Ejecuté 3 sesiones de Claude Code en paralelo durante 8 horas. Se sobrescribieron 2 veces. Guía LatAm de orquestación segura.
Tenía tres ideas en paralelo y tres terminales abiertas. La cuenta parecía obvia: abrir tres sesiones de Claude Code, una por worktree, dejar que cada una trabajara en una branch independiente, y subir más o menos 3x mi throughput de la tarde. La documentación oficial recomienda exactamente eso. La app de escritorio crea worktree automáticamente para cada sesión nueva. Está presentado como el patrón seguro.
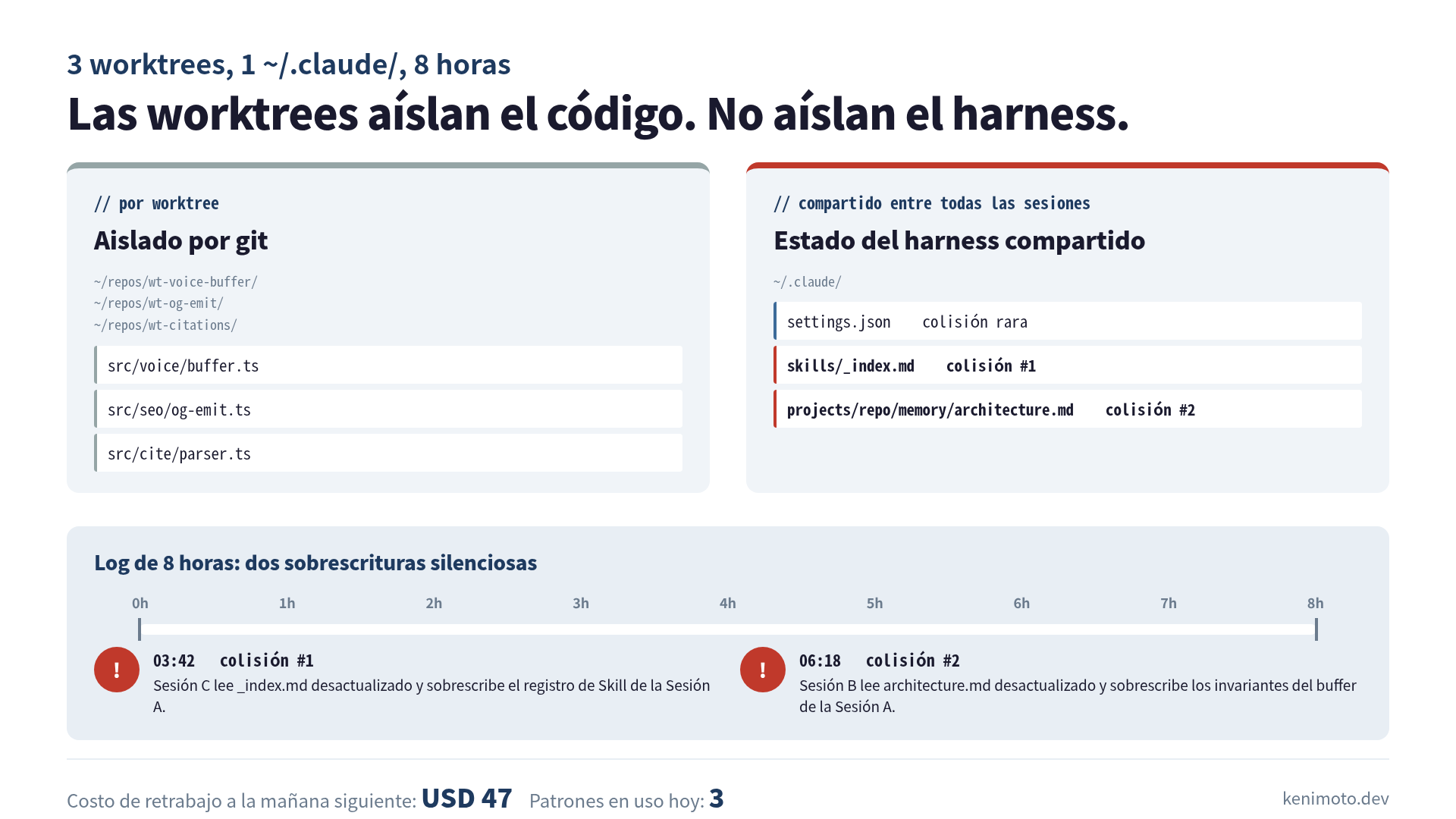
Ocho horas después tenía dos archivos de memoria corruptos, un archivo de Skill con un párrafo que nunca escribí, y una factura de aproximadamente USD 47 en tokens rehaciendo trabajo que ya existía en otra worktree. La configuración era segura sobre el papel. El estado compartido no.
