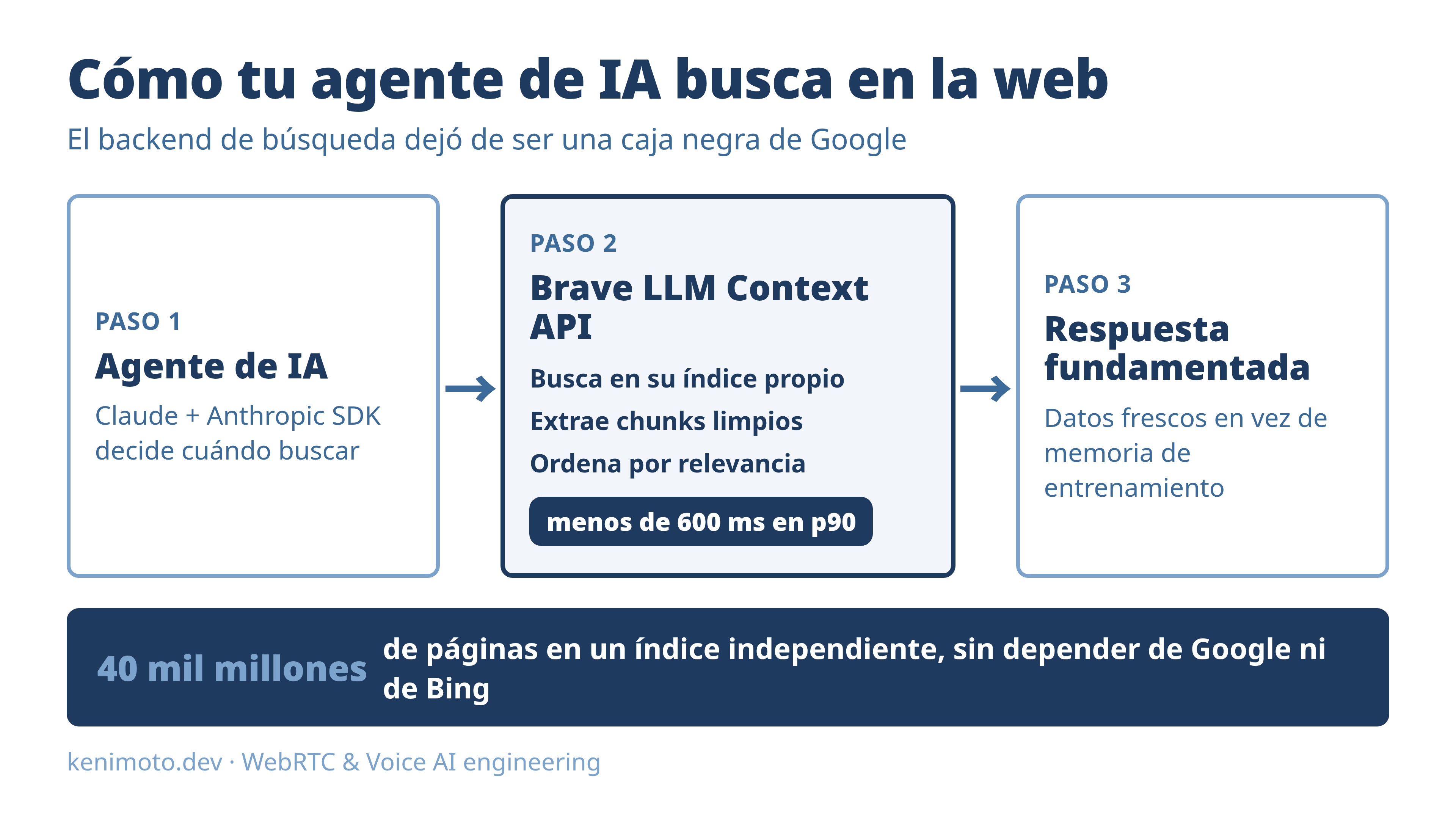
Brave Search LLM Context API: integración paso a paso para tu agente de IA
La primera vez que abrí el panel de red de mi agente para ver de dónde sacaba la información, esperaba ver a Google. O al menos a Bing. Lo que encontré fue api.search.brave.com. Me quedé mirando la pantalla un rato largo, con la sensación incómoda de haber estado usando algo durante meses sin saber qué era. Resulta que el motor de búsqueda detrás de buena parte de las herramientas de IA que ya uso a diario no era ninguno de los dos sospechosos habituales.
