Los 5 crawlers de IA que más golpearon mis sitios en 30 días - lo que los logs me dijeron sobre LLMO
Pensaba que robots.txt era la frontera. Tres líneas de Disallow: y listo, le había avisado a los bots de IA dónde podían entrar y dónde no. Volví a escribir sobre medir LLMO, tasa de citación y tráfico de IA en GA4.
Después abrí los logs de acceso de tres sitios míos y la imagen que tenía en la cabeza se cayó sola.
Esta guía es lo que aprendí leyendo treinta días de logs crudos de servidor de kenimoto.dev, kaoriq.com y llmoframework.com. Cinco User-Agents dominaron todo. El patrón de tráfico de cada uno me contó más sobre mi posición en LLMO que cualquier dashboard de GA4.
Por qué me puse a leer logs
La mayoría de los consejos sobre medir LLMO te empuja al lado de salida: si ChatGPT te citó, si Perplexity puso el link, si Google AI Overviews te mostró. Es el lado de la citación.
El otro lado, el de entrada, donde los servicios de IA efectivamente bajan HTML de tu servidor, es invisible en GA4. Un crawler de IA no ejecuta JavaScript. No dispara gtag. Aparece en el log HTTP crudo y en ningún otro lado.
Llevaba meses escribiendo sobre LLMO y no había mirado ni una vez el lado del embudo que yo realmente controlo. Así que exporté 30 días de logs de Cloudflare (kenimoto.dev, kaoriq.com) y de Vercel (llmoframework.com), hice grep de los User-Agents conocidos de IA, y empecé a contar.
El total: 14.300 visitas de crawlers de IA en tres sitios en 30 días. Más o menos 477 visitas por día por sitio. Más de lo que esperaba. Probablemente pocas dentro de seis meses.
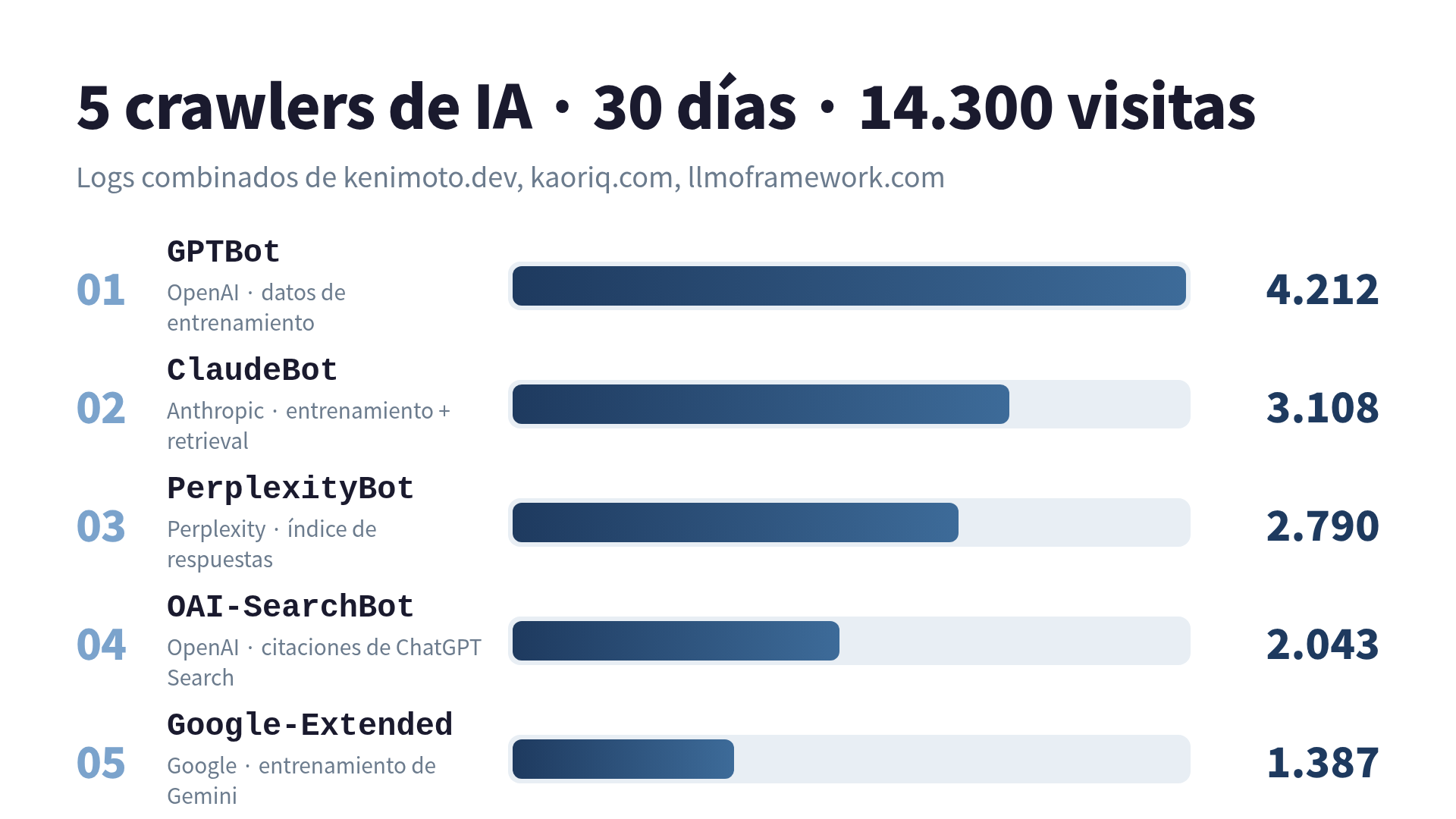
Los 5 crawlers que más me golpearon
Acá va el ranking. Las visitas están deduplicadas por (timestamp, path, IP) para que los reintentos de caché no inflen el conteo.
