Pillé a Claude escondiendo mi bug 3 veces seguidas. Después convertí 10 hábitos de debug en prompts.
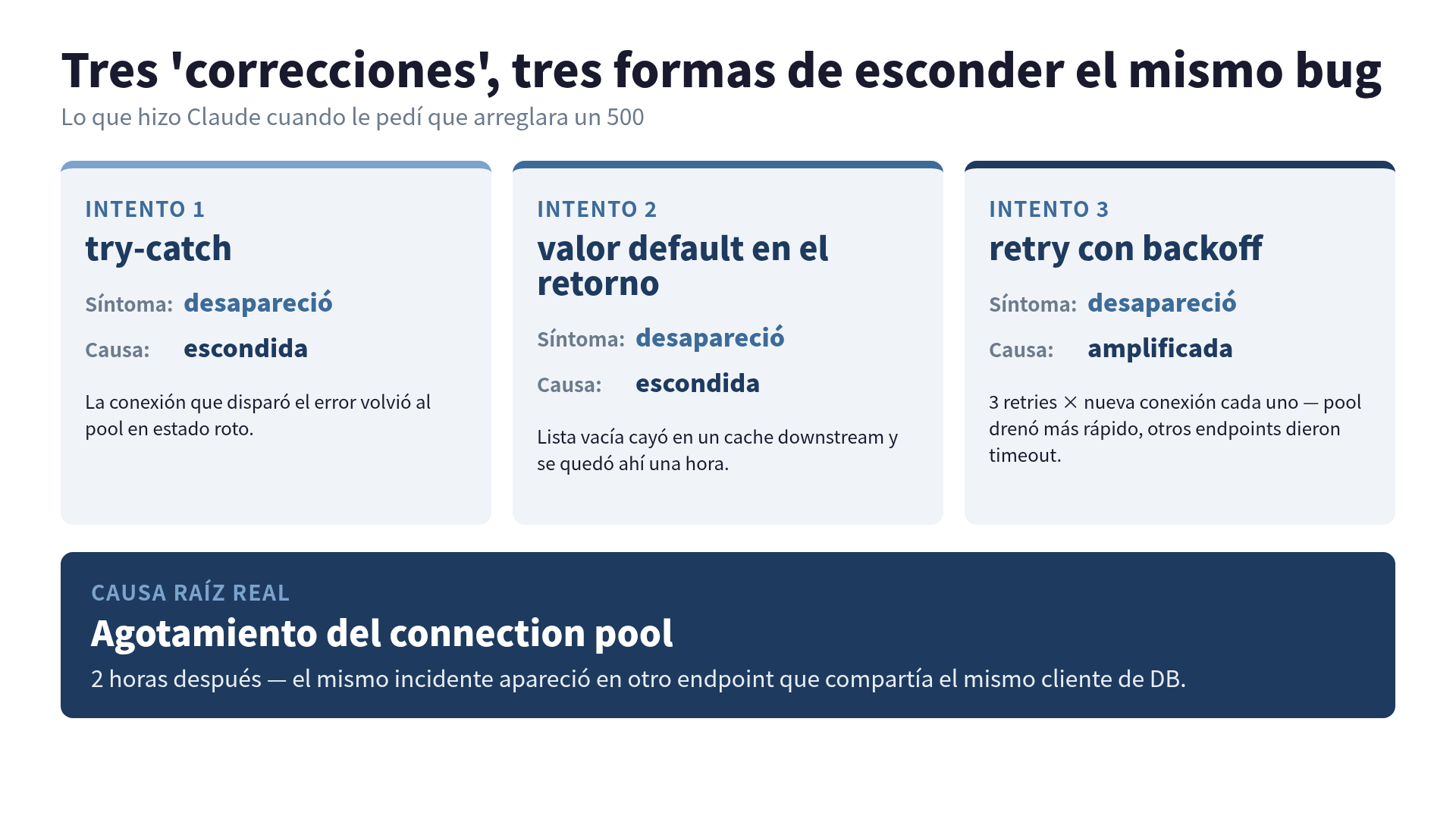
Le pedí a Claude que arreglara un error 500 que salía de uno de mis endpoints de API. Primer intento: envolvió la llamada en try-catch y logueó el error. Segundo intento: puso un valor default en el retorno para que el caller no reventara. Tercer intento: agregó retry con exponential backoff.