Si tú también das por hecho que tu agente consulta a Google por debajo, sigue leyendo. En esta guía conecto el Brave LLM Context API con Python y el Anthropic SDK, paso a paso, y lo dejo listo para producción. Tiempo estimado de la versión mínima: 15 minutos. Tiempo que tardé yo la primera vez, entre leer la documentación y entender por qué fallaba mi token: bastante más, pero para eso está este artículo.
Por qué Brave y no otro
Empecemos por el contexto, porque importa para entender qué estás conectando.
El 11 de agosto de 2025, Microsoft retiró por completo las Bing Search APIs. No fue una deprecación suave con dos años de aviso: nuevos registros cerrados, recursos existentes deshabilitados, fin de la historia (Microsoft Learn). Para mucha gente que tenía aplicaciones de IA apoyadas en Bing, fue como llegar al estacionamiento y descubrir que la salida estaba tapiada.
¿Por qué te cuento esto? Porque cambió el mapa. Google no abre su índice web de forma amplia para fundamentar respuestas de IA: su Programmable Search Engine está pensado para casos acotados, no para alimentar un agente o un sistema de RAG. Con Bing fuera, el catálogo de APIs comerciales con un índice web propio, grande e independiente se quedó muy corto. Y ahí es donde Brave Search ocupó el espacio.
Las razones prácticas para elegir Brave hoy son concretas:
- Índice propio e independiente: alrededor de 40 mil millones de páginas, sin depender de Google ni de Bing por debajo (Brave).
- Adopción real: herramientas que muchos usamos a diario lo usan como backend de búsqueda. No es una promesa de la hoja de ruta, es la red que ya estás golpeando sin darte cuenta.
- Privacidad por arquitectura: como Brave controla toda la cadena, desde el rastreador hasta el endpoint, puede ofrecer retención cero de datos. Las APIs que en realidad son scrapers de Google o Bing no pueden prometer lo mismo, porque la consulta termina viajando a un tercero que no controlan.
No necesitas creerte que Brave es mejor en abstracto. Necesitas saber que, si tu agente va a buscar en la web en 2026, esta es una de las pocas puertas que siguen abiertas y que está diseñada para lo que tú quieres hacer.
Qué hace distinto al LLM Context API
El detalle que de verdad cambia tu código está en qué formato recibe el modelo.
Una API de búsqueda web tradicional está pensada para humanos: te devuelve título, URL y un fragmento corto, y se asume que tú vas a hacer clic y leer. Para un modelo de lenguaje, ese formato es trabajo extra: tienes que descargar cada página, limpiar el HTML, recortar la basura de navegación y publicidad, y recién entonces pasarle algo útil al modelo.
El LLM Context API, que Brave lanzó el 12 de febrero de 2026, le da la vuelta a eso (Brave). En lugar de URLs y fragmentos, devuelve contenido ya extraído, troceado y ordenado por relevancia, listo para que el modelo lo consuma directo. Por dentro hace tres cosas en cada consulta:
- Busca en el índice independiente de Brave.
- Extrae el contenido real de cada página y lo convierte en fragmentos limpios: texto, tablas con granularidad de fila, bloques de código (pensado a propósito para agentes de programación), discusiones de foros tipo Stack Overflow e incluso subtítulos de YouTube.
- Ordena esos fragmentos por relevancia con sus propios modelos.
Y lo hace rápido: Brave reporta menos de 130 ms de sobrecarga en el percentil 90 sobre una búsqueda normal, con una latencia total por debajo de 600 ms en p90 (Brave). Para un agente que encadena varias llamadas, esos milisegundos se suman, así que el número importa.
