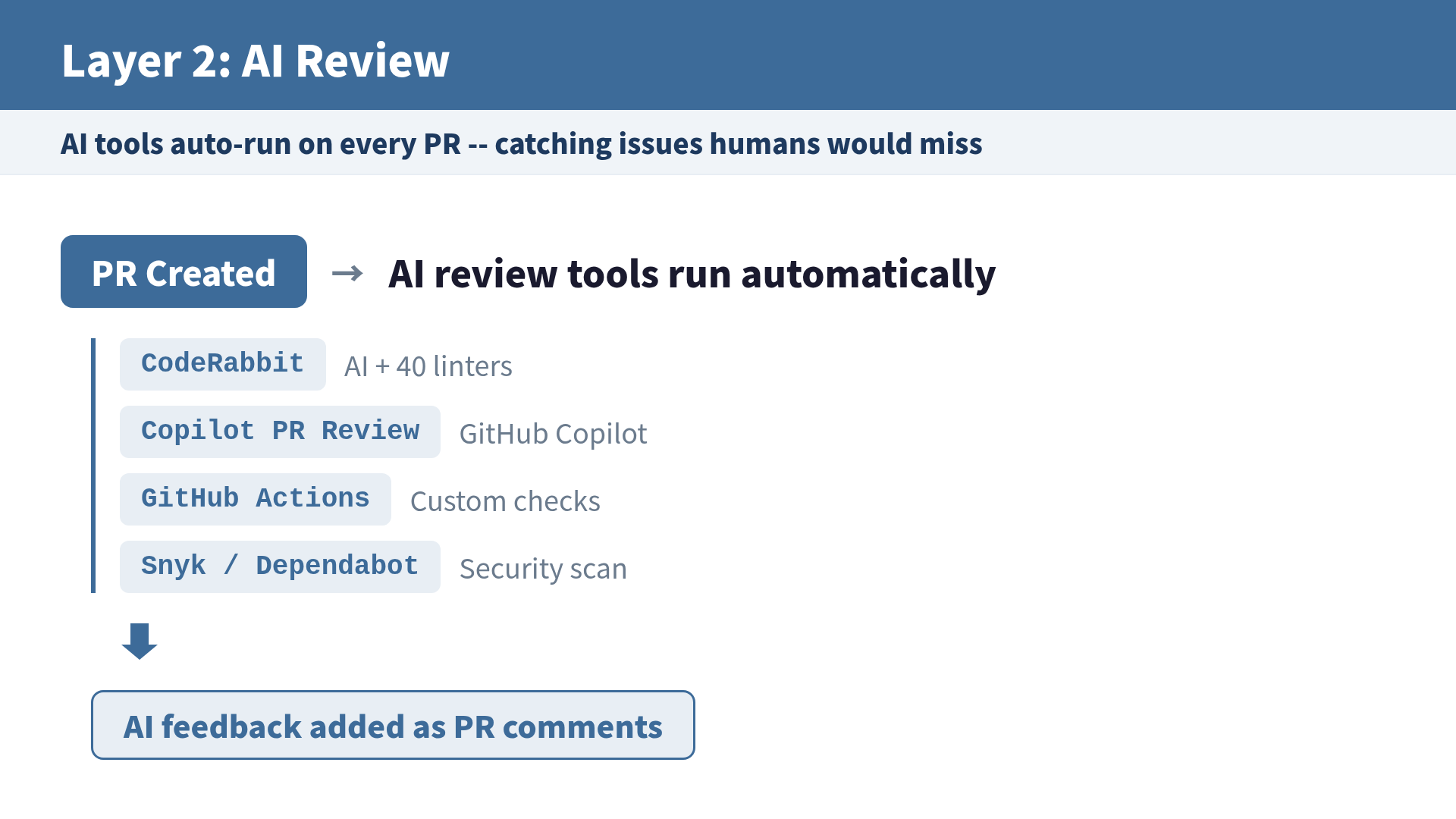
What AI can find:
- N+1 query problems
- SQL injection risks
- Unused imports/variables
- Insufficient test coverage
- Naming convention violations
Principle: if a pattern can detect it, let AI handle it.