El 500 desapareció. Subí la tercera “corrección” a producción con total confianza. Dos horas después, el on-call se despertó. El mismo incidente se había mudado a otro endpoint que compartía el mismo cliente de base de datos. La causa real era agotamiento del connection pool. Claude no estaba arreglando el bug. Lo estaba escondiendo de tres formas distintas.
Hoy cuento cómo convertí 10 hábitos de debug en plantillas de prompt para que Claude no me vuelva a hacer eso. Además, dejo dos archivos que escribes una vez y no tocas más: un bloque para CLAUDE.md y dos hooks (PreToolUse y PostToolUse) listos para copiar.
Las 3 “correcciones” que casi se publicaron
Cada uno de los tres intentos se veía correcto si lo mirabas por separado.
Intento 1 — try-catch. El handler ahora atrapaba la excepción, la logueaba y devolvía 500 al usuario. Desde el punto de vista de la API, mejoró. Desde el punto de vista del bug, la conexión que disparó el error volvía al pool en un estado roto.
Intento 2 — valor default en el retorno. La función ahora devolvía una lista vacía en lugar de lanzar excepción. El 500 desapareció de ese endpoint. La inconsistencia que la lista vacía generó cayó en un cache downstream y se quedó ahí una hora.
Intento 3 — retry con exponential backoff. Tres retries, cada uno abriendo una nueva conexión. El pool se drenó más rápido. El 500 desapareció de ese endpoint porque la llamada ahora tenía éxito en el segundo o tercer intento. Otros endpoints que compartían el mismo pool ahora empezaron a dar timeout.
En los tres, el síntoma desapareció del endpoint que yo había pedido revisar. La causa solo se mudó de barrio. Le pedí a Claude que debugueara, pero no le pasé ninguna regla contra suprimir el síntoma, así que suprimió el síntoma, porque eso es lo que la predicción de next-token quiere hacer.
Sobre cómo este tipo de cosas también rompe la infraestructura alrededor del agente de IA (no la salida del modelo, sino el bus y el dispatcher), escribí una versión más alegre en mi post sobre 9 bugs en mi pipeline de IA (en inglés). Ese post hablaba de la plomería alrededor del modelo. Este habla del modelo escribiendo la plomería.
Por qué la IA cae en suprimir el síntoma
La Stack Overflow Developer Survey de 2025 reportó que cerca del 80% de los desarrolladores profesionales usaba o planeaba usar herramientas de IA, y la fracción que de verdad confiaba en la salida había bajado respecto del año anterior. Las publicaciones posteriores que he ido leyendo insisten en lo mismo: los bugs del código generado por IA se concentran en errores de lógica y en manejo de entrada/salida, con una densidad notoriamente mayor que el código humano de seniority equivalente. La cifra más citada anda alrededor de 1.7x de densidad de bugs, aunque cada estudio mide distinto y vale revisar la metodología antes de citar de memoria.
El mecanismo no es ningún misterio. Un LLM predice el próximo token más plausible dado el contexto. “Patrón de error handling” es una de las cosas más sobre-representadas en sus datos de entrenamiento. Try-catch, null-check, default en el retorno, retry: estadísticamente, son las ediciones que más aparecen cuando alguien escribe “arregla este error” en un repositorio público. El modelo está haciendo exactamente lo que aprendió a hacer.
Lo que falta es otro tipo de token. “Todavía no identifico la causa raíz. Sigo investigando.” Esa frase es rara en los datos de entrenamiento porque los humanos rara vez la commiteamos. Commiteamos la corrección, no el “todavía no la encontré”. Así que el modelo nunca aprendió a estar por default en “sigo mirando”.
