Por qué tu agente de IA no tiene 'sentido común' (y cómo se lo das con un knowledge graph)
Mi agente resume un paper académico como si tuviera un doctorado, pero si le paso una situación donde un colega dice “todo bien” mientras teclea con fuerza, me responde tan tranquilo: “perfecto, entonces no hay problema”. Inteligente, pero sin calle. Durante un tiempo pensé que el problema era mi prompt. No lo era. Lo que faltaba no era una instrucción mejor, sino una capa de conocimiento entera.
Esa capa tiene nombre: knowledge graph de sentido común. Y a diferencia de la mayoría de las cosas de moda en IA, esta sí te la puedo explicar con pasos concretos.
El RAG da datos. El sentido común da criterio.
Lo primero es dejar de pedirle al RAG algo que no le toca.
El RAG resuelve los datos que faltan. Si a tu agente le preguntan “¿quién desarrolló GraphRAG?” y la respuesta es “Microsoft Research”, eso se arregla buscando. Dato faltante, dato recuperado, listo.
El problema es que gran parte del razonamiento que hacemos los humanos no son datos que se buscan. Si yo te digo “supe que ella reprobó el examen”, tú deduces al instante “ha de estar triste”. En ningún lado dice “quien reprueba un examen se pone triste”. Eso no es un dato: es un supuesto implícito sobre cómo funciona el mundo. Y ahí el LLM, por más fluido que suene, falla más seguido de lo que admite.
Resumir, lo hace de maravilla. Leer lo que no se dijo, se le escapa. Karpathy lo bautizó “jagged intelligence”, inteligencia dentada: superhumana en una línea, y en la siguiente se equivoca en una cuenta de primaria.
La regla con la que yo me ordené esto es corta: el RAG llena lo que el agente no sabe, el knowledge graph de sentido común llena lo que el agente debería dar por obvio. No son competidores, son dos capas distintas.

ATOMIC, COMET y ECoK en orden práctico
Esta capa no es teoría nueva. Tiene una línea de herramientas que conviene conocer en orden, porque vas a usar una u otra según tu caso.
ATOMIC (Atlas of Machine Commonsense) es un knowledge graph de sentido común cotidiano. Para un evento, te da inferencias en formato si-entonces:
Evento: "PersonX reprueba un examen"
→ xReact (qué siente X): tristeza, decepción, vergüenza
→ xWant (qué quiere X): volver a intentarlo, buscar consuelo
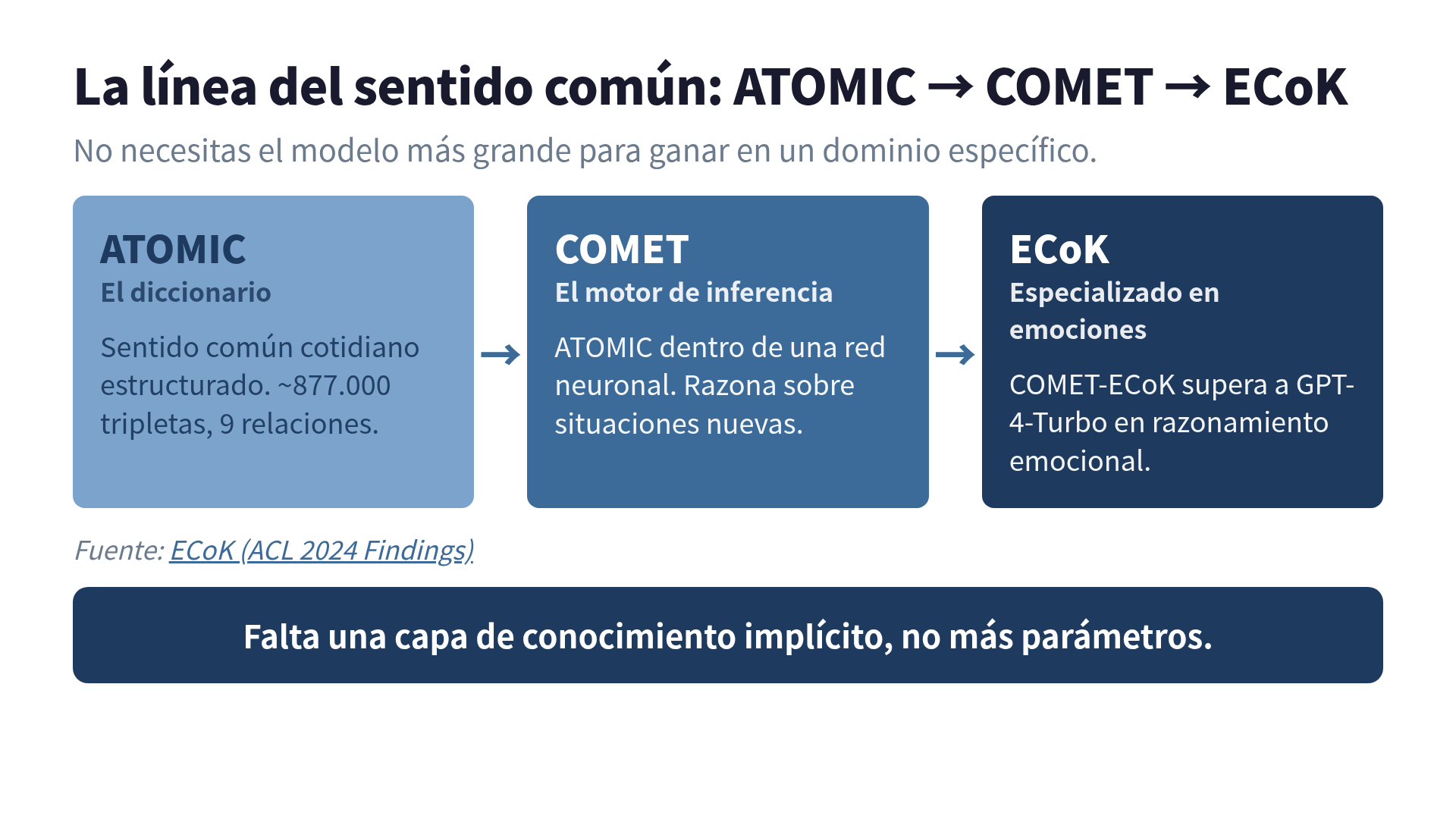
→ oReact (qué sienten los demás): preocupación, empatíaSon unas 877.000 tripletas con 9 tipos de relación. Piénsalo como un diccionario: lo consultas y te devuelve el sentido común.
