Conecté Claude a un MCP server de Chaos Engineering. Mató el staging 4 veces antes de encontrar el bug que llevábamos 6 meses ignorando.
Antes de empezar, una aclaración. Todos los experimentos de este post corrieron en staging. Producción quedó con doble candado: un bloque ## Chaos Rules en el CLAUDE.md que prohíbe blancos de producción, y un hook PreToolUse que hace exit 2 si aparece --env=production en cualquier comando de chaos. Los dos los muestro al final. Lo digo desde el inicio porque “dejé a Claude diseñar experimentos de chaos” es el tipo de frase que la gente lee de costado. Resumen: solo staging, doble candado, y todo el ejercicio fue supervisado de punta a punta.
Con eso fuera del camino: Steadybit lanzó a mediados de 2025 lo que describen como el primer MCP server de Chaos Engineering del mercado. Conecté Claude Code y le pedí, en una sola frase, que diseñara experimentos para probar la resiliencia del payment-service bajo presión de connection pool. Claude propuso cuatro experimentos. Tres terminaron sin violar SLO. El cuarto tumbó el staging por completo. Cuando rastreé la falla, no era un bug fabricado por el test. Era un patrón real de producción que aparecía en los logs desde hacía 6 meses y que nunca habíamos logrado reproducir: agotamiento del pool → tormenta de retry → rate limiter haciéndose self-DoS. Te muestro la corrida, el bug, y los 3 guardrails que ahora exijo antes de dejar a cualquier IA diseñar experimentos de chaos.
Este es el 6º post de una serie de harness que viene desde el 12 de mayo: sub-agentes, voice AI, separación en 3 roles, herramental de debug, y ahora chaos. Cada post se sostiene solo, así que si solo te interesa el capítulo de chaos, no hace falta leer los cinco anteriores. El hermano directo en el formato “dejé a la IA suelta por X horas” es el post de agente de IA, 24 horas, lecciones de seguridad.

Cómo conecté Claude al Steadybit MCP, en un párrafo
Steadybit anunció el 18 de junio de 2025 lo que describen como el primer MCP server para Chaos Engineering (Steadybit news / BusinessWire 2025-06-30). MCP es el Model Context Protocol abierto que Anthropic publicó a fines de 2024: una forma estandarizada para que un cliente LLM (Claude, Gemini, ChatGPT) llame a una herramienta externa con tipos estructurados en lugar de raspar texto libre. El MCP server de Steadybit expone el catálogo de experimentos, resultados pasados, post-mortems, y una herramienta de “diseñar nuevo experimento”. Conectas Claude Code o Claude Desktop, apuntas los dos al mismo contexto Kubernetes de staging, y escribes "diseña un experimento de stress de connection pool para payment-service" en la terminal. Te devuelve una spec parametrizada lista para aprobar.
El setup es plomería. La pregunta interesante es qué pasa cuando realmente corres lo que sale del otro lado.
AI-driven chaos en 2026: los 4 players que comparé
Antes de soltar la corrida, quería saber qué más había en el campo. Hoy hay 4 players que importan, y cada uno tira de una palanca distinta.