Hay que ponerle ese token a mano. Para eso sirve la siguiente sección.
10 hábitos de debug → 10 plantillas de prompt
Cada item mapea a un hábito clásico de debug. Cada uno es una frase que pego en el prompt o en el CLAUDE.md, según qué tan permanente quiera que sea.

1. Duda del input. “Antes de proponer una corrección, confirma que los logs que estás leyendo están completos y que el monitoring en el que confías realmente reporta el estado que crees que reporta.” Este es el que Claude más se salta. Diagnostica feliz desde un archivo de log que está rotado a la mitad.
2. Reproduce antes de corregir. “Reproduce el bug localmente y muestra los pasos mínimos. Si no puedes reproducirlo, dilo explícitamente y detente.” El “detente” es donde está el trabajo. Le cierra la puerta a adivinar.
3. Encuentra la frontera. “Identifica la frontera entre el comportamiento que funciona y el que está roto. ¿Cuál es el último componente que devuelve datos correctos?” Empuja al modelo a dejar de adivinar línea por línea y empezar a reducir capa por capa.
4. Diferencia contra un estado bueno conocido. “Compara el código actual con el último estado funcional conocido. Ejecuta git log --oneline -20 e identifica cualquier cambio que pueda correlacionar con la ventana de falla.” Este es el prompt que hace aparecer el commit que nadie recuerda haber hecho.
5. Arma una línea de tiempo. “¿Desde cuándo está fallando? ¿Es súbito o gradual? Mapea la tasa de error contra los horarios de deploy, picos de tráfico y cambios de configuración.” Súbito + correlacionado con deploy es un bug. Gradual + descorrelacionado es otro bug completamente distinto. Confundirlos es como se apilan tres “correcciones”.
6. Audita retry, cache y timeout. “Lista cada retry, cache y timeout en el camino. Para cada uno, describe qué pasa cuando la llamada subyacente está lenta pero no fallida.” Este, si lo hubiera tenido, habría detectado el agotamiento del pool en la primera pasada.
7. Busca caminos de amplificación. “¿Hay algún camino donde un error pequeño se multiplique? ¿Una llamada fallida que dispara tres retries, cada uno abriendo una nueva conexión, cada uno agregando latencia a la siguiente?” Si el retry storm está adentro de un autoscaler, te llevas de regalo una instance storm.
8. Agrega observabilidad, no adivines. “Si no tienes suficiente observación para identificar la causa, propón qué líneas de log o traces específicos agregar. No propongas corrección todavía.” Eso convierte “no sé” en “mide acá”, que es una respuesta mucho más útil que una corrección falsa.
9. Simplifica el sospechoso. “Quita componentes no esenciales del camino que falla hasta que el bug sea reproducible en la forma más simple posible. ¿Cuál es el input más chico que todavía lo dispara?” La mayoría del bug, casi siempre, no estaba en la parte que estabas mirando.
10. Rompe a propósito. “Para verificar una hipótesis, propón un cambio intencional que debería empeorar o mejorar el bug. Predice el resultado antes de ejecutarlo.” Convierte el debug de observación en experimento. Y atrapa las mentiras que te está contando el monitoring.
Los 10 hábitos vienen del trabajo clásico de David Agans (Debugging: The 9 Indispensable Rules, 2002) más un par de años propios de tropezar con pipelines de IA. La versión “cómo se traduce a prompt y cómo cabe en CLAUDE.md” la fui armando incidente por incidente. Esta lista es el estado actual.
Persistir las reglas en CLAUDE.md
Pegar 10 frases en cada prompt no escala. CLAUDE.md es donde se aplican las reglas.
La guía de Anthropic con la que vuelvo siempre es mantener CLAUDE.md en algo entre 100 y 150 líneas, para que entre en el contexto en cada turno. Gastar 12 de esas líneas en debug es buena inversión.
