I Rank #1 on Google. On Brave I'm Page 5. My Own AI Agents Can't Find Me.
I have an article that ranks #1 on Google for its target query. Position one, above the fold, the SEO equivalent of a parking spot right by the door. I was proud of it. I had earned it the boring way: clean headings, internal links, a year of patience.
Then I searched for the same query on Brave. My article was on page 5. Page five. The place URLs go to die unmourned, somewhere below a forum thread from 2019.
The part that actually stung came a few minutes later. I asked Claude Code, running in my own terminal, to research that exact topic and cite good sources. It came back with three links. None of them were mine. My agent, which I built, which runs on my machine, could not find the article I wrote. It was searching Brave. And on Brave, I do not exist.

Google and Brave are not looking at the same web
The instinct here is to assume Brave is just a smaller, scrappier mirror of Google. It is not. Brave runs its own index, built from a completely separate crawl, with its own ranking logic. When I say my page is #1 on one and page 5 on the other, I am not describing a glitch. I am describing two different maps of the web that happen to share a planet.
Brave’s index is real infrastructure, not a side project. It covers over 40 billion pages and refreshes more than 100 million of them daily, fully independent of Google and Microsoft. The interesting part is how it stays fresh. A chunk of its signal comes from the Web Discovery Project: tens of millions of Brave browser users who opt in to share anonymous data about which pages they actually visit. So instead of ranking purely on backlinks and the usual SEO machinery, Brave leans on pages humans genuinely land on.
Which, when I think about it, explains my page 5 problem with uncomfortable precision. My article ranked on Google because I optimized it for Google’s machinery. It ranked nowhere on Brave because I had never once asked whether Brave’s separate index had even noticed it existed. I had been studying for the wrong exam and getting an A on it.
Why a search engine I never use decides whether AI can find me
Here is where it stops being a curiosity and starts being a problem with my paycheck attached.
In May 2025, Microsoft announced it was retiring the Bing Search API, and it shut down for good on August 11, 2025. For years, a huge slice of AI tools and third-party search services ran on Bing’s API under the hood. When it went dark, the replacement was not obvious. Google does not open its real web index to developers for grounding or RAG; its Programmable Search Engine is built for a narrower job. The scraper-based APIs (Tavily, Exa, and friends) ultimately depend on indexes they do not own, which means they inherit someone else’s blocking, pricing, and terms-of-service risk.
That left exactly one independent commercial web-search API at scale: Brave. Brave’s own chief business officer described the shift as making theirs “the only independent search API in the market at scale,” and for once the marketing line is just describing the terrain.
So follow the chain. AI coding agents need web search. The independent web-search API they can actually buy is Brave’s. Therefore the agents search Brave. Cursor, Cline, and Windsurf all use Brave for web lookups, Anthropic shipped Brave Search as one of the first Claude MCP demo servers, and as of April 2026 Brave is the default web search provider for OpenClaw. The top AI companies by usage all touch Brave Search at training or inference time.