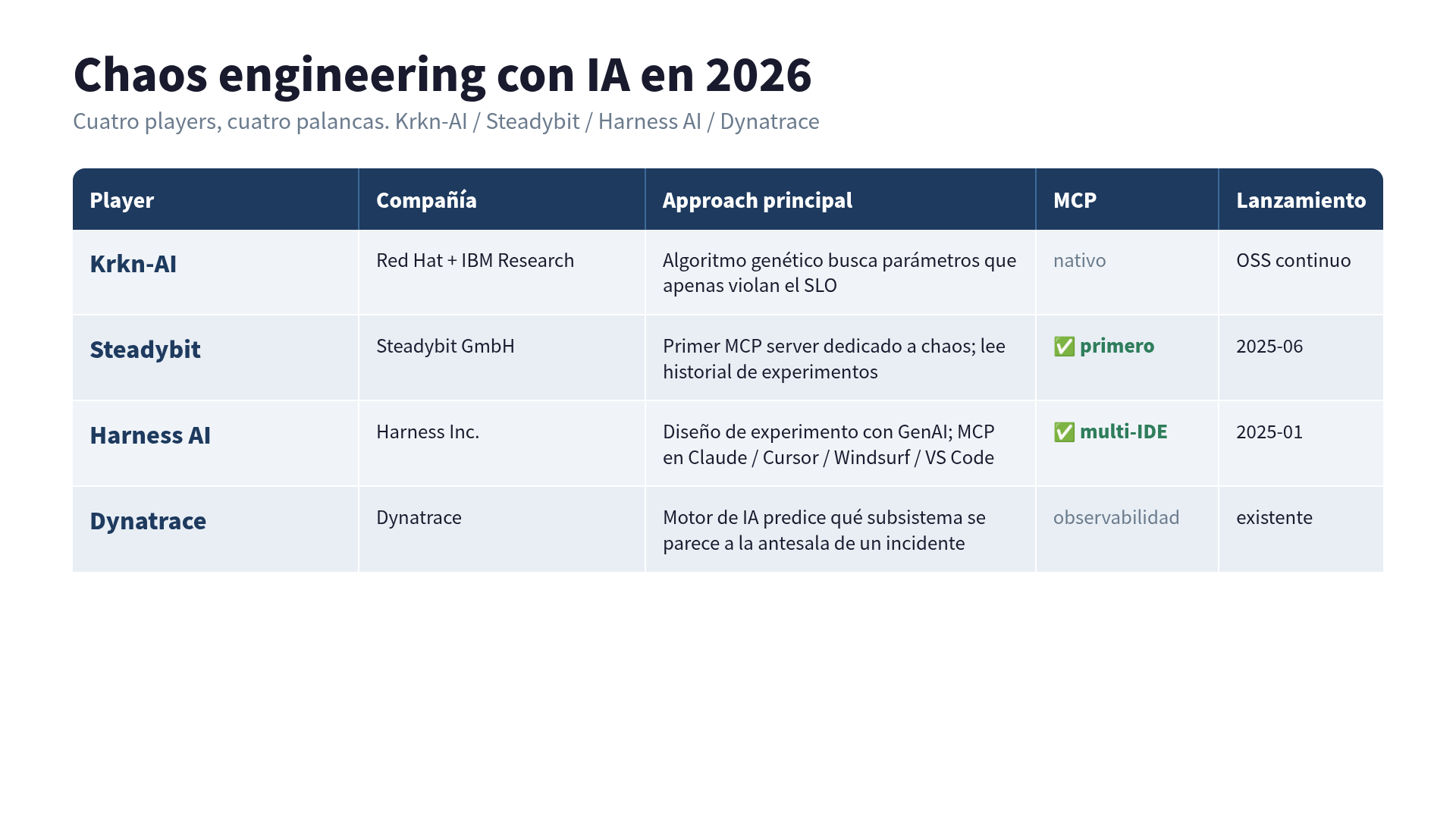
| Player | Compañía | Approach | MCP | Lanzamiento |
|---|---|---|---|---|
| Krkn-AI | Red Hat + IBM Research | algoritmo genético, OSS | nativo | OSS continuo |
| Harness AI | Harness Inc. | GenAI + MCP IDE | ✅ Claude/Cursor/Windsurf/VS Code | 2025-01 (GenAI), MCP posterior |
| Steadybit | Steadybit GmbH | MCP server dedicado | ✅ primer MCP de chaos | 2025-06 |
| Dynatrace | Dynatrace | predicción vía observabilidad | observability hooks | existente |
Krkn-AI es el framework open-source que Red Hat e IBM Research desarrollan en conjunto. La idea es poner un algoritmo genético al mando de la búsqueda: genera parámetros de experimento, evalúa cada uno contra tus SLOs (latencia, tasa de error, disponibilidad), puntúa, evoluciona las mejores combinaciones, repite. El objetivo son los experimentos “que apenas violan”: los que bajan un SLO de 99.9% a 99.85%, no los que rompen todo de una. Esos son los bugs peligrosos, los difíciles de reproducir. El writeup de Red Hat está en Red Hat Developer, y el código vive en krkn-chaos/krkn-ai.
