
AIコードレビューを仕組み化する技術
hooks・AI・人間の3層モデル
AIコードレビュー 自動化 | hooks 設計・CodeRabbit 導入・Conventional Comments・GitHub Actions パイプライン
Zenn累計32,000+ views · 4言語で30冊以上出版 · Kindle 6カ国で販売中
📖 無料で読める章
買う前に3章をその場で読めます。気に入ったらKindleで続きを。
01 はじめに -- レビューを「仕組み」にする
「テストを書いてからPRを出してください」
AGENTS.mdにこう書いた。でも、テストなしのPRが出てきた。
「Conventional Commentsのラベルを付けてください」
チームに共有した。1週間後、ラベルを付けているのは自分だけだった。
お願いは忘れられます。ルールは破られます。
でも 仕組み は動き続けます。
私はレビュー文化の浸透に何度も失敗しています。
ドキュメントを書いた。読まれなかった。勉強会を開いた。翌週には忘れられた。Slackにリマインドを流した。ミュートされた。
それでも毎週月曜日、「フォーマット直してください」「importの順番変えてください」というレビューコメントを書き続けていました。30分かけて。
やっている側は正しいことをしている気でいた。でも、レビューされる側はどうだったか。
「また指摘された」「また直すのか」。フォーマットの指摘は、受け取る側にとっては純粋なストレスです。設計の議論なら学びがある。でも「インデントが2スペースじゃない」に学びはありません。直すだけ。指摘する側も疲れる。される側も疲れる。
そうやって両方が疲弊した結果、どうなったか。
レビュー自体が放置されるようになりました。
PRが3日開きっぱなし。誰もコメントしない。Approve だけ押してマージ。形だけのレビュー。これが多くのチームの現実です。
転機は、AIレビューツールを導入したときです。
CodeRabbitがフォーマットとリンター違反を全部拾ってくれた瞬間、レビュー欄の景色が変わりました。「インデント直して」の代わりに、「この設計どうする?」「この方向で増やしていいの?」という議論が始まった。
信号機を設置したら、交通整理の警察官が本来の仕事に戻れた。そんな感覚です。
本書は、コードレビューを「お願い」から「仕組み」に変える本です。
hooksでリンターを強制する。AIに一次レビューを任せる。人間は設計と方向性に集中する。
やることは明快です。ファイル構成、設定、パイプラインを、コピペできる粒度で解説します。