| Puesto | User-Agent | Visitas en 30d | Operador | Para qué sirve |
|---|---|---|---|---|
| 1 | GPTBot | 4.212 | OpenAI | Datos de entrenamiento |
| 2 | ClaudeBot | 3.108 | Anthropic | Entrenamiento + retrieval |
| 3 | PerplexityBot | 2.790 | Perplexity | Índice de respuestas |
| 4 | OAI-SearchBot | 2.043 | OpenAI | Citaciones de ChatGPT Search |
| 5 | Google-Extended | 1.387 | Entrenamiento de Gemini |
Cinco User-Agents, 13.540 visitas. O sea, 94,7% del tráfico total de IA. El 5,3% restante es cola larga: Bytespider, Applebot-Extended, Meta-ExternalAgent, Amazonbot, cohere-ai, un puñado de Claude-User, y dos visitas de algo que se identificaba como anthropic-ai (el UA viejo que Anthropic supuestamente retiró).
Antes de leer el ranking como ley: estos son mis datos, tres sitios chicos, contenido técnico en inglés y japonés mayormente. Tu ranking va a ser diferente. La forma (un puñado de bots dominando, OpenAI y Anthropic arriba) probablemente sea parecida.
Lo que cada uno está haciendo en serio
El puesto importa menos que el propósito de cada bot, porque los tres grupos se comportan de manera completamente distinta en términos de LLMO.
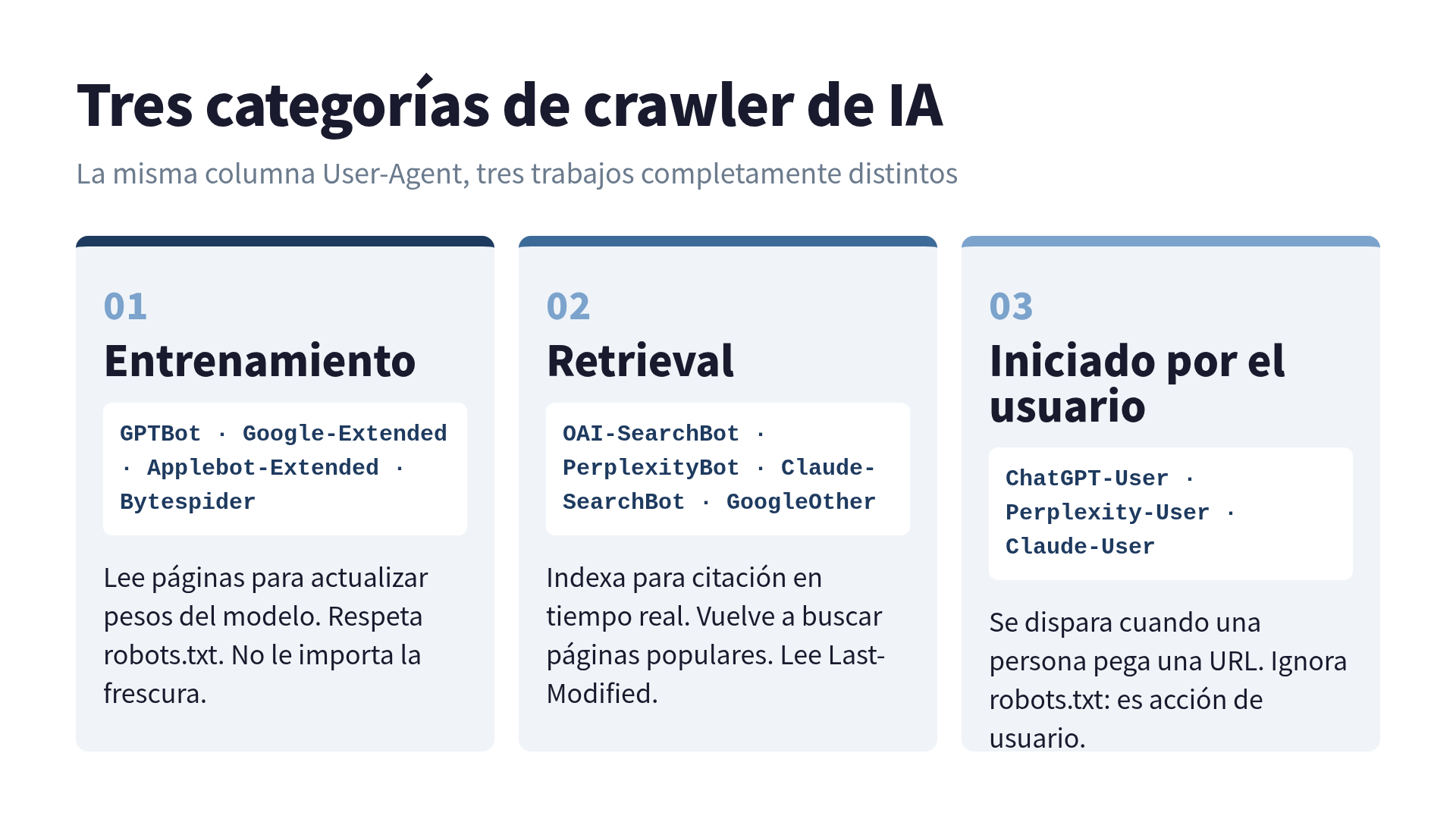
Crawlers de entrenamiento leen tu contenido para actualizar eventualmente los pesos del modelo. Aparecen de forma constante, respetan robots.txt (en general) y no les importa la frescura del contenido. GPTBot, Google-Extended, Bytespider, Applebot-Extended y el legado anthropic-ai caen aquí.