Harness AI sacó funciones de chaos engineering con GenAI en enero de 2025 y después agregó herramientas MCP que funcionan con Claude Desktop, Windsurf, Cursor y VS Code. La propuesta es “describe lo que quieres en español, recibe un experimento parametrizado, ejecútalo desde el chat”. Si ya vives en el ecosistema Harness, es el camino con la curva de aprendizaje más baja.
Steadybit es el que usé acá, el primero en lanzar un MCP server dedicado a chaos en junio de 2025. El diferencial es el acceso al historial de experimentos: el LLM no solo diseña experimento nuevo, lee tus runs pasados y post-mortems, y basa las sugerencias en tu historia de incidentes específica.
Dynatrace juega al revés. El motor de IA aprende el comportamiento normal del sistema y predice cuándo un patrón actual se parece a la antesala de algún incidente pasado. En vez de que tú propongas una hipótesis para verificar, la plataforma te dice qué subsistema merece atención de chaos a continuación.
Si solo corres un experimento por trimestre, el ángulo de predicción de Dynatrace queda grande. Si tienes equipo de research y Kubernetes, el algoritmo genético de Krkn-AI es el más profundo. Si ya estás en Harness o Steadybit, el MCP saca el impuesto del dashboard. Los 4 no compiten de verdad: se apilan en capas.
Los 4 experimentos que Claude propuso
Volviendo a la corrida real. El prompt fue una frase. La respuesta fue una lista numerada con 4 experimentos, cada uno con servicio-objetivo, tipo de falla, magnitud, duración, SLO de rollback y blast radius. Parafraseo en lugar de pegar literal, porque la spec real era YAML y la estructura legible por el LLM no es la parte interesante. El diseño del experimento sí lo es.
Experimento 1: pool a 30% menor, 3 minutos, un pod. Recorta el max del connection pool de 100 a 70 en una sola réplica del payment-service. SLO gate: tasa de error abajo de 1%. Resultado: verde. La latencia subió un 12%, pero el error quedó en 0.2%, bien dentro del límite. Las otras réplicas absorbieron el tráfico. Es el experimento que un SRE humano propondría primero.
Experimento 2: pool 50% menor con retries default, 3 minutos, dos pods. Misma falla, magnitud más profunda, dos réplicas en lugar de una, con el retry-on-failure de la librería-cliente prendido. SLO gate: error abajo de 1%, p99 abajo de 800 ms. Resultado: verde otra vez. La latencia fue a ~640 ms p99, el error a 0.4%. Dentro del límite. La capa de retry absorbió la presión del pool.
Experimento 3: pool 70% menor con timeout más corto, 3 minutos, dos pods. Ahora el timeout bajó de 5 s a 1.5 s mientras el pool fue a 30. Hipótesis: bajo alta presión, ¿el timeout corto ayuda liberando conexión más rápido, o estorba cortando la petición a la mitad? Resultado: sorprendentemente todavía verde. Error 0.7%, p99 bajó a ~520 ms porque las llamadas lentas se cortaban temprano. Casi paro acá. Tres verdes seguidos parecían prueba de resiliencia.
Experimento 4: pool 90% menor con retry sin límite, 5 minutos, tres pods. Este fue. Pool en 10 conexiones por pod, presupuesto de retry prácticamente infinito (default de este cliente, no sobrescrito en el config), tres réplicas golpeadas al mismo tiempo. SLO gate: error abajo de 1%. Resultado: no verde. En los primeros 90 segundos, la tasa de error saltó de 0.5% a 23% en línea vertical, la p99 saltó de 200 ms a 14 segundos, y el staging quedó inalcanzable desde el gateway upstream. Steadybit hizo auto-rollback en la violación de 1% del SLO, pero a esa altura el daño ya era un servicio completamente trabado.