Hay un detalle que conviene subrayar si además de consumir contenido tú publicas contenido: en el paso de extracción, Brave prioriza los datos estructurados en JSON-LD por encima de casi todo lo demás. O sea, las páginas con schema.org bien puesto entran primero en el contexto que recibe el modelo. Lo menciono porque, si tienes un blog técnico, esto convierte una etiqueta <script type="application/ld+json"> de “estaría bien tenerla” a “ponla ya”. Lo desarrollé en otro artículo sobre por qué la IA cita pasajes y no páginas enteras.
La versión mínima: tu primera llamada
Vamos al código. Lo más simple que puedes hacer es una llamada directa al endpoint. Necesitas una llave de API, que sacas del panel de Brave (hablo del costo más abajo).
curl -s "https://api.search.brave.com/res/v1/llm/context?q=mejores+practicas+seguridad+kubernetes+2026" \
-H "Accept: application/json" \
-H "X-Subscription-Token: TU_API_KEY"En Python, la versión mínima de verdad cabe en unas pocas líneas:
import requests
def brave_context(query: str, api_key: str) -> dict:
"""Trae contexto pre-extraído del LLM Context API de Brave."""
resp = requests.get(
"https://api.search.brave.com/res/v1/llm/context",
headers={"Accept": "application/json", "X-Subscription-Token": api_key},
params={"q": query, "maximum_number_of_tokens": 4096},
timeout=30,
)
resp.raise_for_status()
return resp.json()Eso es todo lo que separa a tu computadora del índice de Brave. El parámetro maximum_number_of_tokens controla cuánto contexto te devuelve: el valor por defecto es 8192 y el rango va de 1024 a 32768. Para llamadas de agente que tienen que responder rápido, un presupuesto chico mantiene la respuesta ágil; para investigación profunda, lo subes (documentación de Brave).
La respuesta trae los fragmentos en grounding y la lista de fuentes en sources. Confieso que mi primer intento devolvió un error 422 porque mandé una query de más de 50 palabras: el límite es 400 caracteres y 50 palabras. Si vas a pasarle la pregunta entera del usuario sin filtrar, conviene recortarla antes.
Conectarlo a Claude con el Anthropic SDK
Una llamada suelta está bien, pero lo que quieres es que el modelo decida cuándo buscar. Para eso usamos el patrón de uso de herramientas del Anthropic SDK: le describimos a Claude una herramienta de búsqueda, y cuando el modelo decide que necesita información de la web, nos pide que la ejecutemos.
Primero defines la herramienta y haces la primera llamada al modelo:
import anthropic
client = anthropic.Anthropic() # lee ANTHROPIC_API_KEY del entorno
BUSQUEDA_WEB = {
"name": "buscar_web",
"description": "Busca contexto actualizado en la web. Úsala para hechos recientes o que cambian con el tiempo.",
"input_schema": {
"type": "object",
"properties": {"query": {"type": "string", "description": "La consulta de búsqueda"}},
"required": ["query"],
},
}
def preguntar(mensaje: str, api_key_brave: str) -> str:
historial = [{"role": "user", "content": mensaje}]
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=[BUSQUEDA_WEB],
messages=historial,
)Cuando Claude responde con stop_reason == "tool_use", significa que quiere que ejecutes la búsqueda. Tú llamas a Brave, le devuelves el resultado, y el modelo redacta la respuesta final con ese contexto:
while resp.stop_reason == "tool_use":
historial.append({"role": "assistant", "content": resp.content})
resultados_tool = []
for bloque in resp.content:
if bloque.type == "tool_use" and bloque.name == "buscar_web":
contexto = brave_context(bloque.input["query"], api_key_brave)
fragmentos = [
s for fuente in contexto.get("grounding", {}).get("generic", [])
for s in fuente.get("snippets", [])
]
resultados_tool.append({
"type": "tool_result",
"tool_use_id": bloque.id,
"content": "\n\n".join(fragmentos)[:6000],
})
historial.append({"role": "user", "content": resultados_tool})
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=[BUSQUEDA_WEB],
messages=historial,
)
return "".join(b.text for b in resp.content if b.type == "text")Y ya está. El modelo decide cuándo buscar, tú le acercas el contexto de Brave, y Claude responde fundamentado en datos frescos en vez de en lo que recordaba de su entrenamiento. La parte de “agente de IA” que suena tan sofisticada en las presentaciones es, vista de cerca, este bucle while. A veces la magia es solo un lazo que se repite hasta que el modelo deja de pedir cosas.