前提知識として、ハーネスエンジニアリングの基本(AGENTS.md、hooks、フィードバックループ)とコードレビューの基礎を理解していると読みやすいです。
コードレビューはハーネスの心臓部です。心臓が止まれば、全身に影響が出ます。
この続きはKindleで →02 ハーネスの品質検証層にコードレビューを組み込む

ハーネスの6層モデル
ハーネスエンジニアリングは、AIエージェントの動作環境を6つの層で設計します。
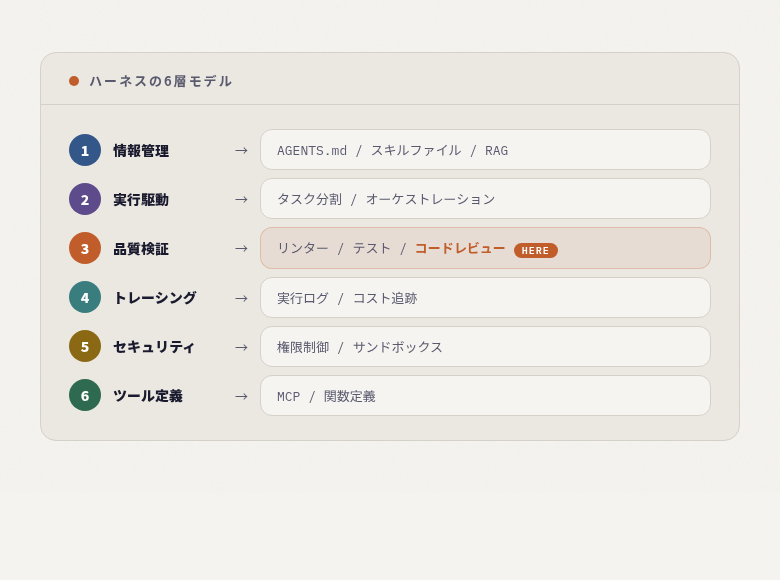
コードレビューは ③品質検証層 の中核です。
家に例えると、①が設計図、②が施工手順、③が建築検査。検査なしで建てた家に住みたい人はいません。
品質検証層の3つのサブレイヤー
品質検証層をさらに分解すると、3つのサブレイヤーに分かれます。
| サブレイヤー | 担当 | 速度 | 精度 |
|---|---|---|---|
| 自動ゲート | hooks / CI | 秒単位 | 機械的な正確さ |
| AIレビュー | CodeRabbit / Copilot | 分単位 | パターン認識 |
| 人間レビュー | チームメンバー | 時間単位 | 設計判断・方向性 |
下から上に向かって、速度は遅くなるが、判断の質は上がる。レストランの厨房と同じです。皿洗い機(自動ゲート)が最も速く、スーシェフ(AI)が品質チェックし、ヘッドシェフ(人間)が味の方向性を決める。
「ほぼ毎回」vs「例外なく毎回」
SmartScopeの記事が核心を突いています。
CLAUDE.mdに「リンターを実行せよ」と書くのと、Hookでリンター実行を強制するのは、「ほぼ毎回」と「例外なく毎回」の違い。
「ほぼ毎回」と「例外なく毎回」の間には、見た目以上の溝があります。90%の遵守率は「10回に1回は壊れたコードが通る」ということ。月に100PRあれば10本が検査なしで本番に行きます。
コードレビューでも同じです。
| 方法 | 実行率 |
|---|---|
| AGENTS.mdに「テストを書いてからPR」と記載 | 80-90% |
| pre-commitフックでテスト実行を強制 | 100% |
| AGENTS.mdに「Conventional Commentsを使う」と記載 | 50-70% |
| PRテンプレートにラベルのリマインドを記載 | 70-80% |
お願い → テンプレート → フック → CIの順で強制力が上がります。本書では、それぞれのレイヤーで何を強制し、何を任意にするかを設計します。
なぜ全部を強制しないのか
「全部CIで強制すればいいのでは?」と思うかもしれません。しかし、全部を強制すると開発のスピードが著しく落ちます。
