I Ran Claude Code, Cursor, and Codex Side by Side for 31 Days. Here Is the Real Monthly Bill.
I read a lot of coding-agent comparison posts. They rank accuracy, they rank ecosystem maturity, they rank “vibes.” Almost none of them show a monthly bill. This is the post I wanted to read before I picked one.
For the 31 days of June 2026 I ran all three official coding agents on the same laptop: Claude Code (Anthropic), Codex (OpenAI, inside ChatGPT), and Cursor. Same repos, same tasks, same me. I kept receipts. I logged sessions. I ran a local Qwen model on an RTX 4070 in parallel to see where owning silicon actually pays back.
The short answer: one of them is cheapest for me right now, but not by the margin the marketing pages suggest, and if my usage shape changes even a little the ranking flips. That is the real headline. The bill depends on what you do more than on which logo you pick.
I already learned once that estimating cost after a prototype ships wastes a month of everyone’s time. This is the estimate-first version, done publicly.
What “one month” actually was
The month I logged:
- 22 working days at the keyboard.
- Roughly 6 hours a day inside an agent, mixed reading + writing.
- Two projects: one TypeScript SaaS with ~180 files, one Python data pipeline with ~60.
- Three “hard” refactors (multi-file, week-scale), the rest was normal feature and bugfix work.
I mention this because “agent cost” without a usage shape is meaningless. A part-time hobbyist and a full-time engineer buying the same $200 tier are buying two very different products at the same price. The line I care about isn’t $/month, it is $/hour-of-agent-time.
The three cost shapes
Every coding agent bills you as one of three shapes, and June 2026 hasn’t changed that.
- Subscription with usage multiplier. Flat fee, soft cap on requests, throttle when you’re over. Claude Code Pro / Max, ChatGPT Plus / Pro, Cursor Pro / Ultra all fit here.
- Metered API. You pay per token. No monthly ceiling unless you set one.
- Local GPU. You bought the card. Electricity + amortization. Zero variable cost per token but a fixed capacity ceiling.
The break-even between these three is what most posts skip. Let me put my June numbers into the same table.
Claude Code: $200/month Max, and I hit the throttle twice
I ran Claude Code on the Max 20x plan at $200/month, per Anthropic’s current pricing page. The Pro tier at $20/month exists but is calibrated for a few focused sessions a day, not an agent-driven workflow.
What I actually got out of the month:
- Claude Code was my primary tool for the two “hard” refactors. Long-context is where it earns the bill.
- I hit the 5-hour rolling limit twice on Max, both times during a deep multi-file refactor where I was running Sonnet 4.6 in the background across 3 subagents. That is Anthropic’s cost tell: subagents multiply token spend, and the Max tier feels the cap when you fan out.
- Everything else fit comfortably.
If I had run the same month on the metered API at Sonnet 4.6 pricing of $3/M input and $15/M output (the introductory $2/$10 promo runs through August 31, 2026, so I’m quoting the standard rate), the honest estimate for my token volume was somewhere in the $260-$380 range. The subscription won by ~$60-$180, at the cost of a rate limit I can predict but not remove.
The specific lesson: for a heavy user, Max 20x is cheaper than the API only until you fan out subagents. Anthropic’s own engineering blog notes that multi-agent runs use roughly 15x the tokens of a single-agent chat. That’s real. If I ran three subagents on Sonnet as my normal shape, the API metered path would probably beat Max.
Codex: bundled inside ChatGPT Pro at $100, and the pricing model just changed
Codex is the odd one. It doesn’t have a separate subscription. It rides inside your ChatGPT plan.
I ran ChatGPT Pro at $100/month, the tier OpenAI added in April 2026 to sit between the $20 Plus and the $200 Pro-20x. Two things I noticed that the marketing page doesn’t emphasize:
- On April 2, 2026, Codex pricing moved from per-message to API-token-equivalent metering. If you were used to the old plan, your “same amount of work” started drawing down credits at a different rate. Nobody’s monthly bill actually stayed the same, they just moved.
- The average Codex developer sits at roughly $100-$200/month across all instances they’re running. That is the same number I hit. Bundling with ChatGPT means I paid one bill, but the token math isn’t hidden. It’s just billed as one line item.
Where Codex earned the seat for me: quick front-end scaffolding, one-shot script generation, “explain this stack trace” flows where I want an answer inside a browser tab I already have open. Where it didn’t: long-lived agent sessions in a real repo. That is where Claude Code held the line.
Cursor: $60/month Pro+, and I stopped using the frontier models in it
Cursor’s June 2025 credit model change means the plan you buy is really a credit pool. Hobby is $0, Pro is $20, Pro+ is $60, Ultra is $200. I paid for Pro+ this month.
