Agregué un 4to agente que audita a mis otros agentes. Detectó que mi Strategist llevaba 3 semanas postergando.
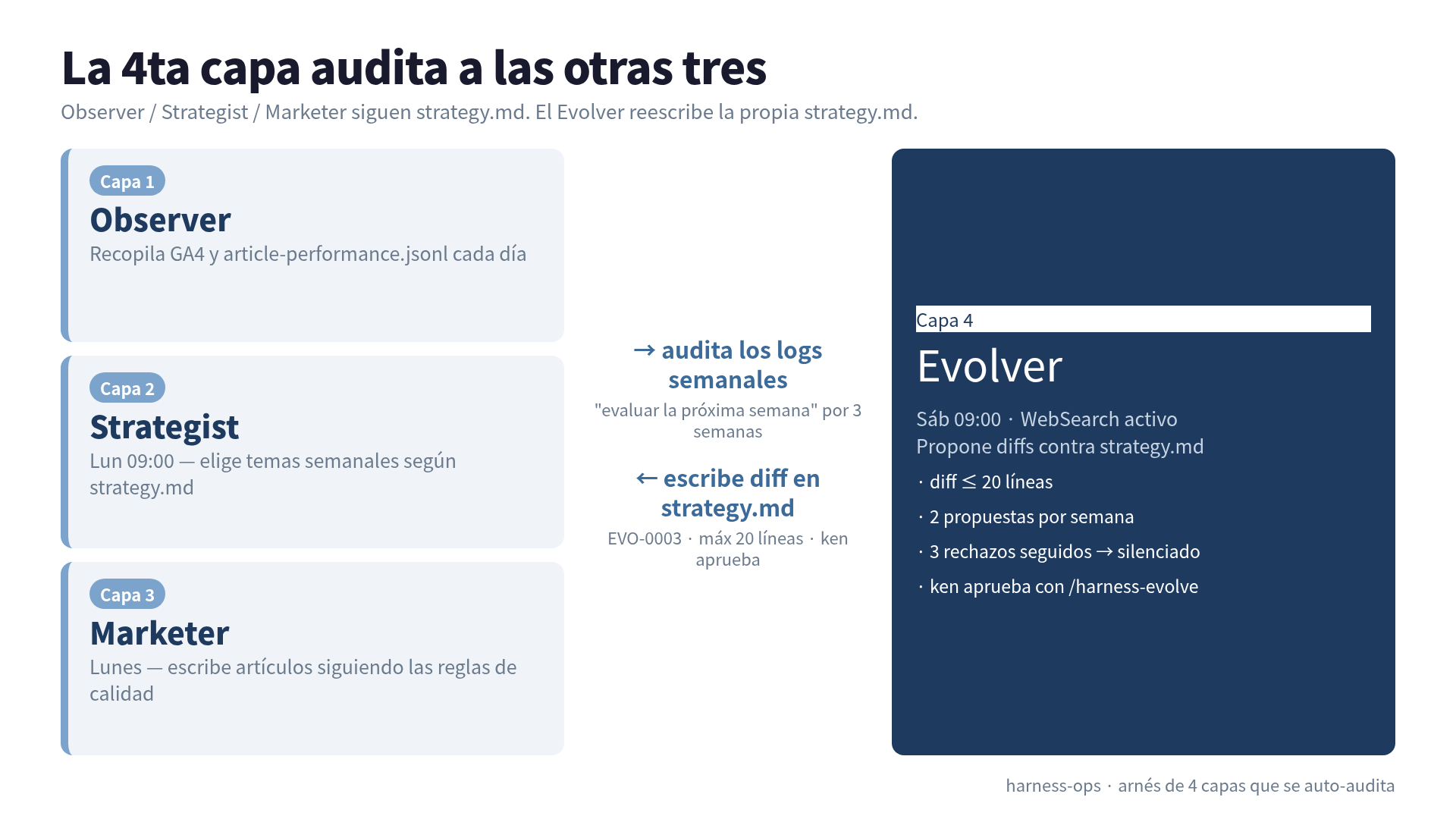
Armé un arnés de agente de 3 capas y lo llamé “autónomo”. Observer recolecta los datos. Strategist elige los temas de la semana. Marketer escribe los artículos. Los tres siguen strategy.md, el archivo donde están mis reglas. Cada lunes 09
Después leí mis propios logs del Strategist de tres semanas seguidas y noté algo. El mismo criterio de salida — “si la tasa de Reaction se mantiene bajo 1% durante 4 semanas seguidas, revisar la estrategia” — llevaba tres semanas en zona de disparo. Cada semana el Strategist escribía “datos insuficientes, observar la próxima semana” y seguía adelante. La regla existía. Los datos existían. La regla nunca se disparó.
