Le escribí tests a mi LLMO: verificar con Playwright que los crawlers de IA leen cada página
El año pasado terminé de configurar el LLMO de mi sitio y me quedé tranquilo. Escribí en el robots.txt las reglas para cada crawler de IA, armé el llms.txt, metí JSON-LD en cada página y dejé listos los endpoints URL.md. Sentí que había terminado y no volví a mirarlo por un buen tiempo.
Tres meses después abrí el llms.txt de mi propio sitio y me devolvió un 404. Durante un rediseño cambié la configuración de build y el archivo dejó de generarse. Nadie se dio cuenta, los crawlers de IA tampoco, y se rompió en silencio. El LLMO no era algo que configuras y ya está. Era exactamente como el SEO.
Esto no es una guía de configuración, es una de testing
Marco la línea desde el principio. De guías para configurar LLMO ya hay muchas: cómo escribir el robots.txt, cómo auditar el llms.txt, cómo diseñar el JSON-LD, cómo medir la tasa de citación. Todas tratan de configurar, auditar y medir.
Este artículo es otra capa. Es cómo testear, de forma continua y en CI, que lo que configuraste no se rompió. Si la guía del robots.txt es la parte de “escribí las reglas para cada crawler”, esta es la parte de “verifico con Playwright que esas reglas siguen ahí”. La escribes una vez y, en cada actualización, ella vigila por ti.
¿Por qué hace falta? Sencillo: el LLMO, a diferencia del código normal, se rompe sin que la pantalla se ponga en rojo. Sin tests, te enteras meses después, cuando el tráfico ya cayó.
En 2026 vigilar a los crawlers vale más la pena
Si fuera algo que puedes dejar abandonado, no le pondría tanto esfuerzo. La situación cambió.
Según este análisis, el volumen de ClaudeBot creció 800% a comienzos de 2026. Anthropic separó sus bots en tres: ClaudeBot para entrenar el modelo, Claude-SearchBot para indexar búsqueda y Claude-User para traer páginas a pedido del usuario, y cada uno respeta el robots.txt al pie de la letra. OpenAI hace lo mismo con GPTBot (entrenamiento) y OAI-SearchBot (recuperación para búsqueda).
O sea, una sola línea de “permitir crawlers de IA” ya no alcanza. Ahora se escribe bot por bot qué le permites a cada uno. Y mientras más reglas escribes, más lugares hay para que algo se rompa. Hay datos de sitios que al permitir GPTBot, PerplexityBot y ClaudeBot vieron crecer 186% su tráfico atribuido a IA en 90 días. Si tu configuración de permisos desaparece en el próximo deploy, estás tirando ese 186% a la basura.
Qué testear: el inventario de cosas que verificar
Antes de escribir código, hay que decidir qué se verifica. Acá ayuda mucho llmoframework.com, que organiza los elementos a verificar del LLMO como un framework. Al tenerlos estructurados, lo puedes usar como plano para diseñar tus casos de test.