Layer 3: Human Review (Judgment and Direction)
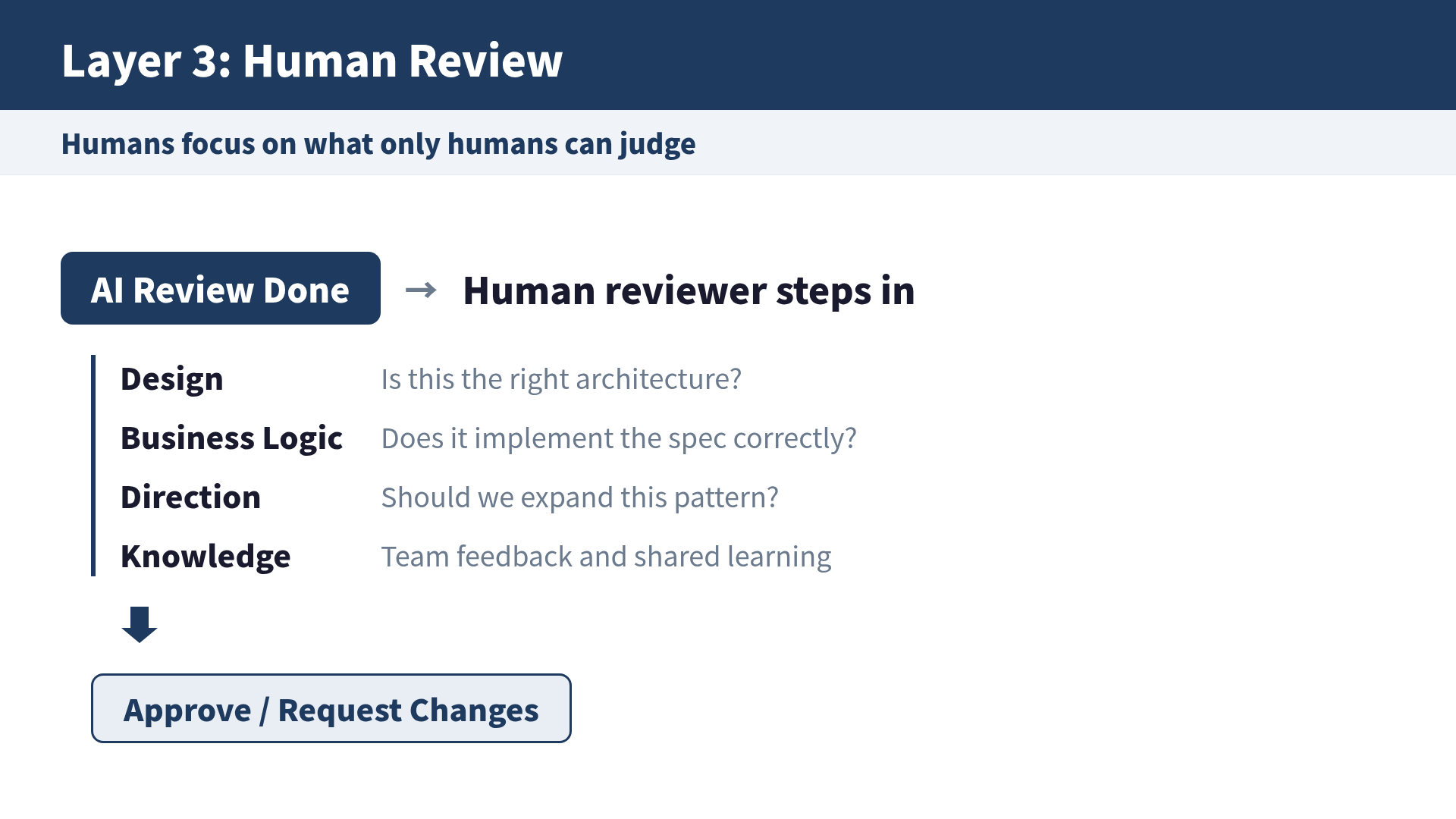
Principle: humans should only handle what requires judgment.
The Effect of Three Layers

Because humans can focus on judgment, the quality of reviews also improves.
Responsibility Boundaries per Layer
| Issue type | Layer 1 (auto) | Layer 2 (AI) | Layer 3 (human) |
|---|---|---|---|
| Formatting | O | ||
| Linter violations | O | ||
| Type errors | O | ||
| Test failures | O | ||
| N+1 problems | O | ||
| Security vulnerabilities | O | ||
| Naming improvements | O | ||
| Design decisions | O | ||
| Business logic | O | ||
| Directional editing | O |
When the boundaries are clear, each layer can focus on its own job.
When Human Review Is Not Needed
Here is an important point: not every PR needs to reach Layer 3.
Bug fixes, dependency updates, and simple ticket work that require no design decisions or business logic validation can be completed with just Layer 1 (automated gates) and Layer 2 (AI review).
| PR type | Required layers |
|---|---|
| Formatting fix | Layer 1 only |
| Dependency update (Dependabot) | Layer 1 + Layer 2 |
| Bug fix (clear cause) | Layer 1 + Layer 2 |
| Refactoring (small) | Layer 1 + Layer 2 |
| New feature | Layer 1 + Layer 2 + Layer 3 |
| Architecture change | Layer 1 + Layer 2 + Layer 3 |
| New pattern introduction | Layer 1 + Layer 2 + Layer 3 |
Human review is only needed for PRs that involve judgment. If you do not make this explicit, you end up requiring human review on every PR, and review becomes a bottleneck again.
Continue this chapter on Kindle →Overview
Code review time keeps inflating because humans are doing the mechanical work. This book splits the job across three layers — hooks (machines), AI (first pass), and humans (architectural judgment) — and shows the actual implementation that cut review time by 60%. Includes integrated operation of CodeRabbit, GitHub Copilot, and Claude review, AGENTS.md policy design, GitHub Actions pipelines, and an autoFixable feedback loop, all backed by a Next.js + TypeScript reference project.