The move Cursor pushed on me was Auto mode. On any paid plan Auto is unlimited — it picks a model for you and doesn’t touch your credits. If you leave Auto on for tab completion and short edits and only reach for Claude Sonnet or GPT-4o for the actual reasoning work, the credit pool lasts.
I did the opposite for the first two weeks and paid for it: I forced Claude Sonnet everywhere, my credits drained by day 18, and I bought a top-up. The last two weeks I flipped the pattern — Auto for autocomplete, frontier models only when I explicitly asked — and the same Pro+ pool covered the rest of the month with room to spare.
The Cursor-specific insight nobody puts on the pricing page: Pro at $20 is fine if you use Auto for most things. Pro+ at $60 is where you land if you can’t help yourself and keep clicking Sonnet. Ultra at $200 is for someone running agent mode all day; that wasn’t me this month.
The local GPU: RTX 4070 + Qwen 3.5 35B, the breakeven that isn’t what you think
I keep an RTX 4070 running Qwen 3.5 35B locally, and I ran it as a fourth “agent” in parallel to see what jobs actually made sense to send there.
The naive breakeven math is easy and misleading. A $600 card amortized over 24 months is $25/month. Electricity at moderate use is another $10-$15. On paper: $35-$40/month for unlimited tokens.
Here is what the naive math misses:
- The 4070 can’t run the frontier models. It runs the small ones, competently but at ~40% of the quality of Sonnet 4.6 on the tasks I care about. For me, that eliminated it from primary agent duty.
- Where it did earn its slot: bulk classification, refactor precheck, and offline batch jobs. I ran a 3,000-file “which files touch payment logic” scan on Qwen overnight; the same job on Claude API would have been $8-$12. Twenty of those a month is where the card breaks even.
- Zero of my long-context refactor sessions belonged on local. The context window on Qwen 3.5 35B is not comparable to Sonnet 4.6.
I said this in my earlier post on API vs subscription vs local breakeven, and after another month of receipts I stand by it: local isn’t a subscription replacement, it’s a batch-workload absorber. Buying a 4070 to save money on your primary agent is buying the wrong tool for the wrong job.
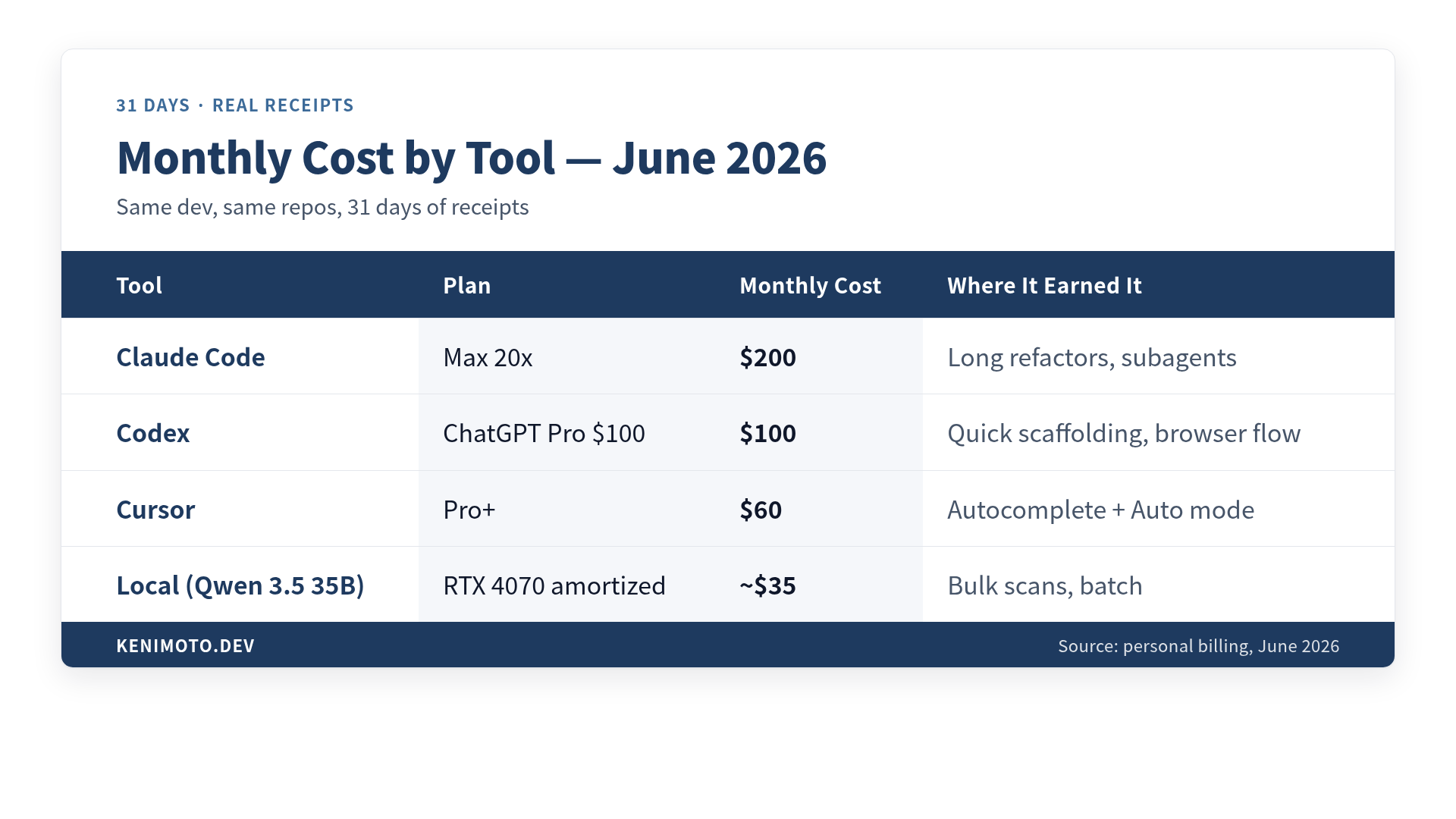
The 31-day scoreboard
Here is what actually landed on the credit card and what I got for it.
| Tool | Plan | Monthly cost | Where it earned it | Where it didn’t |
|---|---|---|---|---|
| Claude Code | Max 20x | $200 | Long refactors, subagent runs | Rate-limited twice on fan-out |
| Codex | ChatGPT Pro $100 | $100 | Quick scaffolding, browser-tab flow | Not for multi-file agent sessions |