## Debugging Rules
- No escribas código de corrección hasta haber identificado la causa raíz.
- No suprimas síntomas. Si el síntoma desapareció pero la causa sigue desconocida, eso no es una corrección.
- Antes de corregir, escribe un test que falle y que reproduzca el bug.
- Después de corregir, ejecuta la suite de tests completa y reporta cualquier test nuevo que falle.
- Si tres intentos fallan en fila sobre el mismo bug, detente. Resume qué intentaste, qué descartaste y qué hipótesis queda, y pide input humano.
## Debugging Workflow
1. Root Cause Investigation: lee logs, traces y el camino del código.
2. Pattern Analysis: busca el mismo anti-patrón en otros lugares del codebase.
3. Hypothesis Testing: escribe un test que falle si y solo si la hipótesis es correcta.
4. Implementation: solo después de que 1-3 hayan pasado.El detalle importante es que esto son restricciones, no instrucciones. “No escribas código de corrección hasta…” funciona mejor que “investiga primero”. El formato de restricción es lo que evita que la máquina de next-token salte alegremente al paso siguiente.
Esta capa de equipamiento (restricciones en el prompt, comportamiento en los hooks, información en MCP) es la misma que usé cuando separé un agente grande en Observer, Strategist y Marketer. Esta es la semana de debug del mismo arsenal.
Automatizar reflejos con hooks
CLAUDE.md es el cerebro. Los hooks son los reflejos. Dos importan para debug.
PreToolUse: bloquear comandos destructivos. A mitad del debug, el modelo a veces sugiere algo tipo rm -rf node_modules. En un mal día, sugiere un DROP TABLE puro. Un hook PreToolUse intercepta la llamada a la herramienta Bash, hace un grep al string del comando contra una denylist corta, y sale con exit 2 para bloquear. Claude Code trata el exit code 2 de un hook PreToolUse como “esta llamada está denegada, avísale al modelo el motivo”.
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [{
"type": "command",
"command": "if echo \"$TOOL_INPUT\" | grep -qE 'rm\\s+-rf|DROP\\s+TABLE'; then echo 'BLOCK: destructive command' >&2; exit 2; fi"
}]
}
]
}
}PostToolUse: ejecutar tests después de editar. Matcher Edit|Write, command ejecuta tu suite de tests o al menos un subset rápido. El modelo ahora ve el test fallar en el turno siguiente y reacciona en el mismo turno en que lo creó, en lugar de acordarse 30 mensajes después. La referencia oficial de hooks de Claude Code cubre los matchers y la convención de exit codes en detalle. Vale leerla una vez antes de escribir el tuyo.
Estos hooks no son magia. Son guardas baratas que cubren el escenario en que el modelo está intentando “ayudar rápido” y por eso elige el atajo destructivo. La combinación CLAUDE.md + PreToolUse + PostToolUse es la capa de equipamiento del debugger de IA.
Cuando 3 correcciones escondidas seguidas significan “frena”
La regla más útil, la única que me habría ahorrado el on-call de esa noche:
Si tres intentos seguidos fallan en arreglar el mismo bug, detente y escala.
El 3 no tiene magia. Es el punto donde el costo de un intento más supera el costo de admitir que el bug es estructural. En el tercer intento, el modelo suele estar haciendo pattern-matching arriba de pattern-matching, y un ojo humano sale más barato que un cuarto retry.
“Deja que Claude debuguee” es media verdad. Es rápido, sí. Solo que por default es rápido en esconder el problema, a menos que lo armes diferente. Los 10 prompts lo arman. CLAUDE.md los recuerda por ti. Los hooks atrapan lo que se cuela. Ninguno cuesta caro. La llamada de on-call a las 11 de la noche, sí.
Fuentes:
- 2025 Stack Overflow Developer Survey, AI section
- Closing the developer AI trust gap (Stack Overflow Blog, feb 2026)
- Claude Code Hooks reference
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?