What you will be able to do
- Split review across hooks, AI, and humans with a clear role for each
- Encode review policies in AGENTS.md and operate CodeRabbit/Copilot/Claude as a unit
- Embed Conventional Comments into the harness so comment intent becomes machine-readable
- Build an AI review pipeline on GitHub Actions
- Design an autoFixable loop that feeds review findings back into AGENTS.md
Who is this book for
- [Tech lead] Review time is ballooning and you want to cut it
- [Mid-size team developer] Trying to balance review quality and speed
- [AGENTS.md author] Want to encode review policies into your harness
- [CI/CD maintainer] Looking to plug AI review into GitHub Actions
- [Tool selector] Trying to map out CodeRabbit / Copilot / Claude responsibilities
- [Startup CTO] Need to maintain quality and velocity with a small team
Problems this book solves
- Reviews keep stalling on formatting and naming nits
- Tried AI review tools but the human/AI split never feels right
- Can't tell what CodeRabbit, Copilot, and Claude are each best at
- Want a concrete example of review policies inside AGENTS.md
- Don't have a working blueprint for AI review on GitHub Actions
- AI review accuracy is too low so humans end up doing it again anyway
Where this book stands
- Implementation-first (Next.js + TypeScript reference project, end to end)
- Mid-size team focus (5–30 people — not solo, not enterprise review culture)
- Harness-aware (treats AGENTS.md and review design as one system)
- Tool-agnostic (integrated operation of CodeRabbit, Copilot, and Claude)
Why this book
- First book to systematize review around the '3-Layer Model' framework
- Concrete patterns for running CodeRabbit, Copilot, and Claude together
- Combines AGENTS.md with Conventional Comments for machine-readable intent
- autoFixable loop returns review findings back into the harness itself
- Publishes a full review pipeline for a real Next.js + TypeScript project
How this differs from other AI books
| Compared to | This book's difference |
|---|---|
| General code review books (e.g., Code Review Best Practices) | Focused on operating with AI in the loop. Systematizes the hooks/AI/human split rather than treating them as separate concerns. |
| Tool docs (CodeRabbit, Copilot, etc.) | Not single-tool. Provides patterns for running three tools together with concrete implementation. |
| General Harness Engineering books | Zooms in on the quality-verification layer of the harness. Goes deep on AGENTS.md integration specifically. |
Table of contents
- 01 Introduction — turning review into a system Free preview
- 02 Embedding code review in the harness's quality-verification layer Free preview
- 2-1 The 6-Layer Harness Model
- 2-2 Three Sublayers of the Quality Verification Layer
- 2-3 "Almost Every Time" vs. "Every Single Time"
- 2-4 Why Not Enforce Everything?
- 2-5 File Structure Overview
- 03 The 3-Layer Review Model — automated / AI / human Free preview
- 3-1 Dividing Roles Across Three Layers
- 3-2 Layer 1: Automated Gates (No Human Involvement)
- 3-3 Layer 2: AI Review (Pattern Recognition)
- 3-4 Layer 3: Human Review (Judgment and Direction)
- 3-5 The Effect of Three Layers
- 3-6 Responsibility Boundaries per Layer
- 3-7 When Human Review Is Not Needed
- 04 Layer 1: gates enforced by hooks and CI
- 05 Layer 2: introducing AI review by design
- 06 Layer 3: narrowing human review to design and direction
- 07 Writing review policy into AGENTS.md
- 08 Embedding Conventional Comments in the harness
- 09 Automating PR templates and review checklists
- 10 Setting up CodeRabbit
- 11 Adding more AI reviewers: Copilot and Claude
- 12 Building a review pipeline on GitHub Actions
- 13 The autoFixable pattern — automating mechanical fixes
- 14 Feedback loops — returning review findings to AGENTS.md
- 15 Measuring and improving review metrics
- 16 Reference implementation: harness review for a Next.js + TypeScript project
- 17 Closing — review is the heart of the harness
- 18 References
- 19 About the Author
- 20 Colophon
Spending review time on formatting issues is like a chef washing dishes. Reviews stall because humans are doing the mechanical work.
This book splits the job across three layers: hooks (machines) → AI review (first pass) → humans (design judgment). The same split, in a real production project, dropped review time by 60%.
Run CodeRabbit, GitHub Copilot, and Claude as a coordinated team. Encode the policy in AGENTS.md. Wire the pipeline through GitHub Actions. And let the autoFixable loop feed review findings back into AGENTS.md so the harness itself keeps getting sharper.
“Humans focus on design and direction. Everything else, the machines handle.”
Related books



Dive deeper with related articles
Read on Kindle
Included in Kindle Unlimited
Read on Kindle* This page contains Amazon Associates links. Purchases may earn the author a referral fee.