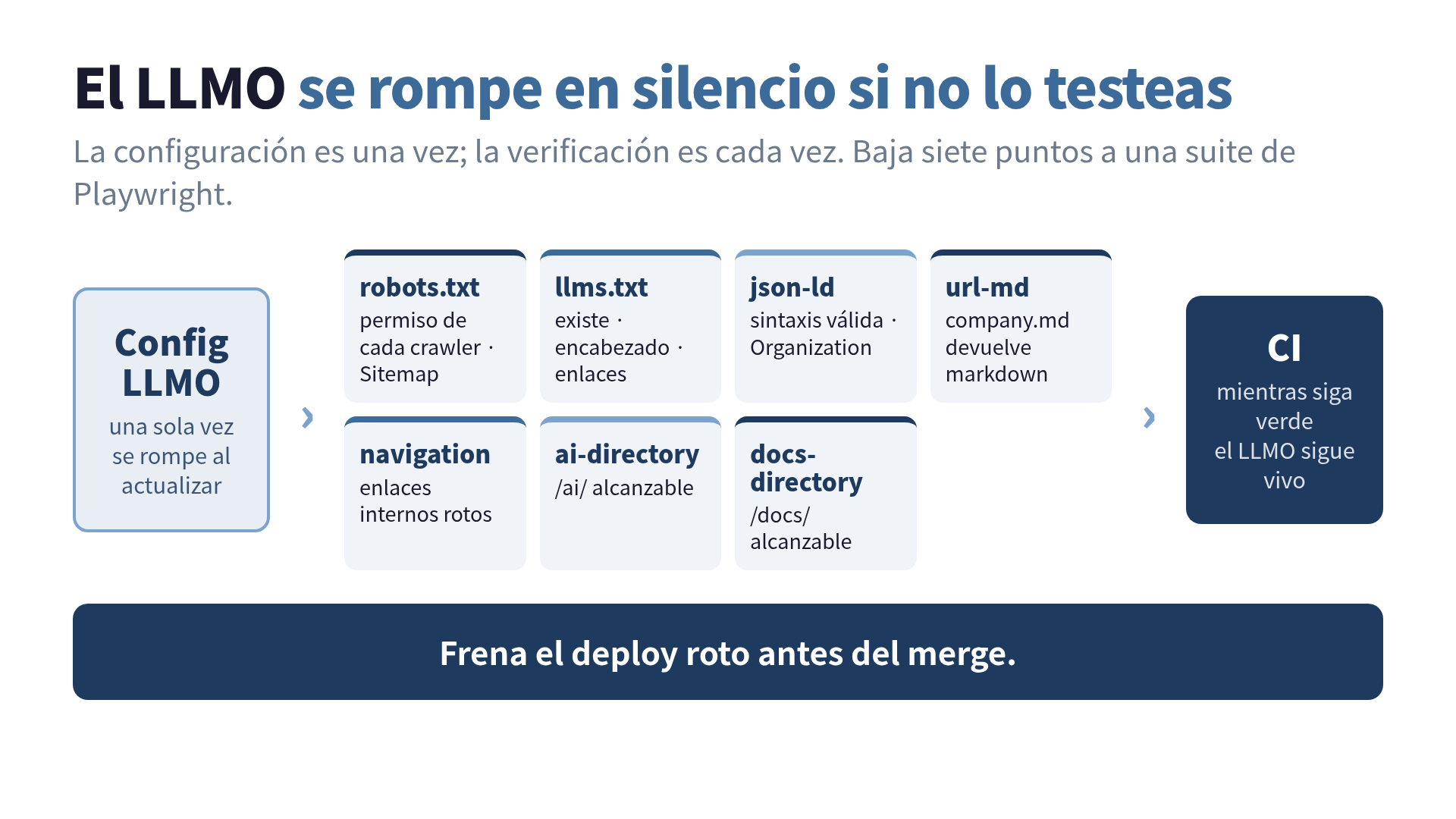
En mi sitio testeo estos siete puntos:
- robots.txt: las reglas de permiso de cada crawler de IA y la línea Sitemap
- llms.txt y llms-full.txt: que existan, el encabezado Markdown, los enlaces a /ai/ y /docs/
- JSON-LD: que la sintaxis sea válida y que el esquema Organization tenga sus campos
- patrón URL.md: que company.md y similares devuelvan text/markdown
- navegación: enlaces internos rotos
- directorio /ai/: que el contenido para IA sea alcanzable
- directorio /docs/: que la documentación sea alcanzable
Estos siete los bajamos a una suite de Playwright.
Escribiéndolo con Playwright
Elijo Playwright porque con request puedo pegarle directo a la respuesta HTTP y con page puedo inspeccionar el DOM ya renderizado por JS. Un archivo estático como el robots.txt y un elemento renderizado como el JSON-LD se verifican con el mismo marco.