Este post es el log de las 8 horas. Qué configuré, cuándo ocurrieron las dos colisiones, qué se estaba sobrescribiendo en realidad, y los tres patrones pequeños que uso ahora para evitar que sesiones paralelas se coman entre sí.
La configuración que parecía segura
Tres sesiones de Claude Code, cada una en una worktree separada del mismo repositorio. Tres branches: feat/voice-buffer, fix/og-emit, feat/citation-tracker. Ninguna branch tocaba los mismos archivos fuente. Lo verifiqué dos veces antes de empezar.
# Terminal A
git worktree add ../wt-voice-buffer feat/voice-buffer
cd ../wt-voice-buffer && claude
# Terminal B
git worktree add ../wt-og-emit fix/og-emit
cd ../wt-og-emit && claude
# Terminal C
git worktree add ../wt-citations feat/citation-tracker
cd ../wt-citations && claudeCada sesión leía el mismo contexto de sistema: el CLAUDE.md del repositorio, el ~/.claude/CLAUDE.md de usuario, el directorio ~/.claude/skills/, y el directorio ~/.claude/projects/<repo>/memory/. Las worktrees están aisladas en la capa de git. Todo lo demás queda compartido.
Me di cuenta de la implicación recién en la hora 8, con un archivo de memoria corrupto abierto en la pantalla. Las worktrees aíslan el código fuente. No aíslan el “cerebro” del Claude.
Colisión 1: hora 3, el archivo de Skill
Lo primero en romperse fue un archivo de Skill que no había tocado en todo el día.
La sesión A estaba arreglando el voice buffer y en algún momento se preguntó: “¿hay alguna Skill para buffers de streaming WebRTC?”. No había. Escribió una nueva en ~/.claude/skills/voice-buffer/SKILL.md y siguió trabajando. En la misma ventana de unos 8 minutos, la sesión C armaba el citation tracker y se preguntó: “¿hay alguna Skill para parsear atribuciones de fuente?”. No había. Escribió una en ~/.claude/skills/citation-source/SKILL.md.
Hasta ahí ninguna colisión. Archivos distintos, temas distintos. La documentación oficial no me daba motivo para sospechar.
La colisión vino de un tercer archivo: ~/.claude/skills/_index.md, que ambas sesiones decidieron actualizar al registrar la Skill nueva. La sesión A escribió primero. La sesión C, leyendo el archivo 30 segundos después, vio la versión previa a la escritura de A, agregó su propia Skill y guardó. El registro de la Skill voice-buffer desapareció del índice. La sesión A no tenía cómo enterarse, porque ya había pasado a la siguiente tarea.
Me enteré en la hora 5 cuando le pregunté a la sesión B (que estaba en silencio con el fix del OG): “¿el índice de Skills ya incluye voice-buffer?”. Respondió que no. Lo confirmé. Estaba en lo cierto. El archivo de Skill que escribió A estaba en disco, pero el índice que apuntaba ahí había sido sobrescrito.
Así se ve un estado compartido sin lock. Dos escritores, last-write-wins, sin aviso, sin merge.
Colisión 2: hora 6, el archivo de memoria
La segunda colisión fue peor, porque se comió trabajo que quería conservar.
Uso ~/.claude/projects/<repo>/memory/ para guardar notas pequeñas y persistentes que el agente debería recordar entre sesiones: un architecture.md con el mapa de componentes, un feedback.md con preferencias de estilo, un project.md con prioridades actuales. Los tres los escribe el propio Claude, ocasionalmente, cuando la persona usuaria dice “recuerda esto” o cuando el agente decide por su cuenta que algo vale la pena guardar.
