LLMO en 15 minutos: llms.txt + JSON-LD para que la IA pueda encontrar tu sitio
La primera vez que leí sobre LLMO me senté frente a la computadora con toda la motivación del mundo y pasé 90 minutos sin escribir una sola línea. No porque fuera difícil: porque cada artículo me mandaba a leer otros tres. La implementación real, cuando por fin la hice, tomó 15 minutos. Este artículo es la versión que me hubiera ahorrado los otros 75.
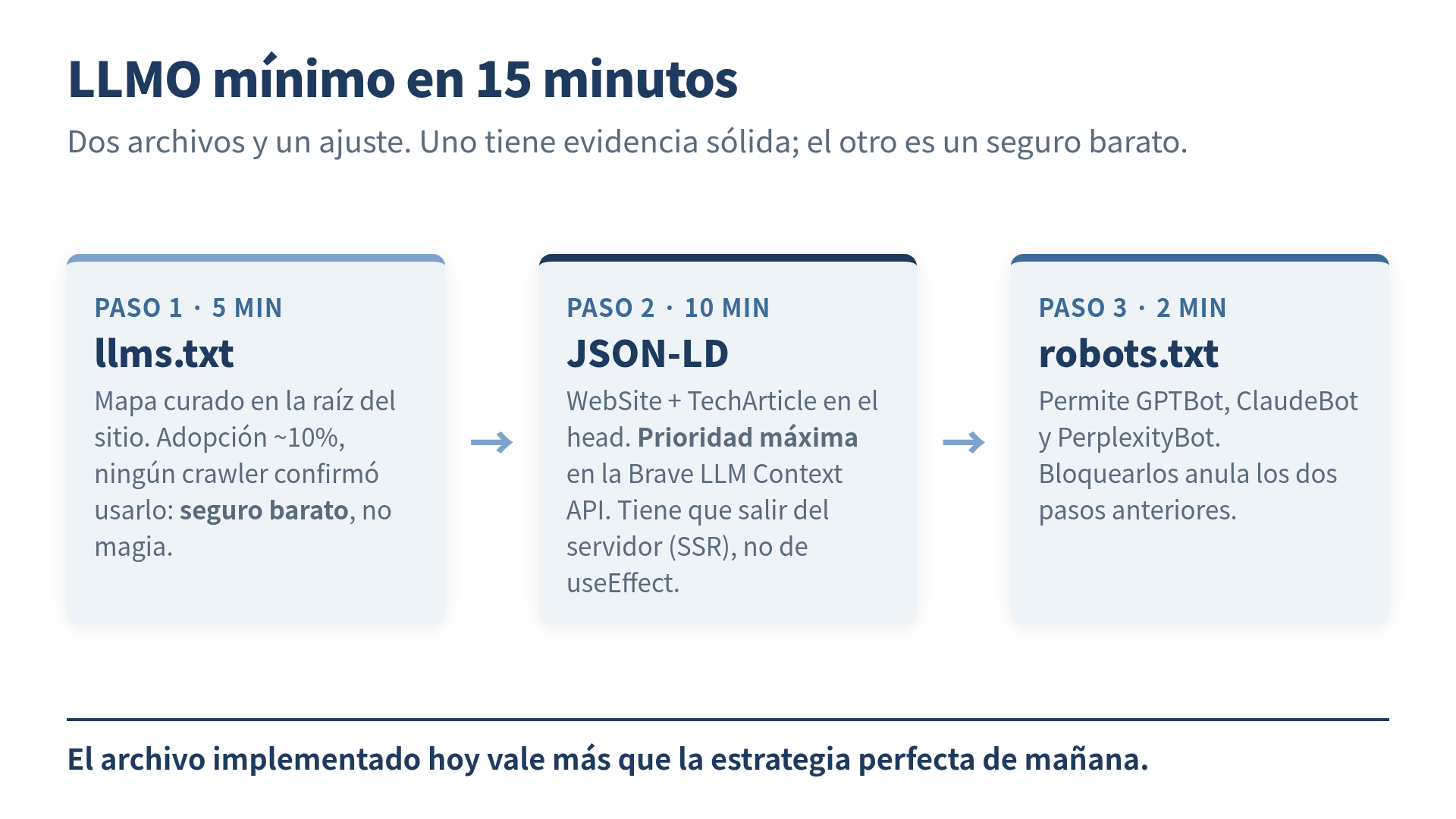
La premisa es simple: tu sitio puede posicionarse bien en Google y aun así ser invisible cuando alguien le pregunta a ChatGPT, Claude o Perplexity. Son canales distintos con reglas distintas. La base mínima para el canal de IA son dos archivos y un ajuste, y los tres caben en una tarde corta.
No quiero venderte humo: de las dos técnicas de hoy, una tiene evidencia sólida y la otra es un seguro barato. Te digo cuál es cuál en cada sección.
Paso 1: llms.txt (5 minutos, expectativas honestas)
llms.txt es un archivo Markdown que colocas en la raíz de tu sitio (tusitio.com/llms.txt). Funciona como un mapa curado: le dice a un modelo de lenguaje qué es tu sitio y cuáles son las 10-20 páginas que de verdad importan, sin el ruido de navegación, anuncios y JavaScript.
La estructura mínima tiene dos elementos obligatorios y el resto es opcional:
# Nombre del sitio
> Descripción del sitio en una o dos frases.