セキュリティの世界に「利便性とセキュリティのトレードオフ」があるように、レビューにも「強制力と開発速度のトレードオフ」があります。大切なのは、何を強制し何を推奨に留めるかの線引きです。
本書のアプローチ:
- 強制: フォーマット、リンター、型チェック、テスト → 機械的に判断できるもの
- 推奨: Conventional Commentsのラベル、PRサイズ制限 → 人間の判断が関わるもの
ファイル構成の全体像
本書で構築するハーネスレビューシステムのファイル構成:

次章から、3つのサブレイヤーを順に設計していきます。
この続きはKindleで →03 レビューの3層モデル -- 自動 / AI / 人間

前章で、コードレビューがハーネスの③品質検証層に位置することがわかりました。この章では、その品質検証層を 3つのサブレイヤーに分解 します。これが本書の背骨になる構造です。
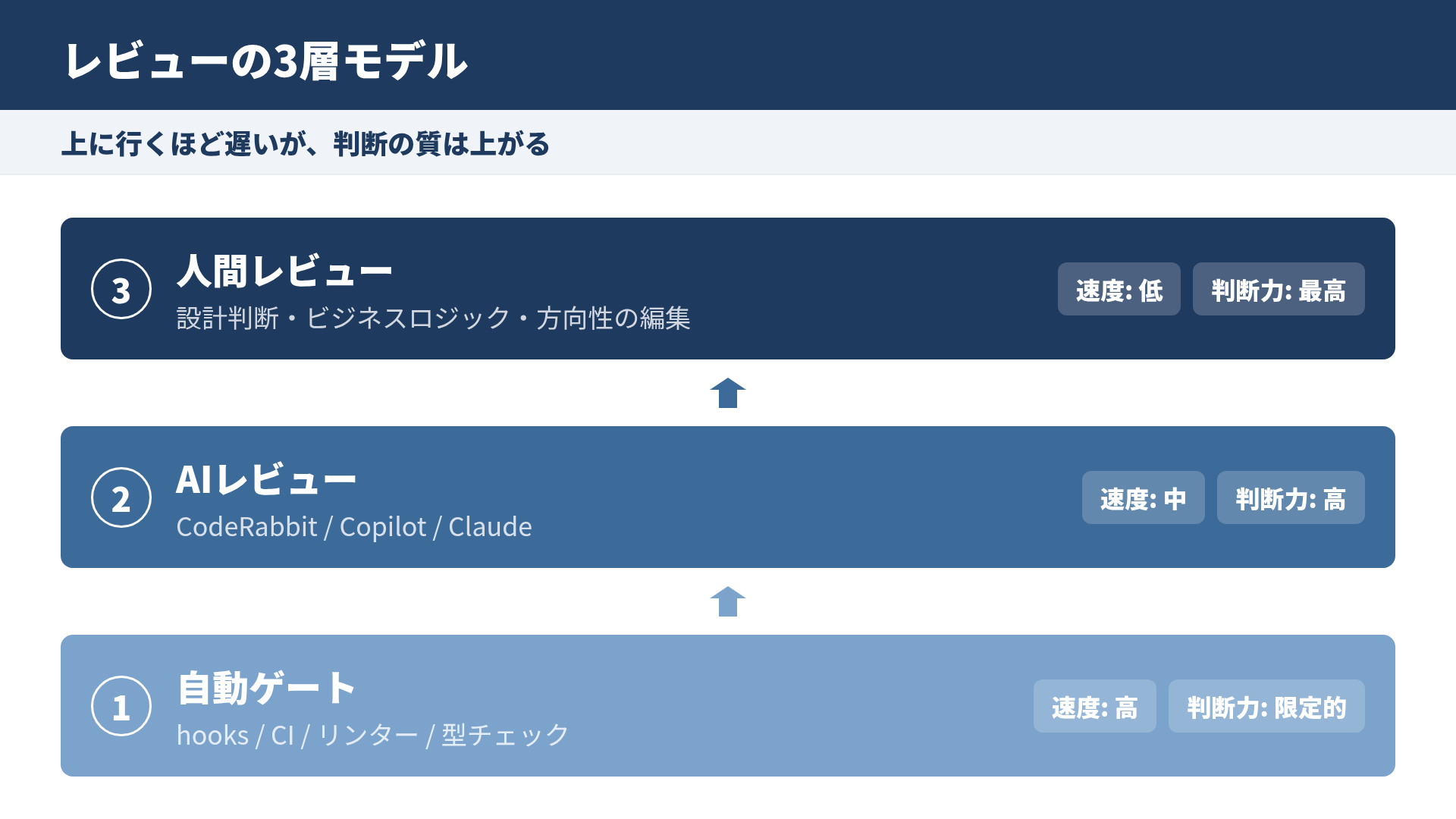
3層で役割を分ける
コードレビューの最大の問題は、すべてを人間がやろうとすることです。
スタイルチェック、リンター違反、型エラー、テストの有無、セキュリティ脆弱性、設計判断、方向性の議論。これを1人のレビュアーが1つのPRで全部やると、レビュー疲れが起きて当然です。
3層モデルはこれを分業します。
第1層: 自動ゲート(人間が関与しない)
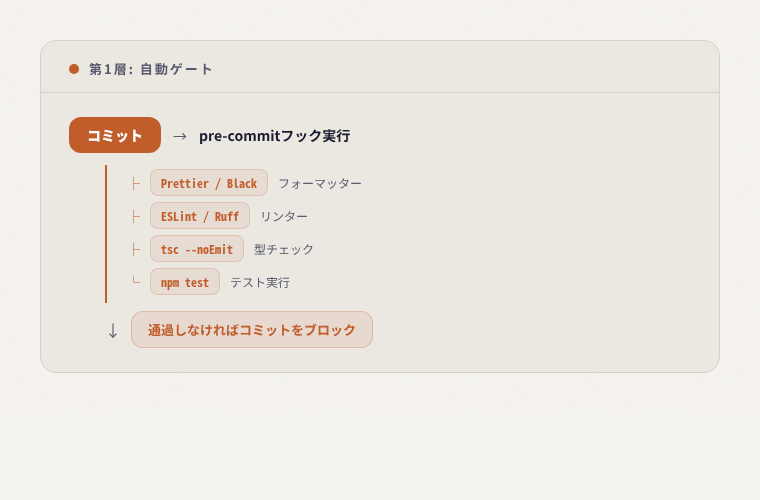
ここで弾かれるものは、PRにすら到達しません。レビュアーの目に触れる前に解決される。
原則: 機械的に判断できるものは機械に任せる。
第2層: AIレビュー(パターン認識)
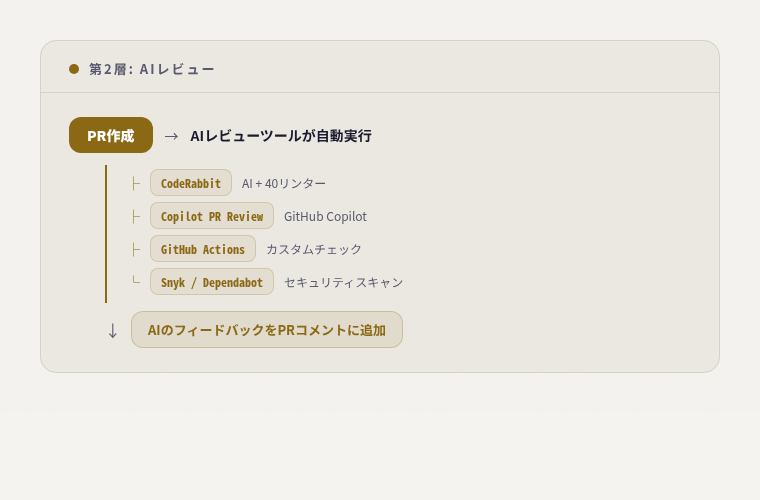
AIが見つけられるもの:
- N+1問題
- SQLインジェクションリスク
- 未使用のインポート/変数
- テストカバレッジの不足
- 命名規則の違反
原則: パターンで検出できるものはAIに任せる。
第3層: 人間レビュー(判断と方向性)
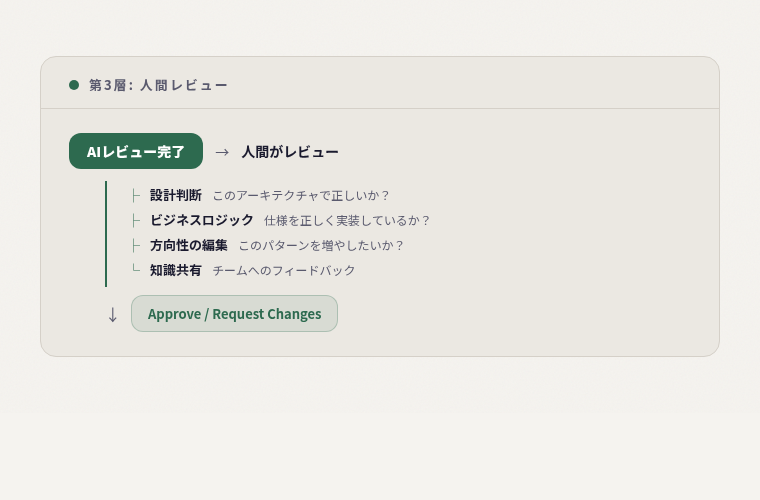
原則: 判断が必要なものだけ人間がやる。
3層の効果
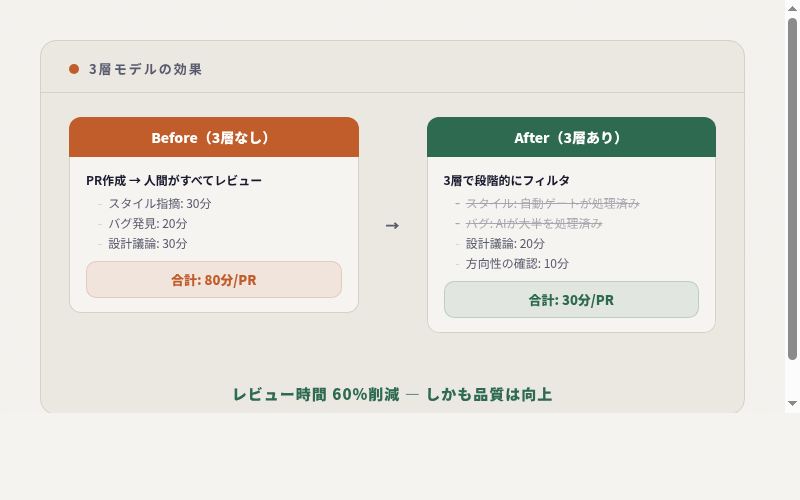
人間は判断に集中できるから、品質も上がります。
各層の責任境界
| 問題の種類 | 第1層(自動) | 第2層(AI) | 第3層(人間) |
|---|---|---|---|
| フォーマット | ○ | ||
| リンター違反 | ○ | ||
| 型エラー | ○ | ||