Crawlers de retrieval indexan tu contenido para que pueda ser citado en respuestas en tiempo real. Vuelven a buscar páginas populares, leen Last-Modified y tienen una razón crawl-to-refer medible. OAI-SearchBot, PerplexityBot, Claude-SearchBot (más nuevo, controlable de manera independiente del ClaudeBot) y GoogleOther entran en esta categoría.
Fetches iniciados por el usuario ocurren cuando una persona pega tu URL en ChatGPT o le pide a Claude que lea la página. Esos son ChatGPT-User, Perplexity-User y Claude-User. No respetan robots.txt (según la documentación revisada de OpenAI, porque son acciones de usuario, no crawl).
Yo los trataba a los tres como el mismo bicho. No lo son. Si tu objetivo es “ser citado en ChatGPT Search”, la visita de OAI-SearchBot importa y la de GPTBot es básicamente ruido. Si tu objetivo es “entrar en el dataset de entrenamiento del próximo Claude”, es exactamente al revés.
Quién respeta realmente robots.txt
Esta es la parte que me cambió la visión del robots.txt.
En kenimoto.dev tenía una regla Disallow: /api/. En 30 días:
GPTBot: 0 visitas a/api/. Cumple.Google-Extended: 0 visitas a/api/. Cumple.ClaudeBot: 0 visitas a/api/. Cumple.OAI-SearchBot: 3 visitas a/api/. Limítrofe. Puede ser caché anterior a la regla, puede ser que el texto revisado de cumplimiento esté haciendo algo sutil.PerplexityBot: 41 visitas a/api/en un burst de 90 segundos. No cumplió en esa corrida.
41 visitas no es muestra uno. El patrón de burst de 90 segundos coincide con un reporte público donde observaron a Perplexity ignorando bloqueos de User-agent: PerplexityBot mientras respondía una consulta activa de usuario. Tiene más sentido si piensas el PerplexityBot montado en la línea entre retrieval y fetch iniciado por usuario: se comporta como retrieval en los días tranquilos y como fetch de usuario cuando hay alguien esperando una respuesta del otro lado.
