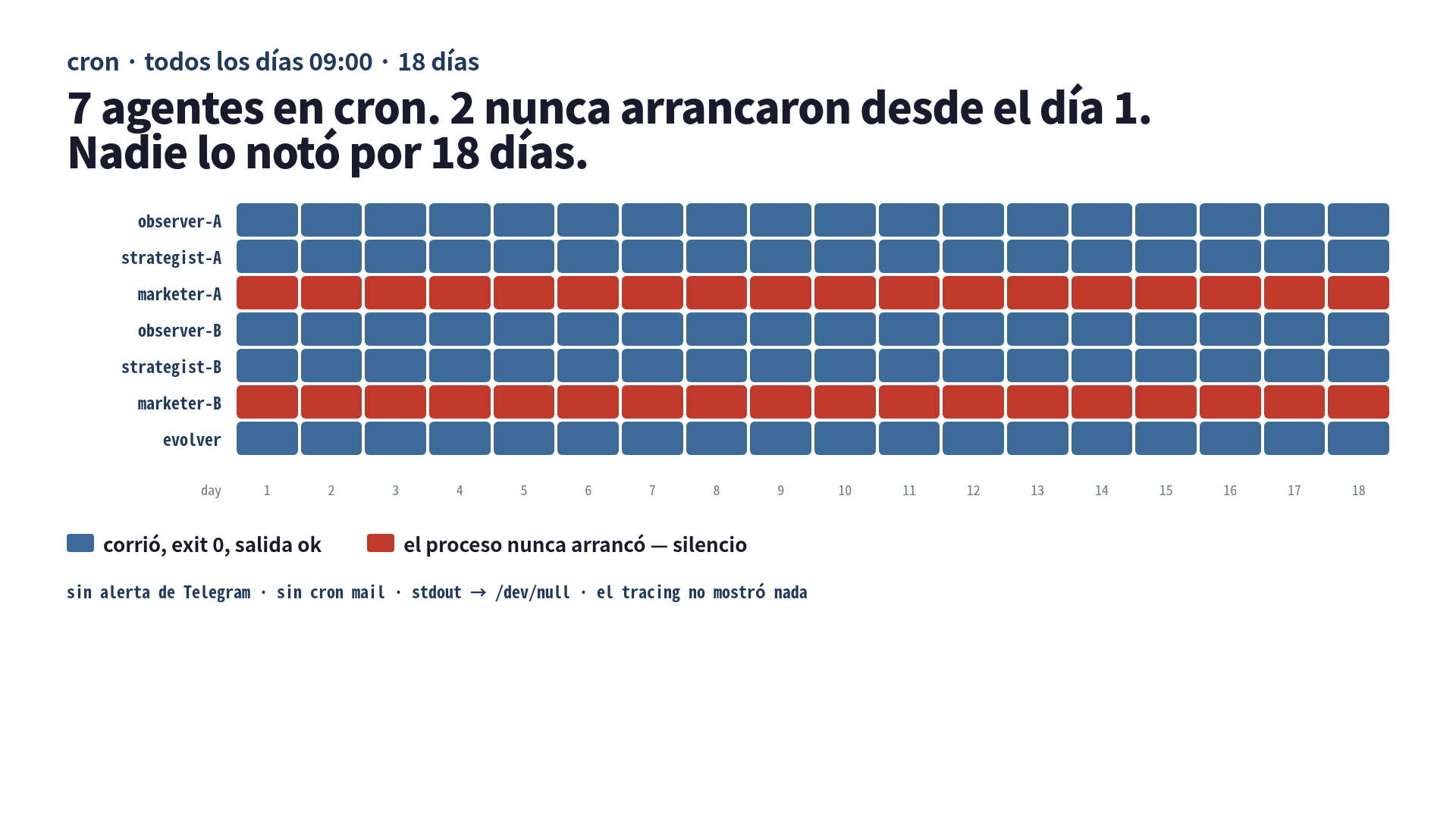
Programé 7 agentes de IA con cron diario. 2 fallaron en silencio durante 18 días. El tracing no los detectó. Un contrato de exit code sí.
Yo tenía 7 agentes de IA en cron. Dos de ellos dejaron de correr el día 1. Me di cuenta el día 18.
