Multi-Agent Decision Fatigue: I Counted 412 Micro-Choices a Day. The Harness Cut It to 38.
I read three changelogs in the same week. Anthropic shipped dynamic workflows so Claude Code can fan out to specialist subagents in parallel (Claude Code changelog). Cursor 3.2 added /multitask and cloud subagents you can leave running while the local one keeps going (Cursor changelog). OpenAI shipped Goal mode in Codex so it can drive at a target for hours (Codex changelog). The narrative is consistent across the three vendors: parallel agents are the productivity story of 2026.
I ran all three at once for a week. Then I started counting.
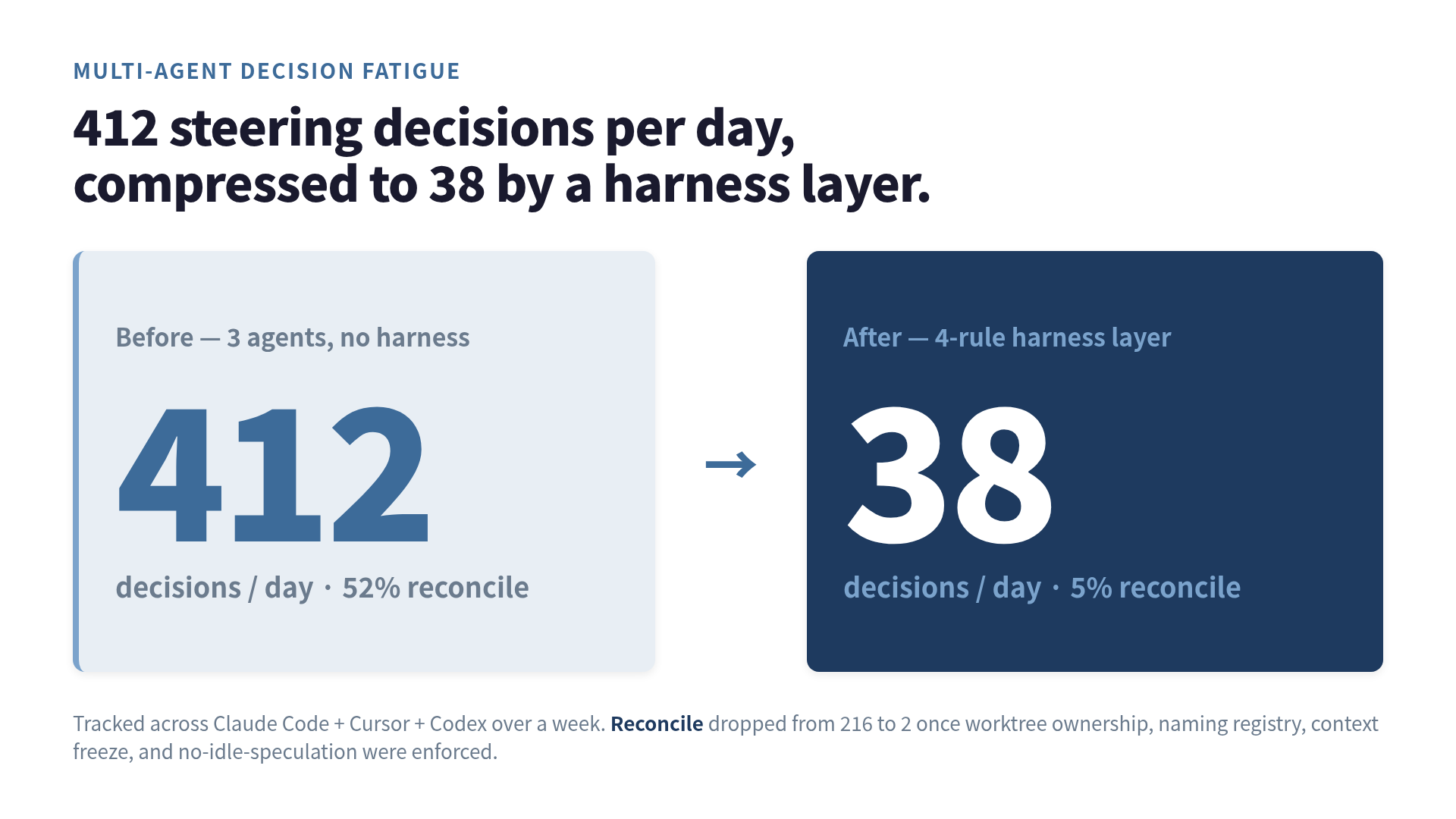
The number that came back was 412 micro-choices per day, more than half of them conflicting with another choice I had already made in another agent’s window. After I added a harness layer between me and the agents, the same week’s work needed 38.