Llevarlo a producción sin sustos en la factura
Hasta aquí tienes algo que funciona en tu equipo. Antes de soltarlo en producción, dos cosas que aprendí a las malas: caché y límites de tasa.
Caché: tu primera línea de defensa contra la factura
Aquí toca hablar de plata, y con una corrección importante respecto a guías más viejas. Brave eliminó su nivel gratuito el 12 de febrero de 2026. Hoy el modelo es de facturación medida: cada plan incluye 5 dólares de créditos mensuales (alcanza para unas 1,000 búsquedas), y a partir de ahí se cobra a 5 dólares por cada 1,000 llamadas (implicator.ai). El dato que de verdad te tiene que quitar el sueño: la tarjeta que registraste como “verificación de identidad” ahora es un instrumento de cobro activo y no hay tope de gasto por defecto.
Traducción para tu agente autónomo: un bucle mal puesto que dispara búsquedas en cada iteración puede convertir una madrugada tranquila en una factura sorprendente. El antídoto más simple es la caché. Muchas consultas se repiten, y no tiene sentido pagar dos veces por la misma pregunta en una ventana corta:
import hashlib, time
_cache: dict[str, tuple[float, dict]] = {}
TTL = 3600 # una hora; ajústalo a qué tan fresco necesitas el dato
def brave_context_cacheado(query: str, api_key: str) -> dict:
clave = hashlib.sha256(query.lower().strip().encode()).hexdigest()
ahora = time.time()
if clave in _cache and ahora - _cache[clave][0] < TTL:
return _cache[clave][1]
datos = brave_context(query, api_key)
_cache[clave] = (ahora, datos)
return datosUn diccionario en memoria sirve para un proceso único. Si tienes varios procesos o reinicios frecuentes, mueve esto a Redis con el mismo esquema de clave por hash. El TTL es la perilla que de verdad importa: una hora está bien para noticias, pero para documentación técnica que cambia poco puedes subirlo a un día y ahorrar de verdad.
Límites de tasa: respeta la ventana
Brave aplica un límite de tasa con una ventana deslizante de un segundo. Si tu agente lanza ráfagas de búsquedas en paralelo, vas a chocar con errores 429. La defensa estándar es reintentar con espera exponencial, respetando los encabezados de la respuesta:
import time, requests
def brave_context_robusto(query: str, api_key: str, reintentos: int = 3) -> dict:
for intento in range(reintentos):
try:
return brave_context_cacheado(query, api_key)
except requests.HTTPError as e:
if e.response.status_code == 429 and intento < reintentos - 1:
time.sleep(2 ** intento) # 1s, 2s, 4s
continue
raiseCon caché y reintentos ya tienes algo que no se cae al primer pico de tráfico ni te vacía la cuenta en una noche. No es glamoroso, pero es la diferencia entre una demo y un servicio.
Para probar hoy
Si te queda una hora libre, este es el camino corto:
- Saca una llave de API en el panel de Brave y guárdala como variable de entorno.
- Copia la función
brave_contexty haz una llamada con cualquier pregunta que tenga respuesta reciente. - Compara los resultados con lo que te daría Google para la misma consulta: vas a ver sitios distintos en otro orden. Ese es justo el contenido que tu agente ve y tú no.
- Si publicas contenido técnico, abre tu propio blog en
search.brave.comy mira cómo aparece. Yo descubrí que un artículo que en Google estaba arriba, en Brave no salía, y al revés.
El punto de fondo es sencillo: el motor de búsqueda que alimenta a tu IA dejó de ser una caja negra de Google. Es un endpoint que puedes llamar, medir y ajustar tú mismo. Y por una vez, conectarlo de verdad cabe en una tarde.
Si quieres seguir por el lado de cómo se ve tu contenido para estos sistemas, escribí sobre cuántas IAs citaron mi blog y por qué solo 3 de 31 lo hicieron.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?