| テスト失敗 | ○ | ||
| N+1問題 | ○ | ||
| セキュリティ脆弱性 | ○ | ||
| 命名の改善 | ○ | ||
| 設計判断 | ○ | ||
| ビジネスロジック | ○ | ||
| 方向性の編集 | ○ |
境界が明確だと、各層が自分の仕事に集中できます。
人間レビューが不要なケース
ここで重要な点があります。 すべてのPRが第3層まで到達する必要はありません。
バグ修正、依存関係の更新、シンプルなチケット対応など、設計判断やビジネスロジックの確認が不要なPRは、第1層(自動ゲート)と第2層(AIレビュー)だけで完結できます。
| PRの種類 | 必要な層 |
|---|---|
| フォーマット修正 | 第1層のみ |
| 依存関係の更新(Dependabot) | 第1層 + 第2層 |
| バグ修正(原因が明確) | 第1層 + 第2層 |
| リファクタリング(小規模) | 第1層 + 第2層 |
| 新機能追加 | 第1層 + 第2層 + 第3層 |
| アーキテクチャ変更 | 第1層 + 第2層 + 第3層 |
| 新しいパターンの導入 | 第1層 + 第2層 + 第3層 |
人間のレビューが必要なのは「判断」が伴うPRだけです。これを明確にしておかないと、全PRに人間レビューを要求して、結局レビューがボトルネックに戻ります。
この続きはKindleで →本書の概要
AIコードレビューを仕組み化する3層モデル。hooks がフォーマットを強制、CodeRabbit/Copilot/Claude が一次レビュー、人間は設計判断に集中。AGENTS.md とフィードバックループで仕組みが進化する設計を Next.js + TypeScript の実装例で解説。
この本でできるようになること
- hooks・AI・人間の3層モデルでレビューを役割分担できるようになる
- AGENTS.md にレビュー方針を書き、CodeRabbit/Copilot/Claude を運用に組み込める
- Conventional Comments をハーネスに組み込み、コメントの意図を機械可読にできる
- GitHub Actions でAIレビューパイプラインを構築できる
- レビュー結果を AGENTS.md にフィードバックする autoFixable ループを設計できる
対象読者
- 【テックリード】チームのレビュー時間が肥大化していて削減したい人
- 【中規模チーム開発者】レビュー品質と速度を両立させたい人
- 【AGENTS.md設計者】レビュー方針をハーネスに書きたい人