Esa frase ya es el artículo completo, pero también es la clase de frase contra la que yo habría discutido si alguien la hubiera dicho en un podcast. “No es posible no darse cuenta en 18 días. Tienes tracing. Tienes dashboard. Tienes un canal de Telegram que se enciende cuando cualquier cosa se mueve.” Sí, tenía todo eso. Los dos agentes muertos se colaron por debajo igual, porque cada una de mis capas de monitoreo estaba diseñada para mirar procesos que sí estaban corriendo. Los míos no.
Este es el log de los 18 días: cuáles eran los 7 agentes, cómo se rompieron 2 en silencio el día 1, por qué el tracing era la herramienta equivocada para esa falla, y el pequeño contrato de exit code que ahora le agrego a cualquier agente CLI que coloco en cron.
Los 7 agentes y el setup que se veía bien
Yo corro dos dominios de contenido y un harness self-evolving en la misma computadora. Cada dominio tiene 3 agentes en cron diario a las 09
— observer, strategist, marketer — más un evolver compartido que corre los sábados. Son 7 procesos. Las líneas del cron se veían más o menos así:0 9 * * * /home/me/repos/harness-ops/scripts/marketer-A.sh >/dev/null 2>&1
0 9 * * * /home/me/repos/harness-ops/scripts/marketer-B.sh >/dev/null 2>&1Cada shell script envuelve claude -p "..." con un prompt, captura la salida, escribe un log diario y termina. Si el agente decide publicar, publica al final. Tenía un webhook de Telegram dentro del script que disparaba tanto en éxito como en el camino del set -e. Este setup llevaba unos 2 meses en producción antes de la falla silenciosa.
Lo que se me escapó al montar el cron estaba 3 líneas debajo del heredoc. Los scripts de los dos marketers llamaban a un helper de Python que vivía en otro repositorio. Yo había hecho cd al repo vecino al hacer las pruebas, había validado el helper a mano, y lo había commiteado. Después limpié el repo vecino, le cambié el nombre al módulo, y la línea de import dentro del script del marketer quedó apuntando a un archivo que ya no existía.
A partir de aquí el final se ve venir. python3 helper.py ... sale con exit 1 al toque por ModuleNotFoundError. La primera línea del shell es set -euo pipefail. El script muere en las primeras 10 líneas. El Telegram se invoca recién más abajo, después del Python. El script nunca llega ahí. >/dev/null 2>&1 se traga el stderr. El cron sin MAILTO=. Todas las mañanas, 2 agentes mueren en silencio. Los otros 5 publican normal. El sistema entero se ve sano.
Lo que el tracing miraba, y lo que no
Quiero ser preciso acá, porque el día 18 me pasé varias horas tratando de convencerme de que “si el tracing fuera mejor, lo habría agarrado.” No lo habría agarrado.
Tenía spans OTEL saliendo de cada invocación de claude -p. Iban a un collector self-hosted y de ahí a un dashboard chico. El dashboard mostraba: tokens por tarea, latencia de tool-call, tasa de retry, total diario de ejecuciones de agentes. La mañana del día 18, el dashboard mostraba 5 ejecuciones por día, todos los días, durante los últimos 18 días. La línea estaba plana. Debía estar en 7.
El tracing instrumenta procesos que se ejecutan. Te muestra una llamada lenta. Te muestra una llamada fallida. Te muestra una tormenta de retries. Lo que no te muestra es un proceso que nunca arrancó. Los 2 marketers muertos no emitían span alguno, porque el emisor de spans vivía justo dentro del helper de Python que estaba fallando en el import. Desde la mirada del dashboard, esos dos agentes simplemente no existían ese día. Ni el siguiente. Ni el otro.
Yo estaba mirando la pregunta equivocada. “¿Mis agentes están sanos?” es una pregunta que el tracing contesta. “¿Mis 7 agentes programados corrieron de verdad hoy?” es una pregunta que el tracing no puede contestar, porque los agentes que no corrieron son exactamente los que no mandan señal de nada.