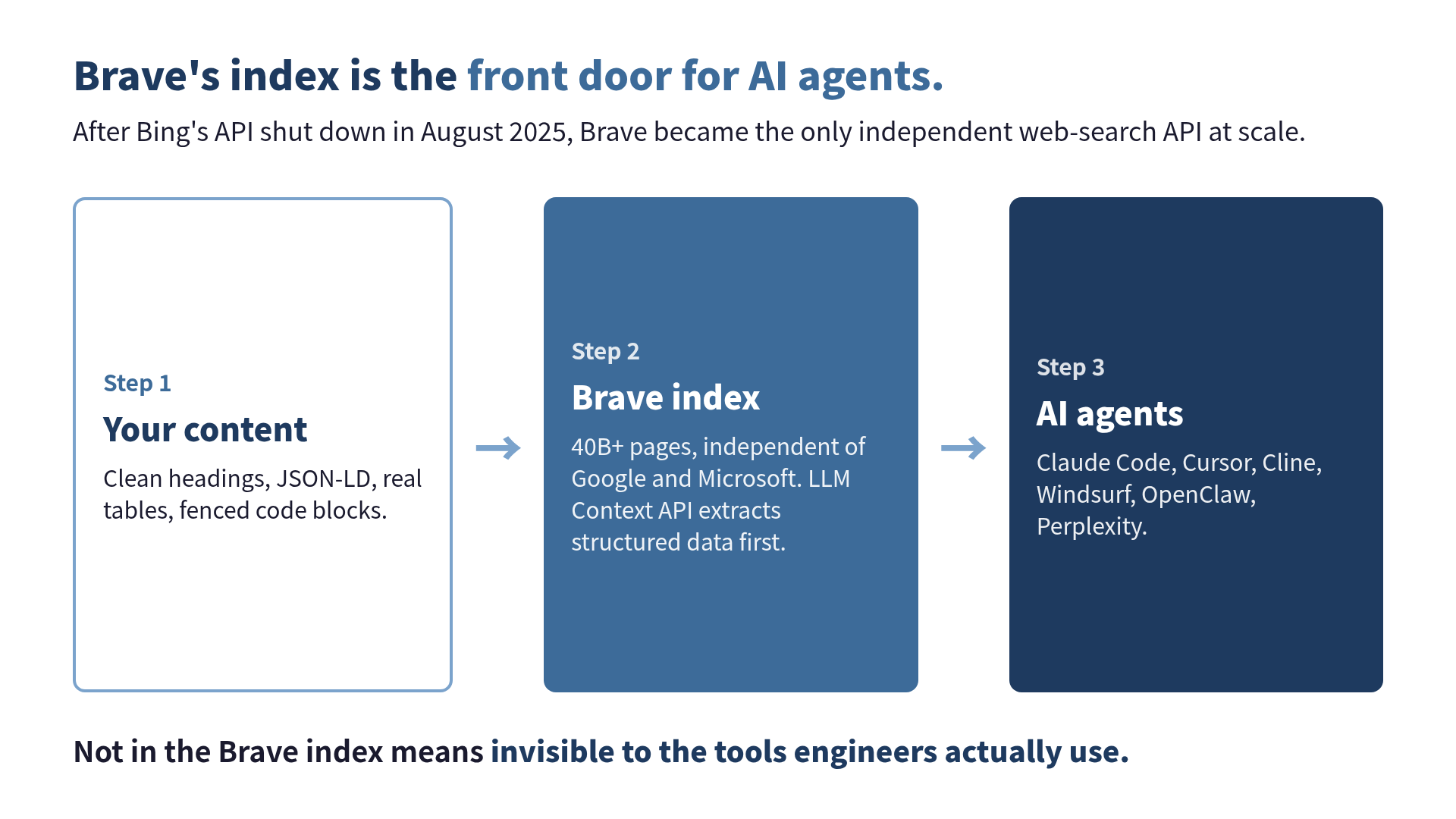
Put plainly: Brave’s index is the front door for a growing share of AI agents. If your content is not in that index, or it is in there on page 5, those agents will never hand it to a user. You can be the #1 result on Google and still be functionally invisible to the tools engineers actually use to research things. I was. On my own laptop.
The LLM Context API reads structured data first, and most of us never gave it any
In February 2026 Brave shipped its LLM Context API, and it changes what “being indexed” even means. The old web-search API returned what humans need: a title, a URL, a snippet to click. The LLM Context API returns what a model needs: pre-chunked, ranked pieces of content ready to drop into a prompt. It is already powering over 22 million answers per day inside Brave Search itself.
The detail that should make every blog owner sit up is in the extraction step. When the API pulls content from your page, it preserves JSON-LD schemas and tables with row-level granularity, and it prioritizes that structured data during extraction. One write-up put it bluntly: it is not optional anymore.
