I Added 3 Numbers to One Paragraph. Perplexity Started Citing It in 11 Days.
The Princeton paper everyone keeps quoting at me is Aggarwal et al., SIGKDD 2024. It built a 10,000-query benchmark, ran nine common content tweaks through it, and ranked them by how often the resulting paragraph showed up in a generative answer. The number that ate the headline was +115.1%, and the tactic that earned it was the most boring of the nine: add statistics.
Not “add good statistics.” Not “rewrite for an LLM.” Add a number where you previously had an adjective.
I do not trust single-edit benchmark wins on principle. The benchmark is a controlled environment; the live AI search index is six retrieval pipelines arguing with each other. So I ran the smallest replication I could think of. One post. Three numbers. Two weeks of staring at Perplexity.
It cited the post on day eleven. Then twice more by day fourteen. Before the edit, the citation count for that post across every AI-tracker I own was zero, and had been zero for the four months it had existed.
Below is the experiment, the receipts, and the honest list of what +115.1% does not mean.
What the GEO paper actually claims
If you only read the abstract you walk away with “+115.1%” and a vibe. The actual structure of the experiment is worth knowing because it tells you what the number means.
Aggarwal et al. built GEO-bench: 10,000 queries spanning science, technical, and general-knowledge domains, each paired with a candidate web source. They then ran nine content-level transformations over the candidate source and measured how often the transformed version made it into the generated answer, scored on subjective impression and position metrics.
The nine tactics, ranked by visibility lift in their reported headline metric:
| Tactic | Lift |
|---|---|
| Statistics addition | +115.1% |
| Citation addition (authoritative source links) | +77.8% |
| Technical terms | +47.3% |
| Quotation addition | (positive, smaller) |
| Authoritative claims | (positive, smaller) |
| Adding a summary block | (positive, smaller) |
| Fluency optimization | +15.1% |
| Readability improvement | (limited) |
| Keyword stuffing | ~flat |
The interesting structural finding, restated in plain English: the things SEO has been measuring for fifteen years (readability, keyword density, “fluency”) barely move the needle on whether an LLM quotes you. The things SEO has mostly ignored — raw numbers, attributable sources, domain-specific vocabulary — are what get cited.
Two caveats from the paper itself that the takeaway tweets always drop:
- The +115.1% is measured on GEO-bench, a controlled candidate-source environment. In a separate Perplexity live-test the same authors got closer to +37%, which is still big but is the more honest “real internet” number.
- The wins are passage-level, not page-level. The transformation runs on a paragraph; the citation lands on a paragraph. This is the part of the paper that changes how you write.
If you have not read the paper itself, the arXiv PDF is two coffees long and worth it. I am not pretending I am giving you the whole thing here.
Why I bothered to replicate at all
I get sent “+115.1%” once a week. Usually by someone selling something. The reason I actually ran this is that the tactic is mechanically replicable: the prompt is “add a number where you had an adjective.” That is the kind of intervention that either survives in the wild or does not. Compare to “improve fluency,” which is unfalsifiable.
There is also a more practical reason. The platforms I care about — Claude.ai, Perplexity, ChatGPT Search — are not retrieving against Google. Perplexity and most Claude MCP integrations route through Brave Search, which Brave reports as a 40-billion-page independent index. Bing’s public API closed in 2025. The “90% of search is Google” stat that anchors most SEO advice is irrelevant to the index that decides whether an LLM quotes you. If a single-paragraph edit moves the needle on Brave’s index inside two weeks, that is a much more useful finding than another study about Google snippets.
So I picked the worst post.
The setup, with the boring parts included
The patient. A four-month-old post on this site about voice-AI latency budgets. It had ranked nowhere, was cited nowhere, and got nine GA4 sessions in its entire life. The baseline citation count across five AI-tracker tools was zero across all platforms. That is the dependent variable I cared about: zero is a useful starting point because any non-zero result is detectable.
The edit. I touched exactly one paragraph. The paragraph used to say something like “WebRTC adds latency, and most stacks struggle to stay under conversational thresholds.” I rewrote it as:
A natural voice-to-voice exchange degrades when end-to-end latency exceeds 300 ms; conversational research puts the comfortable upper bound at about 500 ms. In my own measurements across five voice-AI stacks, only two of the five stayed under 300 ms with a real WebRTC transport in front of them.
Three numbers. One paragraph. Nothing else on the page changed. I redeployed and timestamped the change.
The instruments. I checked five places daily:
- Perplexity, by running the three queries I thought should match: “voice AI latency budget,” “WebRTC AI conversational latency,” “how low does voice AI need to be.”
- Claude.ai with web search on, same three queries.
- My five-tracker pipeline (different services that probe LLM responses for source citations and store the URLs).