Los tres verdes iniciales no eran prueba de resiliencia. Eran prueba de que el blast radius era lo bastante pequeño como para absorberse. En el cuarto, ensanché el radio un poco más allá de lo que el sistema absorbía, y la patología que dormía abajo salió a la luz.
Le escribí al Slack que el incidente en staging era “planificado”. El on-call no se rió. Me señaló que el canal de post-mortem todavía tenía pineado el incidente del trimestre pasado. Lo dejé que actualizara el pin con el de hoy.
El bug que llevábamos 6 meses ignorando
Yo esperaba que la falla del staging fuera una rareza de staging: env var distinta, sidecar raro, timing que no reproduce en prod. La rastreé igual. La cadena tenía 3 piezas, cada una sola estaba documentada y bien, y juntas se volvieron enfermedad.
Pieza 1: agotamiento del connection pool. Pool en max 10, tres pods bajo tráfico normal. Toda petición que necesitaba conexión nueva esperaba o fallaba. Estándar. Sin sorpresa.
Pieza 2: retries sin tope en el servicio que llamaba. El servicio upstream que llamaba al payment-service tenía retry prendido, con tope solo por tiempo-por-intento, no por número de intentos. Cuando payment-service empezó a devolver error de pool agotado, el caller hizo retry. Cada retry abría una conexión TCP nueva, que entraba a la cola del pool, que daba timeout, que disparaba otro retry. Tres retries se convirtieron en nueve, después en 27. En segundos, la concurrencia de salida del caller estaba un orden de magnitud arriba de la línea base.
Pieza 3: el rate limiter del propio caller. Esta pieza me costó media hora verla. El caller tenía un rate limiter de auto-protección en la ruta outbound: “no dejes que este servicio haga más de N peticiones por segundo a ningún downstream”. En operación normal, N nunca llegaba a tocarse. En la tormenta de retry, el caller pasó su propio rate limiter de salida y empezó a rechazar sus propios retries. La aplicación interpretó el rechazo como falla del downstream y disparó todavía más retry. El caller se estaba haciendo DoS a sí mismo, usando su propio rate limiter como arma. El payment-service downstream no se recuperaba, porque el tráfico nuevo no podía atravesar el self-DoS del caller para avisar que el pool ya estaba libre.
Volví sobre los logs de producción de los últimos 6 meses buscando la firma de “rate limiter rechazando retry en el outbound” de este servicio. Encontré 11 eventos. Cada uno duraba de 4 a 90 segundos, cada uno se auto-resolvía antes de que alguien terminara de abrir el Grafana, y cada uno terminaba en el balde de “transitorio, no accionable”. Es exactamente el patrón que la fitness function del Krkn-AI busca cazar: falla que vive justo después de la frontera del SLO, lo bastante corta para que el humano deje de mirar, lo bastante real para importar.
La corrección no fue glamorosa. Limitamos los retries a 2 con jitter, cambiamos el rate limiter de salida para comportarse como circuit breaker en lugar de rechazo duro, y agregamos una métrica para esa secuencia específica (pool-exhaust → spike de retry → rechazo-outbound-en-retry) para que la próxima vez despierte a alguien en lugar de auto-curarse invisible.
Los 3 guardrails que ahora exijo
No soy anti-autonomía. Justo el día anterior publiqué 10 hábitos de debug en plantillas de prompt para Claude. Pero “IA diseña chaos” sin guardrails fue la forma más rápida que he encontrado de matar staging. Tres cosas entran en todo proyecto antes de que el MCP server se acerque a un ambiente real.