This post is the count, the conflict pattern that produced it, and the four rules I now run as a thin orchestration layer above the three agents.
How I counted
A week, Monday to Friday, Claude Code in two terminals on two worktrees, Cursor open in the IDE on a third worktree, Codex in the browser for one long-running task. Every time I made a decision that was strictly about steering an agent, I tallied it in a tiny script that took a hotkey and logged a category. Categories were intentionally narrow:
- Accept — accept a diff or tool call
- Reject — reject a diff or kill a tool call
- Re-prompt — rewrite the prompt because the agent went the wrong way
- Switch — close one agent and open another for the same task
- Reconcile — fix a conflict between two agents’ outputs
I did not count typing code by hand, reading docs, or human-to-human conversations. Just steering decisions. The bar was deliberately low so I would not under-count.
Day one came back 386. Day two 421. The week averaged 412 a day. The single largest category, by a margin, was Reconcile.
Accept: 142 (34%)
Reject: 71 (17%)
Re-prompt: 84 (20%)
Switch: 26 (6%)
Reconcile: 216 (52%) ← over 100% because reconciles often include an accept tooReconcile was 52% of all decisions. I had not predicted that. The narrative in my head was that parallelism was about doing three independent things at the same time. The number was telling me parallelism was about resolving three overlapping things.
Why micro-choices accumulate
The classic citation for decision-quality decay under load is Vohs et al. (2008), which showed that subjects forced to make a sequence of choices performed worse on a subsequent self-control task. The replication picture has gotten muddier since the original ego-depletion debate, but the surface phenomenon is robust: long decision sequences degrade the speed and quality of the next decision in the sequence. The Danziger et al. (2011) parole-judges study made the same point in a high-stakes setting — favorable rulings dropped from roughly 65% early in a session to near zero just before a food break. People dispute the exact mechanism. Nobody disputes the curve.
What I noticed in my own week is that AI-agent micro-choices are worse than ordinary micro-choices because each one carries a hidden verification cost. CHI 2026 has work on AI oversight under cognitive load (CHI 2026 proceedings) showing that human oversight of AI outputs reduces some failure modes but introduces “attentional tunneling and cognitive load.” When I accept a diff from Claude Code, I am not just choosing yes. I am verifying that the diff matches the spec, that it does not collide with what Cursor wrote ten minutes ago, and that it does not duplicate what Codex is doing in a different worktree. Each accept hides a quiet three-way verification.
Three agents do not give you 3x throughput. They give you 3x output and a verification load that scales with the interactions between their outputs. Two parallel agents have one pair to reconcile. Three have three pairs. Four have six. The reconcile cost grows quadratically in agent count, which is exactly why my Reconcile category was the largest one.
The four conflict patterns
Looking at the reconcile log at the end of the week, almost every entry fell into one of four patterns. I will keep them short because the pattern matters more than the example.
- Same file, different intent. Claude Code in worktree A and Cursor in the IDE both touched
src/router.tswithin the same hour. Both diffs were correct in isolation. Together they fought over the same import block. - Same concept, different name. Codex named a helper
withTimeout. Claude Code named the same shaperunWithDeadline. Neither knew the other existed. I picked one name, then spent twenty minutes renaming the loser. - Stale assumption. Cursor was reading a CLAUDE.md that Claude Code had just rewritten in another session. The two agents disagreed about which logger to import because their context files had diverged by ninety seconds.