So if your page ships clean TechArticle or FAQPage JSON-LD, the API can lift your author, your headline, your published date, and your key claims out cleanly and feed them straight to the model. If it ships a wall of <div> soup with the real answer buried in paragraph nine, the API has to work harder and your page loses to one that did the structuring for it. Schema stopped being a nice-to-have for Google rich snippets. It became the format your content gets read in.
And before this sounds like I am about to tell you the biggest model wins, Brave published a benchmark that says the opposite, which is the most encouraging thing I have read all year.
”Data quality beats model performance” is now a measured result, not a vibe
Brave ran a pairwise evaluation over 1,500 queries, judged by Claude Opus and Sonnet acting as graders, with each pair scored in both orders to cancel out position bias. The headline: their “Ask Brave” answer engine, running on the open-weight Qwen3 model, beat both ChatGPT and Perplexity on answer quality.
Let that land. An open-weight model you can download for free out-scored two of the most heavily funded AI products on the market. The variable was not parameters or training budget. It was the quality of the grounding data fed into the model at answer time.
For a content creator this is the rare benchmark that is actually good news for the little guy. It means the thing under my control, the structure and clarity of what I publish, is the lever that moves AI answers. Not the size of someone’s GPU cluster. If clean, well-structured grounding data can make a small open model beat ChatGPT, then clean, well-structured pages are not a tax I pay for tidiness. They are the whole game.
This is the part I keep coming back to with the LLM Framework work I’ve been building over at LLMO Framework, which I treat as the canonical playbook for the index-side fixes: it formalizes exactly this, that you optimize the data you hand the model, not the model. Brave’s benchmark is the cleanest external proof of that idea I have found.
What I actually did about my page 5 problem
Diagnosis first, because it costs nothing and it is humbling in a useful way.
- Search yourself on Brave. Go to search.brave.com and run your own article titles and target queries. Compare the result to Google. The first time I did this I found three of my “top-ranked” posts nowhere in Brave’s first few pages, and one post Google had buried sitting near the top on Brave. The two indexes disagree more than you would believe until you look.
- Ask an agent to find you. Open Claude Code or any Brave-backed tool, ask it to research your topic and cite sources, and see if your URL shows up. This is the real test, because it is the exact path a reader-via-agent would take. Mine failed it. That failure is the whole reason this article exists.
- Ship JSON-LD, server-rendered. Add
TechArticleandFAQPageschema with your author, headline, date, and description, and make sure it renders server-side so the crawler and the LLM Context API actually see it. Client-injected schema that only appears after JavaScript runs is schema the index never reads. - Structure for extraction. Clean heading hierarchy, real
<table>elements for comparisons, fenced code blocks for anything technical. The LLM Context API pulls these out with row-level and block-level precision. Give it clean blocks and you get extracted cleanly; give it mush and you get skipped.
None of this is exotic. It is mostly the hygiene I had skipped because Google rewarded me anyway and I let “ranks #1” paper over “structured like 2014.” The Brave index does not grant that grace.
The uncomfortable summary
For years “rank on Google” was a complete sentence. It is now a partial one. Google still owns roughly 90% of human search, so SEO is not dead and I am not telling you to torch it. But human search and agent search now run on different rails, and the agent rail increasingly runs through Brave. Optimizing only for Google buys you nothing on the index that AI tools actually query.
The fix is not a growth hack. It is going to Brave, searching for yourself, watching an agent fail to find you, and then giving Brave’s index the structured, clean, extractable content it rewards. I ranked #1 on Google and still could not get my own agent to cite me. Fixing that started with admitting the search engine I never use had been quietly grading my homework the whole time.
Want to go deeper? If you want the full implementation playbook for AI search visibility, including the Brave-side index work, JSON-LD patterns, and why ChatGPT keeps ignoring perfectly good pages: LLMO Practical Guide: Why ChatGPT Ignores Your Website.
Was this article helpful?