Guardrail 1: CLAUDE.md guarda la política. Bloque corto, menos de 20 líneas, que nombra las prohibiciones y los SLO gates. Plantilla para copiar:
## Chaos Rules
- Los experimentos de chaos corren solo en staging. Producción está prohibida
como blanco, incluyendo cualquier cluster, namespace o servicio marcado
production=true.
- Todo experimento declara SLO gate (tasa de error, latencia, disponibilidad)
que hace auto-rollback si se viola.
- El blast radius se escala: arranca en 10% de pods, sube a 25%, después 50%.
Saltar una etapa exige aprobación humana en el prompt.
- Tres experimentos verdes seguidos no declaran resiliencia. Propón blast
radius mayor o tipo de falla nuevo antes de parar.
## Chaos Workflow
1. Confirmar que el ambiente objetivo es staging. Rechazar si no.
2. Proponer el experimento con SLO gate, blast radius y rollback declarados.
3. Esperar aprobación humana en el prompt antes de llamar la tool de run del MCP.
4. Streamear métricas durante la corrida. Ante violación de SLO, llamar rollback.
5. Después de la corrida, escribir un post-mortem de un párrafo con el resultado.La parte difícil del CLAUDE.md es mantenerlo lo bastante corto como para que se cargue en contexto en cada turno. La guía de Anthropic es quedarse abajo de unas 100-150 líneas. Gastar 16 de esas líneas en reglas de chaos es un buen intercambio para no matar staging el primer día.
Guardrail 2: hooks PreToolUse fuerzan la política. CLAUDE.md es el cerebro. Los hooks son el reflejo. El cerebro se puede ignorar bajo carga. El reflejo no.
{
"hooks": {
"PreToolUse": [
{
"matcher": "mcp__steadybit__run_experiment",
"hooks": [
{
"type": "command",
"command": "node ~/.claude/hooks/block-prod-chaos.js"
}
]
}
]
}
}El script de bloqueo inspecciona la spec del experimento buscando cualquier marcador de producción. Si aparece env: production, cluster: prod o namespace: prod-* en cualquier lugar del payload, escribe la razón a stderr y hace exit 2 para bloquear la llamada. Este trozo me salvó al menos una vez. El LLM, a mitad de conversación, sugirió amablemente promover un experimento “para confirmar en prod”. El hook dijo que no antes de que el MCP server lo viera.
El mismo hook además verifica que el SLO gate esté declarado con valor numérico y que la etapa del blast radius sea la anterior +1. ¿Spec solo con número mágico? Bloqueado. ¿Saltar la etapa 2 del blast radius? Bloqueado. El reflejo tiene exactamente la forma de la regla.
Guardrail 3: el propio MCP server sostiene el candado de SLO. La tercera capa está del lado de la plataforma. En Steadybit (e igual en Harness, en Krkn y compañía), la configuración del experimento toma un predicado rollback_on que la propia plataforma evalúa en tiempo real sobre las métricas. Si la tasa de error pasa el 1% durante 30 segundos, la plataforma para el experimento independientemente de lo que el LLM o el hook local hagan. Es la única de las tres capas que sobrevive si el LLM y el agente local están comprometidos al mismo tiempo. También es la que más equipos olvidan, porque exige opiniones sobre tus SLOs que nadie quiere tipear en un YAML. Tipéalas igual.
Una prueba útil: agarra a alguien al azar del equipo, le entregas el CLAUDE.md y el archivo de hooks, y le preguntas “¿podrías, de mala fe, diseñar un experimento que pegue en producción?”. Si la respuesta es “sí, editando el CLAUDE.md”, el candado de SLO de la plataforma es el que lo agarra. Si la respuesta es “sí, sacando el hook”, el candado de SLO de la plataforma es el que lo agarra. Las tres capas no son redundantes: fallan de formas distintas.
