他社の llms.txt を30個監査したら、すでに5つのアンチパターンが形になっていた
今月3本目の llms.txt を書き終えて、私は不当に満足していました。コーヒーを淹れ直して、これで AI 検索対策の個人的な宿題は終わったような顔をしていました。
その後、開発者なら誰でも参考にする30社の本番 llms.txt を順番に開いていきました。Anthropic、Stripe、Vercel、Cloudflare、Hugging Face、Mintlify、Astro、Linear。 「真面目な会社はこうやってる」と人に紹介するときに名前を出す顔ぶれ です。
30本中24本が、5つのパターンのうち最低1つを踏んでいました。そのうち3つは、私自身がやらかしていたものでした。
コーヒーが冷めました。
監査のやり方
仕掛けは恥ずかしいほど単純です。2026年5月時点で公開 llms.txt を持つ業界トップ30ドメインを並べました。AIラボ、開発インフラ、開発者ツール。curl で全部取ってきて、LLM の気持ちで読みました。気になった点をログに書きました。
これは科学ではありません。月曜の夜にターミナルを開いて触っただけです。ただ、パターンが速攻で出てきたので30本で止めました。次の10本も同じことになっていたはずです。
参考までに、SE Ranking が2026年3月に30万ドメインを分析した調査 では普及率は約10%。 codersera の2026年5月時点ガイド は約84.4万サイトが導入、年成長500%と試算しています。 普及レースには勝っている。質のレースには負けている という温度感です。
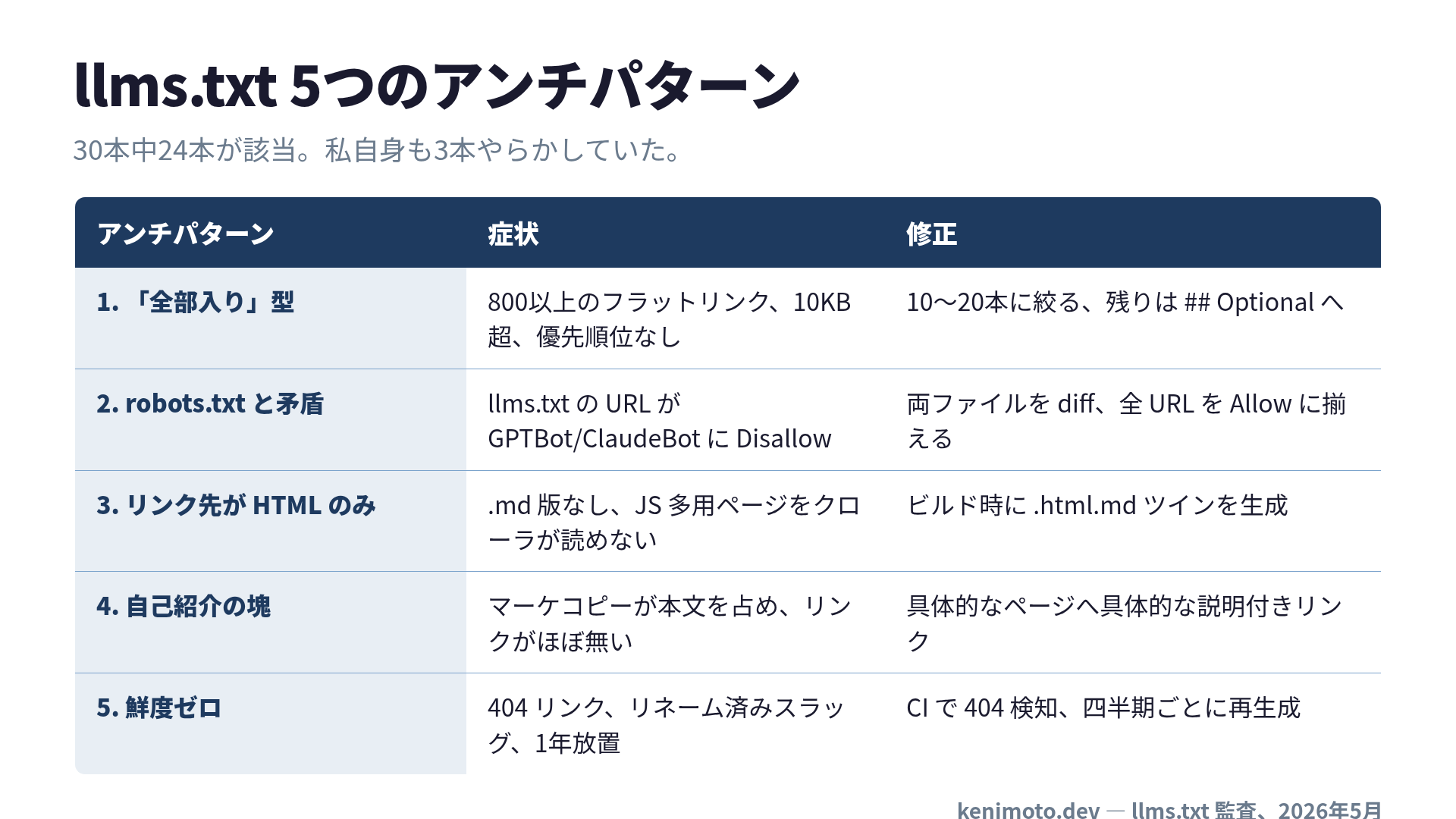
5つのアンチパターン
アンチパターン1: 「全部入り」型
最も多く、そして私が最もやらかしていたパターンです。著者は llms.txt を「sitemap.xml の二枚目」だと思っています。800リンク、1,200リンク、フラット、優先順位なし。 2019年から書いた全記事を時系列で並べたファイル を1本開きました。
llms.txt の意義は sitemap.xml ですでに済んでいるものを繰り返さないことです。仕様が「10KB以下推奨」と書いているのは、ファイルサイズの可愛い目安として言っているのではありません。 コンテキストウィンドウに収まらず、肝心の質問への予算が残らないなら、それは助けにならず、問題を移し替えただけ という意味です。
修正は容赦なくやります。10〜20リンクに絞ります。 50ではない。「主要セクション+少し余分」でもない。10〜20 です。それ以外は ## Optional セクションに送るか、sitemap.xml に残しておけば十分です。
ドキュメント主体のプロダクトなら、Cloudflare が採用しているパターンが綺麗です。ルート llms.txt はスリムに保ち、プロダクト別の llms.txt にリンクを張る。プロダクトごとに予算内に収まる。エージェントは必要なものだけ取ってくる。 蛇口を直すのに百科事典を最初から読む人はいません。
アンチパターン2: 「robots.txt と矛盾」型
robots.txt と llms.txt を両方開きます。両方のパスを diff します。 監査した30本のうち約3分の1が、robots.txt で AI クローラーに Disallow しているパスを llms.txt に堂々と書いていました。
一番痛かった例。あるドキュメントサイトは robots.txt で GPTBot と ClaudeBot を /docs/ から弾いていました。llms.txt には /docs/* URL を40本書いていました。 llms.txt は「ここが大事」と言い、robots.txt は「入るな」と言う。クローラーは robots.txt に従う。llms.txt は飾り です。
これはたいてい、2つのファイルを別チームが管理している(または同じ人が別の月に書いた)ときに起きます。修正は5分で済みます。両ファイルを並べて開いて、llms.txt の全 URL が AI クローラーに対して Allow になっているか確認するだけです。
本気で AI クローラーをブロックしたいなら、それはそれで構いません。ただし その上で丁寧なお気に入りページのディレクトリも一緒に渡してはいけません。