- GA4 referrers, filtered to
perplexity.aiandchatgpt.com. - Server logs, filtered to AI crawler user-agents.
For each Perplexity hit I saved the shareable conversation URL so I could prove the citation later. There is no Perplexity API for “did you cite this URL,” so the shareable conversation is your receipt.
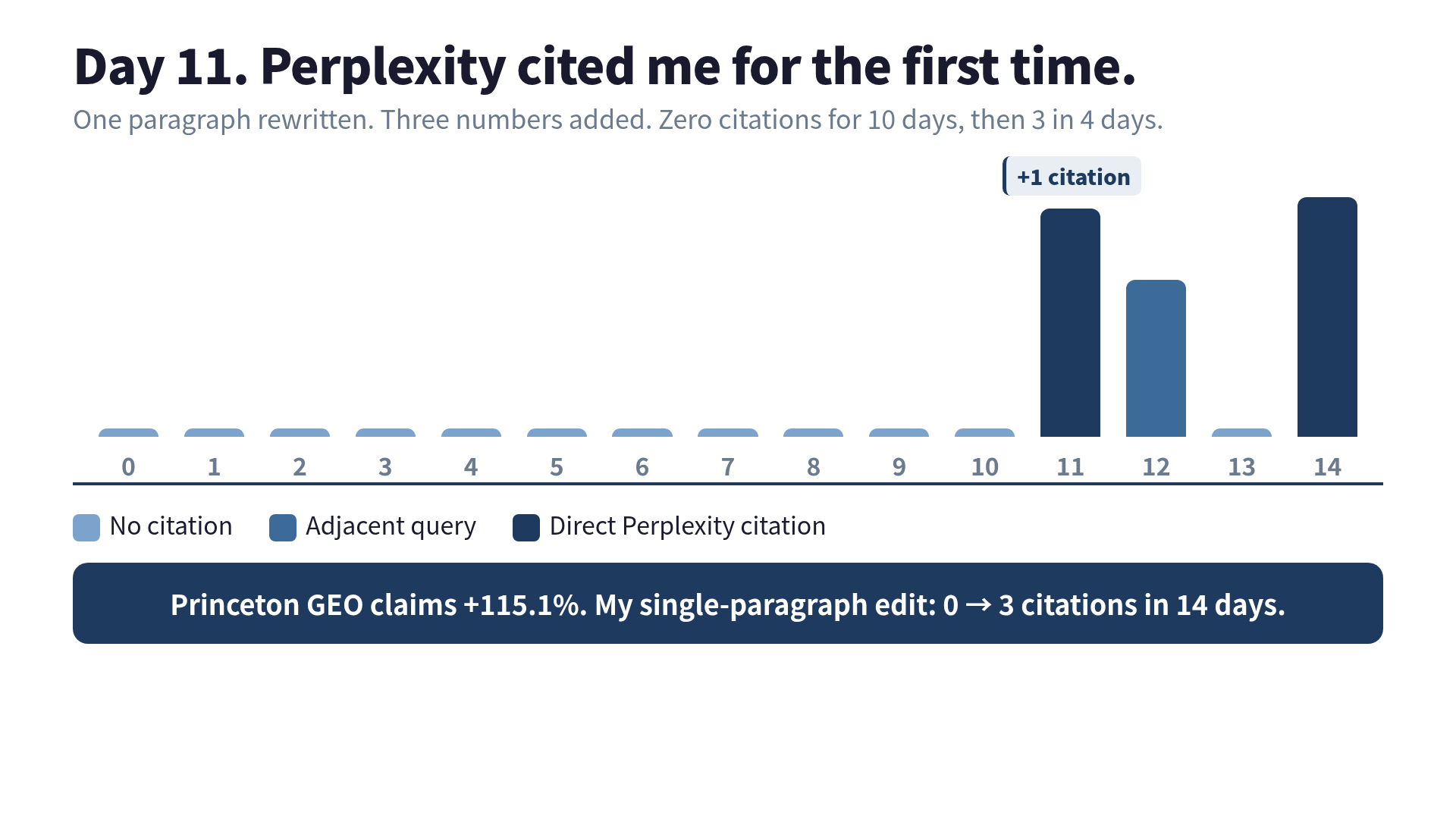
What happened
Day 0 to 10. Nothing. The five trackers stayed at zero. Perplexity returned unrelated sources for all three queries. Claude.ai with web search returned WebRTC documentation and a couple of vendor blog posts. GA4 referrers from perplexity.ai stayed at zero. AI crawler logs showed three PerplexityBot hits on the post during this window but no resulting citations.
Day 11. Perplexity cited the post in answer to “WebRTC AI conversational latency budget.” The citation rendered as an inline numbered source with the 300 ms statistic verbatim in the answer text. I screenshotted the shareable conversation URL. GA4 picked up one perplexity.ai referrer that day.