La separación en tres roles que describí en un post anterior (observer, strategist, marketer) mapea limpio a chaos: el CLAUDE.md es el strategist (define política), los hooks son el observer (atrapan lo que pasa), el MCP server es el ejecutor debajo de los dos. Mantener las capas separadas es lo que impide que el agente de IA termine siendo los tres sin darse cuenta.
Chaos Engineering 2.0: las 4 corrientes que convergen
Si alejas la cámara, hay un paper de review de 2024 titulado Chaos Engineering 2.0: A Review of AI-Driven, Policy-Guided Resilience for Multi-Cloud Systems (página del journal) que defiende tres pilares para el stack moderno: planificadores con IA que diseñan experimentos, inyección a nivel de service mesh que no exige tocar código de aplicación, y guardrails de política que fuerzan disciplina de blast radius y SLO. El mismo paper reporta que el 89% de las organizaciones encuestadas hoy corren multi-cloud, que es el ambiente donde estos modos de falla (drift de DNS entre clouds, ciclo de vida de token IAM distinto, rate limiter local de región) viven de verdad.
Más reciente, el paper de arxiv ChaosEater (2025) da el siguiente paso: ciclo de chaos completamente orquestrado por LLM, donde el modelo asume diseño, ejecución y análisis del experimento bajo guardrails de política. Es la misma dirección que los cuatro productos de arriba están caminando, vista desde el lado de la investigación.
Cuatro corrientes convergen (chaos engineering, observabilidad, IA / LLMs, plataforma), y no es una slide de marketing. Es el workflow real dentro del cual ocurrió mi accidente de staging. El chaos engineering aportó el experimento. La observabilidad aportó el stream de métrica que detectó la violación de SLO en 90 segundos. El LLM aportó el diseño del experimento y, después, ayudó a leer la cadena de log que ancló el bug de producción. La ingeniería de plataforma (Steadybit + hooks + CLAUDE.md) mantuvo el blast radius fuera de producción.
Quita cualquiera de las cuatro y la historia termina distinto. Sin LLM, nadie del equipo habría propuesto el experimento 4. Parecía obviamente imprudente. Sin observabilidad, la violación tarda minutos en notarse. Sin guardrail de política, “vamos a confirmar en prod” pasa de verdad. Sin chaos como práctica deliberada, el bug queda invisible otros 6 meses más.
Qué le diría a quien va a intentar esto la próxima semana
Si quieres intentar la misma cosa sin tumbar tu propio staging a las 11 de la noche, esto es lo que haría distinto con retrovisor.
Empieza con el experimento 1 solo, en un único namespace, con el blast radius capeado en 10% de los pods. Trata al primer verde como señal de ampliar el blast radius, no como declaración de victoria. El experimento interesante es el que llega justo después del punto donde el sistema puede absorber.
Escribe el CLAUDE.md y los hooks antes de conectar el MCP server. No después, no en paralelo, antes. La tentación cuando tienes un juguete nuevo es jugar con él por una hora y agregar los guardrails después. Esa hora es cuando staging se muere. Es también la hora en la que tienes menos paciencia para escribir reglas.
Mantén los prompts post-corrida cortos. “Resumí lo que falló, qué SLO violó, y la causa raíz más probable” ya alcanza. Prompt largo después de violación de SLO arrastra al LLM a modo narrativa, que es el modo equivocado. Quieres al LLM en modo evidencia, no en modo cuento.
Lleva el hábito del post-mortem del chaos al AI-coding en general. Este post existe porque tenía una página de notas del incidente de 90 segundos, en el mismo formato de nuestros docs de incidente normales. Sin esa página, este sería un post de vibe. Con ella, tengo un párrafo por pieza de evidencia y una corrección que entró a prod la misma semana.
La IA diseña chaos más rápido que cualquier SRE con el que haya trabajado. Sin los tres guardrails, mata staging más rápido también. Ponle los tres, y obtienes la versión donde el LLM encuentra el bug que llevabas medio año sin encontrar, y el on-call del fin de semana se queda con su fin de semana.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?