アンチパターン3: 「リンク先がHTML」型
Jeremy Howard が最初の提案で書いた賢いコンベンションがあります。 任意の URL の末尾に .md を付けると、ナビ・広告・JavaScript を取り除いた Markdown 版が返る 。.html.md パターンです。
ほぼ誰もやっていません。30本中、.md 版を実際に配信しているのは6本だけでした。残り24本は、 JavaScript を実行しない AI クローラー が読み取りに苦労する HTML ページを LLM に渡しています。
Stripe はこれを綺麗にやっています。全ドキュメント URL に .md ツインがあり、llms.txt は .md 版を指しています。 llmoframework.com の Reference Templates ページ は、 多くのチームが省略しているもののうち、効果対労力が最大なのがこれ と指摘しています。「AI がページを見つけられる」と「AI が中身を読める」の差を埋めるのがこのパターンだからです。
修正はスタック依存です。Astro/Next.js なら、ビルド時に .md 版を生成する30行の追加で済みます。動的 CMS なら、.md サフィックスで Markdown シリアライズを返す Edge Function が早道です。 どのみち、努力対効果が最も大きい修正です。
アンチパターン4: 「自己紹介の塊」型
30本中8本が、本文全体をマーケティングコピーで埋めていました。「私たちは AI ネイティブ時代の革新的リーダーです」が3段落。創業者の引用。会社の歴史。リンク2本。 トップページをそのまま貼り付けたかのような llms.txt です。
LLM はあなたのバイブスを買いません。コンテンツへのポインタが必要です。H1 とブロッククオートのサマリーが「このサイトは何か」を書く場所。それより下は、 具体的なページへの具体的な説明付きリンク であるべきです。llms.txt がホームページに見えたら、ホームページを書いたということです。
Princeton の GEO 研究「AI に引用される9つの方法」 はコンテンツ面で同じことを言っています。曖昧な主張は引用されない。具体的な主張+出典が引用される。同じ理屈が llms.txt 本体にも当てはまります。
アンチパターン5: 「鮮度ゼロ」型
監査した30本のうち5本は、 1度作って二度と触っていない兆候 が明らかでした。404 になる URL。すでに存在しないプロダクト名。最終更新の痕跡が2024年。llms.txt が提案されて半年そこそこ、「AI検索」を Perplexity がまだ説明していた時代のままです。
sitemap.xml は自動生成。robots.txt はめったに変わらない。llms.txt は中途半端な位置にいます。 ドキュメントのように手でキュレーションするが、README が「Yarn を使っています」と書いたまま pnpm に移行してから1年経っているのと同じ陳腐化リスクを抱える ファイルです。
修正は規律ではなく自動化です。llms.txt が列挙する URL に対して 404 を検出する CI チェックを入れる。「人気記事」セクションを四半期ごとにアクセス解析から再生成する。 一回限りのローンチ成果物ではなく、config ファイルのように扱う のが正解です。
Mintlify が顧客ベースで観察した実例分析 では、これが2番目に多いパターンでした。1番目はアンチパターン1。 今週手をつけるならこの2つ です。
国内事例も覗いてみた
国内ドメインも何本か curl してみました。zenn.dev には llms.txt がありませんでした(調査時点、2026年5月)。note.com も同じ。クックパッド、メルカリ、SmartNews も未配置。 Zenn の Book で同じ章を扱った 立場から書きますが、 国内の Web メディア・SaaS 大手で llms.txt を配置している例は2026年5月時点でほとんどありません 。
これは2通りに読めます。「日本は周回遅れ」と読むこともできるし、「国内なら今のうちに置けばまだ先行者利益が取れる」と読むこともできます。後者の方が建設的です。
私自身が踏んでいた3つ
正直セクションです。私の3本の llms.txt のうち、