La lección que me anoté: robots.txt es una frontera autodeclarada. Tres de los cinco crawlers del top la respetaron limpio en mis datos. Uno fue dudoso. Uno hizo lo que quiso cuando había un humano del otro lado. Diseña pensando en eso.
Tres señales de LLMO que puedes extraer de aquí
La razón por la que escribo esto es que el dato de visitas de crawler es una señal de LLMO medible, y casi no la veo discutida al lado de las métricas de citación clásicas. Tres cosas que ahora miro cada semana:
1. Diversidad de crawler. Si solo el GPTBot te golpea y nada más, tu superficie de retrieval es solo OpenAI. Sos invisible en los caminos de retrieval de Claude, Perplexity y Gemini, aunque te estén citando en ChatGPT. Un score sano de diversidad es tener al menos tres de los cinco User-Agents del top visitándote de manera regular.
2. Razón retrieval-a-entrenamiento. Si sumas las visitas del lado retrieval (OAI-SearchBot + PerplexityBot + Claude-SearchBot + GoogleOther) y las divides por las visitas del lado entrenamiento (GPTBot + Google-Extended + anthropic-ai), sacas un número que te dice si el ecosistema de IA te ve como “contenido para aprender” o “contenido para citar ahora”. El mío está en 0,81. Por debajo de 0,5 quiere decir que tu contenido no está suficientemente fresco para ser tomado en retrieval en tiempo real. Por encima de 1,5 quiere decir que se te está usando en respuestas de forma activa (bueno) pero que probablemente estés en meseta como material de entrenamiento (vale la pena notarlo).
3. Tasa de fetch de llms.txt. De los cinco crawlers del top, solo PerplexityBot y ClaudeBot fueron a buscar /llms.txt en mis sitios durante la ventana de 30 días. GPTBot, OAI-SearchBot y Google-Extended no lo tocaron ni una vez. Esto coincide bastante con lo que reportan otros operadores y es un detalle que pesa cuando estás decidiendo si vale mantener llms.txt (respuesta corta: sí, pero sobre todo por los dos crawlers que lo leen). El texto de llmoframework.com que vuelvo a leer cubre las señales de retrieval más a fondo.
Cómo aplicarlo en tu sitio, paso a paso
Esta es la parte que yo quería haber leído antes y nunca encontré armada:
Paso 1. Cloudflare (plan Free). El dashboard de AI Crawl Control (antes AI Audit, docs aquí) ya te muestra los User-Agents de IA más frecuentes. Para log crudo necesitas Logpush, que es pago. En Free, lo más cerca que llegas es activar “AI Audit” y filtrar Analytics por User-Agents conocidos de IA. Free no te da el path por request pero te da los conteos y la tendencia.
Paso 2. Vercel. Proyecto → Logs → filtro User-Agent contains "Bot". En Pro, Vercel guarda 30 días de logs de edge. En Hobby es menos, y si vas en serio, mándalo a un log drain.
Paso 3. Netlify o Nginx propio. Solo grep en el log de acceso:
grep -E "GPTBot|ClaudeBot|PerplexityBot|OAI-SearchBot|Google-Extended" \
/var/log/nginx/access.log \
| awk '{print $14}' \
| sort | uniq -c | sort -rnEsto te da conteo por crawler. Cambia $14 por $7 para el ranking de URL. El número de campo depende del formato de log: corrobora con awk '{print NF}' sobre una línea para contar los campos.
Qué cambié después de mirar todo esto
Tres cambios concretos después de la ventana de 30 días:
- Partí mi
robots.txtpara permitirOAI-SearchBotyClaude-SearchBot(retrieval, bueno para citaciones) y mantuveDisallow: /api/estricto paraGPTBot(entrenamiento, sin upside para mí en esos endpoints). - Agregué header
Last-Modifieden toda ruta de blog, porque los crawlers de retrieval lo usan para decidir la frecuencia de re-fetch y Vercel no lo estaba mandando por defecto. - Empecé a anotar la razón retrieval-a-entrenamiento cada semana en una planilla. Dos semanas después, el único insight útil es que el número está estable, lo que al menos quiere decir que mi dieta de crawler no se está moviendo de una semana a otra.
Esperaba que los logs confirmaran lo que ya creía sobre LLMO. En general no lo hicieron. La citación es una señal entre varias, no la única que vale mirar. Quién está bajando tus páginas es una pregunta aparte, y la respuesta está en texto plano en un log que probablemente ya tienes.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?