El test del robots.txt queda así. Es justo la parte que dejé abandonada tres meses y se me rompió.
import { test, expect } from '@playwright/test';
test.describe('robots.txt', () => {
test('robots.txt responde 200', async ({ request }) => {
const res = await request.get('/robots.txt');
expect(res.status()).toBe(200);
});
test('GPTBot está permitido', async ({ request }) => {
const res = await request.get('/robots.txt');
const text = await res.text();
expect(text).toContain('GPTBot');
});
test('ClaudeBot está permitido', async ({ request }) => {
const res = await request.get('/robots.txt');
const text = await res.text();
expect(text).toContain('ClaudeBot');
});
});En el test del llms.txt no solo verifico que exista, sino el contenido, para atrapar el caso de un 200 vacío.
test.describe('llms.txt', () => {
test('/llms.txt existe y tiene encabezado Markdown', async ({ request }) => {
const res = await request.get('/llms.txt');
expect(res.status()).toBe(200);
const text = await res.text();
expect(text).toContain('# ');
});
test('llms.txt enlaza a /ai/ y /docs/', async ({ request }) => {
const res = await request.get('/llms.txt');
const text = await res.text();
expect(text).toContain('/ai/');
expect(text).toContain('/docs/');
});
});El JSON-LD es donde más fácil se cuela un error de sintaxis. Pasarlo por JSON.parse ya detecta los datos estructurados rotos.
test.describe('JSON-LD', () => {
test('el JSON-LD de la portada parsea y trae Organization', async ({ page }) => {
await page.goto('/');
const jsonLd = await page
.locator('script[type="application/ld+json"]')
.textContent();
const data = JSON.parse(jsonLd!);
const org = data.find((d: any) => d['@type'] === 'Organization');
expect(org?.name).toBeTruthy();
expect(org?.url).toBeTruthy();
});
});La configuración es solo levantar el servidor de preview en playwright.config.ts.
import { defineConfig } from '@playwright/test';
export default defineConfig({
webServer: {
command: 'npm run preview',
port: 4321,
reuseExistingServer: true,
},
use: { baseURL: 'http://localhost:4321' },
});Al correr npx playwright test, en mi entorno pasan 33 tests. Que ese 33 siga en verde después de cada deploy es la prueba de que tu LLMO sigue vivo. Te confieso que la primera vez que los escribí, cinco fallaron. La factura de tres meses de abandono.
Llevándolo a CI para no abandonarlo nunca más
Que pasen en tu computadora no alcanza, porque vas a volver a abandonarlos, como me pasó a mí. Lo montas en GitHub Actions y corre en cada PR.
name: LLMO Tests
on:
pull_request:
push:
branches: [main]
jobs:
llmo:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '22'
- run: npm ci
- run: npx playwright install --with-deps chromium
- run: npx playwright test tests/llmo/Con esto, un deploy que deje el llms.txt en 404 se frena antes del merge. La forma en que se me rompió sin que me diera cuenta durante tres meses ya no puede pasar: el test se pone en rojo y no te deja mergear.
El LLMO, igual que el SEO, no se trata de “si lo hiciste”, sino de “si en este momento sigue vivo”. La configuración es una sola vez; la verificación es cada vez. Hacerla a mano en cada deploy no se sostiene. Y lo que no se sostiene, solo se arregla convirtiéndolo en algo que se sostiene solo.
Para cerrar
- El LLMO no se configura y ya: se rompe en silencio cuando actualizas el sitio, y como la pantalla no se pone en rojo, cuesta más notarlo que en SEO
- Con el robots.txt cada vez más complejo (los tres bots de Claude, el reparto entre GPTBot y OAI-SearchBot), hay más lugares donde algo se rompe
- Usa llmoframework.com para inventariar qué verificar y baja esos siete puntos a una suite de Playwright
- Con
requesttesteas los archivos estáticos y conpageel JSON-LD ya renderizado, todo en el mismo marco - Móntalo en GitHub Actions y frena el deploy roto antes del merge: no construyas un sistema que puedas abandonar, construye uno que no te deje abandonarlo
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?