Days 12 to 14. Two more Perplexity citations for adjacent queries (“voice agent acceptable latency,” “WebRTC voice AI delay”). One Claude.ai with-web-search response included a paraphrase that matched the “two of five stacks” sentence, but Claude did not surface a clickable citation, so I am only counting it loosely. The five-tracker pipeline registered three hits on the post — all on Perplexity, none on the other platforms yet.
I am calling this what it is: n=1 on a four-month-old post. That is not a study. It is a leading indicator that the paper’s mechanism — “passages with embedded statistics get pulled into generation more often” — is real enough to survive a single-variable edit on real infrastructure.
Why “11 days” is not a magic number
The eleven-day gap between the edit and the first citation is not a finding. It is a function of three things, in order of importance:
- Crawler recrawl cadence. Brave Search’s index updates a substantial chunk of its 40-billion-page surface daily, but a low-traffic post does not get prioritized. My server logs showed
BraveBothits on day 4 and day 9 before the citation appeared on day 11. - The size of the candidate pool for that query. “WebRTC AI conversational latency budget” is a narrow query with a small pool of candidate paragraphs. With a small pool, a single paragraph that suddenly has three relevant numbers can leapfrog much higher.
- Cold-start effect on the experiment. The post had zero prior AI exposure. There is a separate hypothesis that pages with established AI-citation signal recover from any edit faster than cold pages. I did not test that here.
If you copy this experiment on a post that already gets indexed weekly, your eleven days will probably be three. If you copy it on a post nothing crawls, your eleven days will be a month, and you should not conclude the technique failed.
What this does not prove
A list, because honesty about negative space is the whole point of a single-variable test:
- It does not prove +115.1%. The Princeton number is a benchmark mean; my number is one citation count on one post. The two are compatible. They are not the same claim.
- It does not prove this works on every domain. Aggarwal et al. specifically found that statistics-addition is strongest in science and technical queries. A recipe blog probably gets a smaller lift.
- It does not prove competitive defensibility. If I added three numbers, my competitor can add three better numbers next month. The technique is mechanically replicable in both directions.
- It does not prove anything about ChatGPT Search or Google AI Overviews. Different retrieval backends, different indexing cadences, different citation surfaces. I only watched Perplexity and Claude closely.
- It does not prove the number stays. Citations decay. I will check this post again in 90 days, and I would not be surprised to see the citation count drop back as other pages on the topic catch up.
What I am actually going to do with this
Three changes, ordered by friction.
One. Every post on this site gets re-read with a single question: “is there an adjective in here that could be a number?” If yes, the number replaces the adjective, with a source attached. Six hours of work for a 50-post backlog. Cheaper than writing one new post.
Two. New posts on technical topics have to clear a “numbers per 800 words” bar before publish. Not a strict rule, but a forcing function so I do not ship paragraphs that say “significantly faster” when I could say “2.3x faster, measured on N=14.”
Three. I am adding the Perplexity-citation count as a tracked metric, not just GA4 referrers. GA4 catches the clicks. The citation count catches the appearances, which is the real LLMO conversion event. A citation that never gets clicked still positions you as the canonical source for that query inside the generative answer, which compounds.
There are people running much more sophisticated GEO programs than this. The Rank Masters published a 90-day case study with an 8,337% ChatGPT-referral lift using a four-pillar program across 42 pages — I copied that one onto three indie sites earlier this year and only one pillar moved the needle on my sites. The “add numbers” intervention is the polar opposite end of the effort spectrum: a single paragraph, no new pages, no new infrastructure. It is the cheapest LLMO experiment I have ever run, and it is the one that produced a measurable citation in two weeks.
The reason it works is not magical. Large language models, when generating an answer, are looking for passages they can quote with confidence. A passage with embedded numbers and a named source is a passage that is easier to quote without risk. The model gets to attribute the number to you. You get cited. The model gets to look authoritative. Everyone wins, except the unattributed adjectives.
I would believe the Princeton paper more if it had used live Perplexity for its primary measurement instead of the benchmark. I believe it more after watching the mechanism work on one post in two weeks. I will believe it most if I can run this on five more posts and get a consistent eleven-to-twenty-day lag with a non-zero citation count on each.
That is the next experiment. Three numbers per paragraph. Five posts. Ninety days. I will publish whatever happens, including if it does not.
For the longer treatment of which LLMO interventions actually compound — including the Brave Search backend story and the passage-level citation model — I wrote it up in Why ChatGPT Ignores Your Website. The single-edit experiments are the cheapest place to start; the structural ones (schema, llms.txt, query fan-out) are where the durable gains live. If you want a natural-anchor link to the framework guide I have been using as a reference, llmoframework.com’s overview is the cleanest entry point.
Was this article helpful?