- 1本は47リンクを書いていた。アンチパターン1。
- 1本は
.md版を用意していなかったので HTML のみを指していた。アンチパターン3。 - 1本は4ヶ月放置で、リネーム後のスラッグへの301リダイレクトチェーンを含んでいた。アンチパターン5 + デザートとして301の連鎖。
他人のファイルを4分の3ほど読み終えた頃に、ようやく自分のミスに気づきました。 監査は他人を採点する作業のつもりで始めて、自分の答案を晒すことになった 話です。教訓は確実に何かあるはずですが、まだ恥ずかしさのフェーズなので整理できていません。
2本だけ直してみた結果
3本のうち2本だけ直しました。47リンクのファイルは16リンク+## Optional セクションに圧縮。HTML のみだったファイルは、Astro のビルドフックで主要16 URL に .md ツインを生やしました(25行ほどで済みました)。
「AI 引用率がX%上がった」とは書けません。ファイルがまだ1週間しか経っていないし、 この規模で引用測定はノイズだらけ です。書けることはひとつだけ。 「200K コンテキストウィンドウで他に10タブ開いている LLM が、前バージョンより新バージョンを好むか」と聞かれて、迷わず Yes と答えられるようになった 。前バージョンは読めなかった。それだけです。
llms.txt についての正直な立場
懐疑派は半分正しい。 SE Ranking の30万ドメイン調査では引用率の有意な向上は出ていません。主要 LLM はファイルを取ってきていると公式には認めていません。標準化団体の刻印もありません。
懐疑派は半分間違っている。IDE エージェント(Cursor、Cline、Continue)、 私が比較した5つの AI 検索エンジン のうちいくつか、増えつつある MCP インテグレーションは、今日 llms.txt を読みに来ています。 オプション性は本物で、コストは15分 。
2026年の本当の問いは「llms.txt を置くべきか」ではありません。コスト便益でとっくに決着しています。問いは 「置いたファイルが LLM の役に立つのか、それともあなたのドメインを無視するように学習させるのか」 です。アンチパターン1〜5は、その2つの結末を分ける線です。
今週やるチェックリスト
まだ置いていない人は、 4月に書いた llms.txt 最小実装記事 を踏襲してください。すでに置いた人は、5項目で自己採点してみてください。
- ファイルは10KB以下で、
## Optionalを除いたリンクが20本以内か - リストされた全 URL が、robots.txt で GPTBot と ClaudeBot に許可されているか
- 上位5 URL に
.mdツインが存在するか - 本文は具体的なページへのリンクか(一般的なマーケコピーになっていないか)
- 直近90日以内に更新されたか
5点満点なら、私が見た30社の上位6社、つまりすでに自己選択された母集団の上位20%に入ります。3点以下なら、私と同じ月曜の午後があなたを待っています。
私は今週4本目の llms.txt を書きます。このリストを通してから公開します。終わったあと、生産的な気分にはならないでしょう。 3回連続で同じ教訓を学んだ人間の顔 をしているはずです。
私はそう聞いています。エンジニアリングというのはそういうものらしい。
参考
- llms.txt 仕様(Answer.AI): Jeremy Howard 氏のオリジナル提案
- SE Ranking の30万ドメイン調査: 普及率と引用効果の実証分析
- Mintlify Real llms.txt examples: 大手企業の実例とミス
- llmoframework.com: LLMO 全体フレームワークと Reference Templates
- Google Rich Results Test: 構造化データのバリデーション
さらに深掘りしたい方へ
llms.txt 単発ではなく、JSON-LD・robots.txt 戦略・コンテンツ設計・効果測定まで含めた LLMO の全体像が欲しい方は、 LLMO: エンジニアのための AI 検索最適化 が一番網羅的です。12章構成、Quickstart より深掘り、ケーススタディも多めです。
この記事は役に立ちましたか?