Si alguna vez leíste el modelo de dead man’s switch de healthchecks.io, es exactamente el escenario que describen en la doc: “Un job crítico de procesamiento de datos puede atascarse sin disparar ninguna alarma en los sistemas de monitoreo tradicionales. Esas fallas silenciosas pueden persistir durante días o semanas hasta que alguien nota datos faltantes o resultados corruptos.” Yo había leído esa página antes. Simplemente no la había aplicado a mi propio cron, porque sentía que el Telegram me cubría. Telegram solo dispara desde los caminos a los que el script llega.

El contrato de exit code que terminé atornillando
La solución no fue sumar más observabilidad. Fue confiar menos en el agente para reportarse a sí mismo, y más en el wrapper del cron para reportar en su lugar. Le puse un contrato pequeño a cada agente programado:
- Definir exit codes que signifiquen algo. No solo
0 = bien, cualquier otra cosa = mal. Tomé prestado de sysexits.h:0= “el agente corrió y terminó su tarea”,64= “error de config o entorno” (el caso delModuleNotFoundError),65= “corrió pero no produjo salida usable”,78= “skip a propósito” (el marketer decidió que hoy no había nada para publicar). - El wrapper del cron es el dueño del reporte. El trabajo del script del agente es salir con el código correcto. El trabajo del wrapper es agarrar ese código y mandarlo a algún lugar durable, sin importar si el agente terminó bien o mal.
- El heartbeat dispara en el éxito, no en la falla. El silencio tiene que ser la alarma.
El wrapper del cron quedó más o menos así:
#!/usr/bin/env bash
# scripts/cron-wrap.sh <agent-name>
set -uo pipefail
AGENT="$1"
SCRIPT="$HOME/repos/harness-ops/scripts/${AGENT}.sh"
HC_URL="https://hc-ping.com/<uuid-${AGENT}>"
START=$(date -Iseconds)
bash "$SCRIPT"
RC=$?
END=$(date -Iseconds)
# loguea cada ejecución, salga bien o mal
echo "${START} ${AGENT} rc=${RC} end=${END}" >> "$HOME/logs/cron-runs.log"
# pingueá con el exit code en la URL
# si falta el ping 24h → healthchecks.io me llama
curl -fsS --retry 3 "${HC_URL}/${RC}" >/dev/null || true
# escala no-cero al toque (pero el cron en sí nunca falla)
if [[ "$RC" -ne 0 && "$RC" -ne 78 ]]; then
"$HOME/bin/tg-notify.sh" "agent=${AGENT} rc=${RC} ver ~/logs/cron-runs.log"
fi
exit 0Tres detalles ahí que me costaron un par de tardes ajustar.
Primero, set -uo pipefail en lugar de set -euo pipefail. No quiero que el wrapper muera cuando el agente muere, porque si el wrapper muere antes del ping, healthchecks.io me llama recién dentro de 24 horas — demasiado tarde — y la línea del log ni se escribe. El wrapper tiene que seguir corriendo y capturar el código por su cuenta.
Segundo, la URL del ping lleva el exit code en el path. healthchecks.io lo acepta y lo muestra en el dashboard como el último código reportado. Puedo barrer la lista de un vistazo y ver “el agente corrió, salió con 64” sin abrir un solo log. Cronitor hace casi lo mismo con un formato de URL un poco distinto; usa la que te encaje en el stack.
Tercero, 78 es un skip deliberado, no una falla. El camino “hoy no hay nada para publicar” del marketer devuelve 78. Sin eso, el canal de escalamiento dispara en un día legítimamente tranquilo, yo aprendo a ignorar el canal, y el monitoreo muere en la práctica.
Lo que detectó el día que lo encendí
Lo dejé en producción exactamente el día 18 de los marketers silenciosos. En 10 minutos, marketer-A y marketer-B aparecieron en el dashboard de healthchecks.io con último código reportado = 64 — error de config, el módulo que ya no existía. No tuve que abrir el código del agente. Lo vi en el dashboard.
En una hora renombré el import, corrí los dos scripts a mano para confirmar exit 0, y el cron de la mañana siguiente publicó los 2 artículos que esos agentes habían estado salteando en silencio durante dos semanas y media. El dashboard de tracing finalmente subió a 7 ejecuciones por día. La línea sigue plana, pero ahora está plana en el número correcto.