A la hora 6
, la sesión A terminó el trabajo en voice buffer y se preguntó: “¿debería guardar lo que aprendí sobre los invariantes del buffer de audio?”. Leyóarchitecture.md, agregó una sección, guardó. A la hora 6, la sesión B terminó el fix del OG y se preguntó: “¿debería registrar el bug del doble og como gotcha conocido?”. Leyó architecture.md (la versión pre-A, todavía en caché en su contexto), agregó su propia sección, guardó.
Las notas de voice buffer de A desaparecieron. Ocho minutos de invariantes cuidadosos, fuera, reemplazados por un párrafo sobre emisión de meta tag que era correcto pero de otro tema.
Solo lo pesqué porque, a la mañana siguiente, hice grep de “buffer invariant” y no apareció nada. Si no hubiera buscado, las notas simplemente no existirían en ninguna sesión futura de Claude Code. El agente nunca habría sabido que tenía que preguntar. No hay log de error para “archivo de memoria sobrescrito en silencio por proceso hermano”.
Qué estaba realmente roto
Las worktrees resuelven el problema del filesystem. Dos sesiones escribiendo el mismo src/voice/buffer.ts generarían un conflicto de git, que es ruidoso y recuperable. Dos sesiones escribiendo el mismo ~/.claude/skills/_index.md generan un overwrite silencioso, que es mudo y no.
En concreto, la premisa rota era esta. La guía oficial dice que “las ediciones en una sesión nunca tocan archivos de otra”, y eso es cierto en la capa de worktree. No es cierto en la capa del harness, porque el harness (memoria, skills, hooks, settings) vive un directorio por encima de la worktree, en ~/.claude/, donde cada sesión paralela escribe libremente sin coordinación.
Tres clases de archivo quedan en riesgo, en orden creciente de cuánto van a doler:
- Archivos de configuración (
~/.claude/settings.json). Colisión rara porque el agente casi no escribe acá. Pero cuando escribe (por ejemplo una Skill pide un permiso nuevo), es last-write-wins. - Archivos de Skills (
~/.claude/skills/). Frecuencia media. El punto real de ignición son los índices y catálogos compartidos, no los archivos SKILL.md individuales. - Archivos de memoria (
~/.claude/projects/<repo>/memory/). El más doloroso. El agente escribe ahí justo cuando acaba de aprender algo que considera valioso, que es exactamente el trabajo que no quieres perder.
El patrón de worktree paralelo de Anthropic se pensó para código. El harness se pensó para una sesión por vez. Correr las dos cosas a la vez es bug del usuario.
La lección de USD 47
El costo en plata fue el retrabajo. Después de la colisión del archivo de memoria, la sesión A no tenía registro de los invariantes de voice buffer que acababa de derivar. Cuando arranqué una sesión nueva a la mañana siguiente y le pedí que extendiera el buffer, rederivó los mismos invariantes desde cero, casi del mismo modo, en unos 40 minutos de tokens quemados. Miré el dashboard: alrededor de USD 47 en Sonnet 4.6, más una mañana levemente agria.
Por supuesto también pagué la derivación original. Así que, estrictamente, el trabajo no se “perdió”, se “pagó dos veces”. La segunda factura era la evitable. La Ley de Brooks tiene un pie de página que nadie cita: “y tus procesos concurrentes van a sobrescribirse las notas, así que vas a pagar parte del trabajo dos veces”.
Checklist LatAm: decisión paso a paso antes de abrir la segunda terminal
Esta es la parte educativa que me hubiera gustado tener antes de las 8 horas. Antes de abrir la segunda sesión de Claude Code en una segunda worktree, recorre estos cinco puntos.
- ¿Las dos sesiones leen el mismo
~/.claude/CLAUDE.md? Si sí, cualquier escritura del agente en ese archivo será un overwrite silencioso. Decide ahora si te molesta. - ¿Las dos sesiones escriben en
~/.claude/skills/o en su índice? Si sí, aplica el Patrón 2 (write lock) antes de empezar. - ¿Las dos sesiones escriben en
~/.claude/projects/<repo>/memory/? Si sí, aplica el Patrón 1 (namespace por sesión) antes de empezar. - ¿Tienes permisos del agente compartidos en
~/.claude/settings.json? Si sí, acepta que el último que escriba gana, o aplica el Patrón 2 también ahí. - ¿Cuántas sesiones quieres en paralelo? Por encima de 4 simultáneas, la documentación oficial te sugiere parar. Acá la sugerencia no es performance: es revisión humana. Tres reportes ya cuestan una hora de merge.