- 【CI/CD担当】GitHub Actions に AI レビューを組み込みたい人
- 【AIツール選定中】CodeRabbit / Copilot / Claude の使い分けを知りたい人
- 【スタートアップCTO】少人数で品質と速度を担保する仕組みを作りたい人
この本で解決できる悩み
- フォーマット指摘・命名指摘でレビューに時間がかかりすぎる
- AIレビューツールを試したが、人間のレビューと役割分担できていない
- CodeRabbit と Copilot と Claude、何が違うのか分からない
- AGENTS.md にレビュー方針を書く具体例が知りたい
- GitHub Actions で AI レビューを動かす設計が分からない
- AI レビューの精度が低くて結局人間が見直している
この本の立ち位置
- 実装重視 (Next.js + TypeScript の具体実装まで提示)
- 中規模チーム向け (個人開発でも、大企業のレビュー文化でもない、5-30人スケール)
- ハーネス連携 (AGENTS.md とレビュー設計を一体で扱う)
- ツール横断 (CodeRabbit / Copilot / Claude の3つを統合運用)
なぜこの本か
- 「3層モデル」というフレームワークでレビュー設計を体系化した最初の本
- CodeRabbit / Copilot / Claude の3つを統合運用する具体パターン
- AGENTS.md と Conventional Comments の組み合わせを実装
- autoFixable ループでレビュー結果が仕組みに還流する設計
- 実プロジェクト (Next.js + TypeScript) のレビューパイプライン全体を公開
他のAI本との違い
| 比較対象 | 本書の違い |
|---|---|
| コードレビュー一般書 (Code Review Best Practices等) | AI を組み込んだ運用設計に特化。hooks・AI・人間の役割分担を体系化する。 |
| CodeRabbit / Copilot 等のツール公式ドキュメント | 1ツールではなく、3ツールを統合運用するパターンを実装例とともに提示。 |
| ハーネスエンジニアリング全般書 | ハーネスのうち品質検証層(コードレビュー)に絞って深掘り。AGENTS.mdとの連携を具体化。 |
目次
- 01 はじめに — レビューを「仕組み」にする 無料公開
- 02 ハーネスの品質検証層にコードレビューを組み込む 無料公開
- 2-1 ハーネスの6層モデル
- 2-2 品質検証層の3つのサブレイヤー
- 2-3 「ほぼ毎回」vs「例外なく毎回」