## Artículos principales
- [Título del artículo](URL): descripción breve
- [Título del artículo](URL): descripción breve
## Sobre el autor
- [Perfil](URL): experiencia y contactoRequisitos técnicos: UTF-8, servido como text/plain, HTTPS, idealmente menos de 10 KB. Eso es todo.
Ahora los datos incómodos, porque existen. Un análisis de SE Ranking sobre 300,000 dominios encontró que cerca del 10% ya tiene un llms.txt. Pero John Mueller, de Google, señaló que ningún crawler de IA ha confirmado públicamente que extrae información de este archivo, y Google declaró que no planea adoptarlo. En una medición de 500 millones de visitas de bots de IA, apenas 408 pidieron el llms.txt directamente.
Aun así, yo lo implemento por la misma razón que se contrata un seguro antes del incendio y no después: cuesta 5 minutos, no tiene ninguna desventaja para tu SEO actual, y si los motores de IA lo adoptan mañana, tú ya estás en la fila. Solo que no le cuento a nadie que eso “me posicionó en ChatGPT”, porque sería mentira.
Si después quieres ver cómo NO escribirlo, audité 30 archivos llms.txt en producción y encontré 5 anti-patrones repetidos, incluyendo tres errores que yo mismo había cometido.
Paso 2: JSON-LD (10 minutos, aquí sí hay evidencia)
El JSON-LD es un formato de metadatos estructurados que insertas en el <head> de tus páginas usando el vocabulario de schema.org. A diferencia del llms.txt, aquí hay un mecanismo confirmado: la Brave LLM Context API, que alimenta de contexto a varios asistentes de IA, extrae datos estructurados con prioridad máxima, por encima de tablas, snippets y bloques de código. Si tu página tiene JSON-LD, esa es la versión de tu contenido que el motor lee primero.
Para un blog técnico bastan dos esquemas. El primero, WebSite, va en la página principal:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebSite",
"name": "Tu Sitio",
"url": "https://tusitio.com",
"description": "Descripción de tu sitio en una frase."
}
</script>El segundo, TechArticle (o Article), va en cada artículo:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "Título del artículo",
"author": {
"@type": "Person",
"name": "Tu Nombre",
"url": "https://tusitio.com/about",
"jobTitle": "Ingeniera de software"
},
"datePublished": "2026-06-01T09:00:00-06:00",
"dateModified": "2026-06-13T10:00:00-06:00",
"description": "Resumen del artículo en una o dos frases."
}
</script>Dos campos merecen atención especial. dateModified es el más importante: los motores de respuesta favorecen contenido fresco, y en Perplexity la frescura pesa cerca del 40% del ranking. Y en author, incluir url y jobTitle le da al modelo señales de quién escribe y con qué autoridad.
En Astro o Next.js, esto se genera desde el frontmatter de cada artículo. Ejemplo para Astro:
---
const jsonLd = {
"@context": "https://schema.org",
"@type": "TechArticle",
headline: post.data.title,
datePublished: post.data.date,
dateModified: post.data.updated ?? post.data.date,
};
---
<script type="application/ld+json" set:html={JSON.stringify(jsonLd)} />La trampa clásica: insertar el JSON-LD con JavaScript del lado del cliente. La mayoría de los crawlers de IA no ejecuta JavaScript, así que un esquema inyectado con useEffect es invisible justo para el público al que va dirigido. Tiene que salir renderizado del servidor o generado en el build. Es el equivalente digital de imprimir tu carta de presentación con tinta invisible: técnicamente existe, nadie la puede leer.
Paso 3: robots.txt (2 minutos, el que anula todo lo demás)
Este paso es defensivo: si tu robots.txt bloquea a los crawlers de IA, los dos pasos anteriores no sirvieron de nada. Verifica que estos agentes tengan permiso:
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /Los crawlers de IA ya generan un volumen de peticiones equivalente al 20% de Googlebot. Bloquearlos por accidente (algunas plantillas y CDNs lo hacen por defecto) te borra del canal completo.
Verificación: cómo saber que funcionó
Tres chequeos rápidos cierran la implementación:
- JSON-LD válido: pega la URL de un artículo en el Rich Results Test de Google. Si detecta el Article, el esquema está bien formado.
- llms.txt accesible: abre
tusitio.com/llms.txten el navegador. Debe responder 200 y verse como texto plano. - Crawlers llegando: en tus logs de servidor (o en el panel de tu CDN), busca user-agents como
GPTBotyClaudeBotdurante las siguientes dos semanas. Si aparecen, la puerta está abierta.
Qué sigue después de los 15 minutos
Esta es la base mínima, no la estrategia completa. Lo que viene después (estructura de contenido citable, medición de citas por motor, esquemas FAQ y HowTo) está sistematizado en llmoframework.com, el framework LLMO que mantengo como referencia abierta, con plantillas para cada fase.
Pero no subestimes la base. La diferencia entre “implementé algo hoy” y “sigo leyendo artículos sobre el tema” es exactamente la diferencia entre mis 15 minutos productivos y mis 90 minutos de lectura motivacional. El archivo de hoy vale más que la estrategia de mañana.
Y si un día un motor de IA cita tu sitio gracias al JSON-LD, puedes contarle a todo el mundo que fue por el llms.txt. Total, nadie puede verificarlo todavía.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?