Los 3 patrones que uso ahora
Después del día de la colisión, cambié tres cosas. Cada una es chica. Ninguna requirió que Anthropic enviara algo nuevo.
Patrón 1: namespaces de memoria por sesión. En vez de un ~/.claude/projects/<repo>/memory/ compartido, cada sesión paralela escribe dentro de ~/.claude/projects/<repo>/memory/<branch-name>/. Lo hago con un CLAUDE.md por worktree que le indica al agente su subdirectorio. Al cerrar la sesión, hago merge del subdirectorio al memory/ principal a mano o con un script chico. Los conflictos aparecen como nombres de archivo duplicados, que es ruidoso y recuperable.
<!-- CLAUDE.md por worktree -->
## Ubicación de escritura de memoria
Escribe todos los archivos de memoria en
`~/.claude/projects/repo/memory/feat-voice-buffer/`.
No escribas directo en `~/.claude/projects/repo/memory/`.Patrón 2: write lock en los índices compartidos. Para archivos que no puedo separar por namespace (el índice de Skills, settings.json), uso un lock al estilo flock alrededor de cada escritura del agente. El agente escribe a través de un wrapper de shell chico que toma lock exclusivo en ~/.claude/locks/skills-index.lock antes de tocar el archivo. Last-write sigue ganando, pero las escrituras quedan serializadas, y el read previo del agente ve un estado consistente. El wrapper son unas 20 líneas de shell.
#!/usr/bin/env bash
# ~/.claude/bin/locked-write.sh
target="$1"
lockfile="$HOME/.claude/locks/$(basename "$target").lock"
mkdir -p "$(dirname "$lockfile")"
exec 9>"$lockfile"
flock 9
cat > "$target"Patrón 3: coordinación vía .claude/sessions/. Cada sesión en ejecución escribe un archivo de heartbeat en ~/.claude/sessions/<pid>.json con su branch, hora de inicio y los archivos que espera tocar en la capa del harness. Antes de escribir en un índice compartido o un archivo de memoria, la sesión hace grep en el directorio sessions/ buscando reclamos de procesos hermanos sobre la misma ruta. Si encuentra alguno, espera o saltea. Es el más pesado de los tres y el que menos uso, porque los Patrones 1 y 2 atrapan la mayoría de las colisiones reales.
Si ya usaste sub-agentes de Claude Code para revisión paralela, reconoces la forma. El problema no es el modelo. Es la capa de integración que la persona usuaria no sabía que estaba ahí. Los sub-agentes chocan en opiniones dentro de una sesión; las sesiones paralelas chocan en estado a lo largo del harness.
En qué creo ahora, en serio
Las sesiones paralelas de Claude Code no son gratis, igual que la code review multi-agente no lo es, igual que dejar un agente funcionando 24 horas no lo es. El costo se mueve de lugar, pero nunca baja a cero. En sesiones paralelas, el costo aparece como overwrite silencioso en tu directorio de harness, 8 horas después de empezar, en un archivo en el que ni pensaste cuando abriste la segunda terminal.
El encuadre de la guía oficial es correcto en la capa de código fuente: “las ediciones en una sesión nunca tocan archivos de otra”. Solo se detiene un directorio antes. Las ediciones dentro de ~/.claude/ están encantadas de tocarse entre sí, y lo van a hacer, en el cronograma de last-write-wins, sin log de error que puedas grep después.
Si te llevas una sola cosa de este post: cuando abras la segunda sesión de Claude Code en la segunda worktree, dedica diez segundos a decidir si las dos sesiones comparten Skills, memoria o settings, y si te molesta que cualquiera de las dos se trague en silencio las escrituras de la otra. Si te molesta, agrega el Patrón 1 hoy y el Patrón 2 el primer día en que pegues una colisión real. El Patrón 3 puede esperar a que te encuentres corriendo cinco en paralelo, que es donde la documentación oficial te aconseja amablemente que no lo hagas.
Sigo corriendo sesiones en paralelo. Solo dejé de fingir que el límite de la worktree era el límite entero.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?