Al día siguiente, otro agente — observer-B, que había estado sano todo el período de fallas silenciosas — empezó a salir con 65 (“sin salida usable”). El dashboard lo detectó en 20 minutos. Eso es lo que el contrato existe para hacer: el agente corrió, pero lo que produjo era basura. Te enteras el mismo día, no a la quincena.
Checklist: cómo blindar tu cron de IA contra fallos silenciosos
Esta es la versión corta que le pasaría a alguien que está armando hoy su primer pipeline de agentes en cron. Va en orden de “más barato a más laburo”:
- Pon
MAILTO=en el crontab. Una línea. El cron te manda por mail el stderr de cualquier job que falla, incluidos los que mueren antes de tu propio código de alerta. Cubre el 80% de las fallas silenciosas básicas. Si usas systemd timers, el equivalente esOnFailure=en el unit file, con un servicio que te envía el aviso (resumen claro en el ArchWiki). - Empieza cada script con
set -euo pipefaily termina con untrap ERR. El agente puede morir, pero al menos que muera ruidoso. Sinpipefail, una pipe que termina mal te devuelve 0 y te miente. - Define exit codes con significado. No es solo
0/1. Reserva 64 para errores de config, 65 para “corrió pero salida basura”, 78 para skip intencional. Cuando el dashboard te muestrarc=64ya tienes la primera mitad del diagnóstico. - Envuelve cada agente en un wrapper que sea tuyo. Un solo trabajo: agarrar el exit code y pingear a algún lado. El wrapper puede ser más feo que el agente, porque casi nunca lo vas a tocar.
- Agrega un heartbeat de éxito.
curl -fsS https://hc-ping.com/<uuid>al final del wrapper. Si falta el ping 24h, healthchecks.io te llama. Es el dead man’s switch clásico — el silencio se vuelve la alarma. - Manda el código de salida en la URL del ping.
hc-ping.com/<uuid>/<rc>. Cronitor también lo soporta. Te ahorra abrir el log para saber por qué murió. - Marca los skips intencionales con un código aparte (78 me funcionó bien). Si todos los “hoy no hay nada que hacer” disparan alerta, terminas ignorando el canal y el monitoreo muere por fatiga.
- Trata el dashboard del heartbeat como la fuente de verdad de “¿esto corrió?”. No el dashboard de tracing. El de tracing te dice cómo le fue al proceso vivo. El de heartbeat te dice si estaba vivo.
Los puntos 1 y 2 ya cubren la mayoría de los fallos de cron de la vida real. Los puntos 5 y 6 cubren el caso específico de este artículo (proceso que nunca arrancó). Los puntos 3, 4 y 7 son los que vuelven todo sostenible sin que termines silenciando notificaciones.
Lo que le diría a mi yo de hace 2 meses
La versión mía que montó este cron hace 2 meses no era descuidada. Tenía alertas de Telegram, dashboard de tracing y logs diarios. Había leído el capítulo de disposability del Twelve-Factor App. Hasta había pensado en la diferencia entre “el agente falló” y “el agente no corrió”, y había concluido que el segundo era lo suficientemente raro como para ignorarlo.
El error fue tratar “no corrió” como caso raro. En un setup con 7 procesos programados, 3 helpers de Python, 2 repos que se mueven independientes, y un script que mete el Telegram en el medio en lugar de en las dos puntas, “no corrió” es el modo de falla silenciosa más probable. Ni siquiera está cerca de los otros.
El tracing y la observabilidad son cómo vigilas a los procesos que están vivos. El contrato de exit code es cómo recuerdas que se suponía que tenían que estar vivos. Uno complementa al otro, y el patrón “set it and forget it” del cron se cae sin el segundo. El mío se cayó. Por 18 días. En silencio. En un servidor que yo miraba todas las mañanas.
Miraba el dashboard. El dashboard estaba mirando la pregunta equivocada.
Para llevar
- 7 agentes en cron, 2 murieron el día 1 por
ModuleNotFoundError, nadie lo notó por 18 días - El tracing observa lo que se ejecutó, así que es estructuralmente ciego al proceso que nunca arrancó
- La solución: contrato de exit code (
0/64/65/78), wrapper de cron que reporta por el agente, heartbeat de éxito con dead man’s switch - Lo más barato es
MAILTO=en el crontab. Solo eso ya hubiera detectado mi falla el mismo día
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?