COMET (COMmonsense Transformers) es ese diccionario entrenado dentro de una red neuronal, de modo que también razona sobre situaciones que no están en la tabla. Si ATOMIC es el diccionario, COMET es el motor de inferencia: le pasas “PersonX trabaja hasta la madrugada” y te devuelve “cansancio, sensación de logro, los demás se preocupan”, aunque ese evento exacto no estuviera cargado.
ECoK (Emotional Commonsense Knowledge Graph), presentado en ACL 2024 Findings, es la versión especializada en emociones. Integra teoría de psicología, ciencia cognitiva y lingüística, y estructura la emoción con intensidad, causa y objeto, no con una etiqueta plana.
El dato que a mí me hizo levantar la ceja: el modelo COMET-ECoK superó a GPT-4-Turbo en tareas de razonamiento emocional. Un LLM gigante saca “ocho de diez en todo”; un knowledge graph especializado saca “nueve y medio, pero solo en lo suyo”. Para alguien que construye solo, es una noticia sorprendentemente alentadora: no necesitas el modelo más grande del planeta para ganarle en un dominio específico.
Cómo lo agregas a tu agente (y cuándo no deberías)
La parte de implementación, sin adornos. El patrón que a mí me terminó funcionando trata al LLM y al knowledge graph como complementos.
Si dejas todo en manos del LLM, terminas con ese colega que afirma con total seguridad que la Torre de Tokio mide 634 metros: está equivocado, pero el tono es impecable. El knowledge graph es el verificador callado que se sienta a su lado. Y al revés: el knowledge graph es malísimo para que le hagas preguntas en lenguaje natural, y ahí el LLM lo rescata.
El flujo mínimo queda así:
- Pasa el evento o el mensaje por COMET. De una entrada como “todavía no tengo el documento listo” sacas inferencias del tipo xReact = [ansiedad, apuro, culpa].
- Inyecta esas inferencias en el contexto del agente como nodos adicionales, no como un párrafo suelto. Arquitecturas como CEICG modelan la conversación como grafo y combinan tres tipos de aristas (temporal, de hablante y de sentido común) para que el agente vea contexto y conocimiento implícito a la vez.
- No mezcles las capas. Los datos van al RAG; lo implícito, al knowledge graph de sentido común. No metas las dos cosas en un mismo prompt rogando que el modelo “lo resuelva solo”.
¿Y cuándo no vale la pena? Si tu agente solo responde preguntas factuales (precios, documentación, definiciones), el RAG te alcanza y agregar un knowledge graph de sentido común es sobreingeniería. La capa de criterio recién se justifica cuando tu caso de uso depende de leer causas, emociones o supuestos que nadie escribió: soporte al cliente, salud mental, asistentes que tienen que captar el tono. Ahí sí, es la diferencia entre un bot que contesta y uno que entiende.
En resumen
- El RAG llena los datos que faltan; el knowledge graph de sentido común llena lo que el agente debería dar por obvio. Son capas distintas.
- La línea ATOMIC (diccionario) → COMET (motor de inferencia) → ECoK (especializado en emociones) es el camino, y COMET-ECoK ya le ganó a GPT-4-Turbo en razonamiento emocional.
- Para integrarlo: pasa el mensaje por COMET, inyecta las inferencias como nodos en el contexto y mantén separadas las dos capas.
- No lo agregues por moda. Si tu caso es solo factual, el RAG basta. La capa de criterio se justifica cuando hay que leer lo que no se dijo.
Que tu agente sea “inteligente pero sin calle” no se arregla esperando un modelo más grande. Lo que falta no son más parámetros, sino una capa de conocimiento implícito estructurada. Y esa, hoy, ya la puedes construir.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?