- 2-4 なぜ全部を強制しないのか
- 2-5 ファイル構成の全体像
- 03 レビューの3層モデル — 自動 / AI / 人間 無料公開
- 3-1 3層で役割を分ける
- 3-2 第1層: 自動ゲート(人間が関与しない)
- 3-3 第2層: AIレビュー(パターン認識)
- 3-4 第3層: 人間レビュー(判断と方向性)
- 3-5 3層の効果
- 3-6 各層の責任境界
- 3-7 人間レビューが不要なケース
- 04 第1層: hooks と CI で強制するゲート
- 05 第2層: AI レビューの導入設計
- 06 第3層: 人間レビューの焦点を設計と方向性に絞る
- 07 AGENTS.md にレビュー方針を書く
- 08 Conventional Comments をハーネスに組み込む
- 09 PR テンプレートとレビューチェックリストの自動化
- 10 CodeRabbit の導入と設定
- 11 AI レビューツールの追加: Copilot / Claude
- 12 GitHub Actions でレビューパイプラインを構築する
- 13 autoFixable パターン — 機械的修正の自動化
- 14 フィードバックループ — レビュー結果を AGENTS.md に還元する
- 15 レビューメトリクスの計測と改善
- 16 実装例: Next.js + TypeScript プロジェクトのハーネスレビュー設計
- 17 おわりに — レビューはハーネスの心臓部
- 18 参考文献
- 19 著者紹介
- 20 奥付
「フォーマット指摘に時間を使うのは、料理人が皿洗いに時間を使うようなもの。」
レビュー時間が肥大化する原因は、人間が機械的なチェックを担当していることです。本書では、hooks (機械) → AI レビュー (一次) → 人間 (設計判断) の3層モデルで役割を分け、レビュー時間を60%削減した実プロジェクトの設計を扱います。
CodeRabbit / Copilot / Claude を組み合わせて運用し、AGENTS.md にレビュー方針を書き、GitHub Actions でパイプラインを組む。レビュー結果は autoFixable ループで AGENTS.md に還流し、仕組み自体が育っていく。
「人間は設計判断と方向性だけに集中する。それ以外は機械に任せる。」
シリーズ・関連書籍


関連記事で深掘りする
Kindleで購入する
Kindle Unlimited 対象
Kindleで読む (¥1,000)※ 本ページにはAmazonアソシエイトリンクが含まれます。クリック先での購入により著者に紹介料が入る場合があります。