- Speculative duplication. Claude Code, idle on a worktree waiting for me, asked itself “is there a Skill for X?” and wrote one. Codex, on a different worktree, did the same thing. Two near-identical Skills got written. Neither was used.
None of these are bugs in the individual agents. All of them are predictable consequences of running three agents that share a workspace and a model of the world.
What the harness does
I will use the LangChain definition because it is the simplest one in circulation: agent = model + harness (Harrison Chase, The Anatomy of an Agent Harness, 2025). The model is the bit that generates code. The harness is everything around it: which tools it can call, what context it sees, when it is allowed to run, how its output is filtered before it reaches you.
What killed my Reconcile count was adding a thin harness layer above the three agents — not inside any one of them — that owned four specific things:
1. Single source of truth for which worktree owns which file. Before any agent starts a task, a worktree-map.yaml says which worktree is allowed to write which subtree. The other worktrees get told, in their system prompt, that those paths are read-only for them. Pattern 1 (same file, different intent) goes to zero because two agents physically cannot pick up the same file.
2. Naming registry checked at write time. A pre-commit hook reads a names.json listing helper-function names in use across worktrees. If an agent tries to introduce a name that collides, the hook rejects the diff and tells it to either reuse the existing name or pick a more specific one. Pattern 2 (same concept, different name) goes from “twenty minutes of renaming” to “rejected at commit, agent self-corrects.” I do not see it.
3. Context-file freeze during parallel runs. CLAUDE.md and the memory directory are frozen for the duration of any parallel session. Only one designated session can edit them, and edits queue. Pattern 3 (stale assumption) stops being an emergent race.
4. No idle speculation. Each agent’s system prompt explicitly forbids writing new Skills or helpers when it is waiting on me. Idle agents wait. They do not invent. Pattern 4 (speculative duplication) goes to zero.
Three of these four are five-line files. The fourth is a sentence in a prompt. None of them require an exotic framework. They just require admitting that the bottleneck is not how clever the model is — it is how cheaply you can resolve interactions between models.
What the count looks like now
After three weeks running on this harness, the daily steering count averages 38. The category breakdown is unrecognizable:
Accept: 21 (55%)
Reject: 6 (16%)
Re-prompt: 8 (21%)
Switch: 1 (3%)
Reconcile: 2 (5%)Reconcile collapsed from 216 to 2 because the harness moved most of the resolution from me to the rules. Accept went up as a share because the agents finish more of what they start. Switch fell because I rarely need to abandon one agent for another — the worktree map decides ownership ahead of time. Re-prompt is the most stubborn category, and I suspect it will not move much without better prompts on my side.
The throughput did not stay the same. It went up. The thing that was costing me wall-clock was not the agents being slow. It was me being slow at reconciling. Once the reconcile budget collapsed, the agents could actually run in parallel instead of serializing through my attention.
What I am watching next
Two changes on the vendor side are worth tracking. The first is dynamic workflows in Claude Code, which the changelog describes as parallel task handling with built-in verification. If “built-in verification” means the harness layer I am hand-rolling now ships inside the product, my four rules become obsolete in their current form. The second is Cursor 3.2’s worktree integration. If the IDE itself starts enforcing worktree-level write ownership, rule #1 stops being a worktree-map.yaml and starts being part of the editor.
The deeper bet is that the harness layer above the agents is going to be where the next two years of practical productivity wins live, not inside the models themselves. The model gets better by 10-20% a year. The harness around three models can compress your decision count by 10x in a weekend. That asymmetry is not going to flip soon.
If you take one number away, take this one: 412 to 38. The agents did not get faster. The choices got fewer.
Related on this blog: I Ran 3 Claude Code Sessions in Parallel for 8 Hours was where this whole investigation started — the collisions in that post are exactly what made me start counting.
Was this article helpful?