| Cursor | Pro+ | $60 | Autocomplete + Auto mode | Credit drain if you force Sonnet |
| Local (Qwen 3.5 35B) | RTX 4070 amortized | ~$35 | Bulk scans, batch classification | Long context, frontier quality |
Total this month: $395. Yes, all four. The overlap is not wasted; each tool covered a workload the others charged 3-5x more to do.
Now the honest bit. If I had to pick one and drop the rest:
- If my month were 90% multi-file agent refactors and I could tolerate a rate limit, I’d keep Claude Code Max 20x and drop the other three. Roughly $200/month.
- If my month were 90% “one file at a time, browser tab open,” I’d keep ChatGPT Pro at $100 and use its Codex allocation. Roughly $100/month.
- If my month were 90% autocomplete-first coding with a couple of hard problems a week, I’d keep Cursor Pro at $20 with Auto default and pay-as-I-go for Sonnet. Roughly $20-$40/month.
The reason I keep all three is that none of my months look like “90% one shape.” Yours probably don’t either. But if you have to pick, pick against your actual dominant workload, not against the benchmark you saw on Twitter.
What I’ll drop for July
Two changes I’m making for the July run.
Cap the Claude Code subagent fanout at two. I hit the throttle twice this month, both times because I told it to run three subagents in parallel. Anthropic’s own doc reports 15x token spend on multi-agent runs; I don’t need three, two solves most of the problem, and I stay under the rate limit.
Stop reaching for Sonnet in Cursor. Pro at $20 with Auto default was clearly the right tier for me. The $40/month I saved on Cursor pays for something more useful than a habit.
If I write this post again at the end of July I’ll compare the two months side by side. The Twitter version of “which agent is cheapest?” is the wrong question. The version worth answering is “what is my usage shape, and which of these four bills matches it?”
That answer changed for me twice this month. It will probably change again. But I’ll have receipts.
Sources
- Simon Willison has been publishing usage-shape breakdowns for coding agents throughout 2026 that shaped my thinking on the token-shape question. Worth reading alongside this post: simonwillison.net.
- Claude Code and Anthropic API pricing: claude.com/pricing.
- ChatGPT and Codex pricing: chatgpt.com/pricing and developers.openai.com/codex/pricing.
- Cursor pricing: cursor.com/pricing.
- Anthropic multi-agent token math: Anthropic Engineering.
If you want the design-phase companion — how to pick between API, subscription, and local before the prototype — I wrote I Priced AI Agents Three Ways: API, Subscription, and Local last month. Same math, different starting question.
Was this article helpful?