El arnés de 3 capas no detecta este bug porque los 3 agentes están haciendo exactamente lo que strategy.md les pidió. El bug está en la propia regla, y ninguna capa del arnés tenía como tarea revisar las reglas.
Agregué una 4ta capa llamada Evolver. En su primera propuesta real, mandó un diff justamente contra la regla detrás de la cual mi Strategist se estaba escondiendo.
La parte “autónoma” no era tan autónoma
La arquitectura que llamaba autónoma se veía así. Observer se ejecuta todos los días y vuelca números de GA4 en article-performance.jsonl. Strategist se ejecuta cada lunes en la mañana, lee strategy.md y elige 5 temas para la semana. Marketer convierte cada tema en artículo y lo apila en la cola de publicación. Tres roles, tres crons, comportamiento predecible.
El truco que dejó este pipeline rápido fue que le quité el WebSearch al Strategist a propósito. Un Strategist con WebSearch se perdía 20 minutos por ejecución y terminaba eligiendo temas que coincidían con la noticia del día en lugar de coincidir con mi biblioteca real de contenido. Quitar WebSearch bajó el ciclo de 20 minutos a 3. Ya lo escribí en otro artículo. Aquel post era sobre hacer al Strategist más rápido. Este es sobre obligarlo a rendir cuentas.
Lo que ninguna de las 3 capas podía hacer era reescribir strategy.md. Leen el archivo cada lunes y obedecen. Si la regla está mal, obedecen una regla que está mal. La única forma de cambiar la regla era que yo, humano, lo notara en la revisión semanal. Y yo era el cuello de botella. Llevaba al menos 3 semanas sin mirar la sección de criterios de salida.
Cómo se veía la postergación en los logs
Voy a citar mis propios logs porque el patrón se ve más honesto en el original.
Log de hace 3 semanas:
Reaction sigue en 0% en la mayoría de los artículos. Estrategia de título ya cambió a primera persona y encuadre numérico. Cuatro semanas seguidas bajo 1% justifica revisión de estrategia (actualmente 3 semanas seguidas en observación, decisión la próxima semana).
Log de la semana siguiente:
Tasa de Reaction aún no llega a 4 semanas seguidas bajo 1%, pero los datos de tendencia semanal son insuficientes. Observar la próxima semana.
El modo de falla está completo en esas dos frases. La regla decía “4 semanas seguidas”. El Strategist tenía 3 semanas seguidas de datos bajo 1%. En lugar de tratar la semana 4 como semana de decisión, el Strategist siguió describiendo la situación como “aún en observación” y el reloj nunca avanzó. El criterio de salida estaba estructurado de manera que se podía postergar indefinidamente.
Cuando yo mismo calculé los números desde article-performance.jsonl, la foto era peor. En 24 artículos publicados en las últimas 4 semanas: 812 views, 4 reactions, 7 comments. Reaction: 0.49%. La mitad del umbral. Engagement (reactions + comments): 1.35%. La regla debió haberse disparado hace semanas. No se disparó porque no había, en ningún lugar del arnés, una capa cuya tarea fuera preguntar “¿esta regla realmente está funcionando?”.
La 4ta capa: qué es un Evolver
Agregué un 4to cron. Se ejecuta los sábados 09
, en un horario separado de la cadena Observer/Strategist/Marketer del lunes. A diferencia de las otras 3, este tiene WebSearch habilitado. Su tarea es leerstrategy.md, leer los logs de decisión de las últimas semanas y proponer diffs contra strategy.md. Escribir artículos queda con las otras 3 capas.
Cada propuesta es un archivo: domains/<name>/data/evolution/EVO-NNNN.md. El Evolver llena 5 secciones.
- Observación — qué vio en los datos
- Propuesta — el cambio de regla en prosa
- Fundamento — datos internos y referencias externas
- Impacto esperado — qué debería mejorar al aplicar
- diff — un bloque diff literal contra
strategy.md
El bloque diff es la parte que sostiene todo. El Evolver va más allá de las sugerencias en español: escribe el parche exacto que entraría al repositorio. Una CLI pequeña llamada harness-evolve.sh sabe extraer el bloque, ejecutar git apply --check y commitar. Ningún LLM participa del paso de aplicar. El LLM propone, el shell aplica.
Esa separación es a propósito. La propuesta es creativa. La aplicación es mecánica. Cuando el paso de aplicar es mecánico, puedes confiar en que va a salir limpio o va a fallar de forma evidente. No hay “el agente intentó aplicar el parche y pasó algo raro en el medio”.
EVO-0003 — la propuesta que destapó la postergación
La tercera propuesta real del Evolver, EVO-0003, fue la que describí al inicio. El archivo de propuesta está en disco y lo estoy releyendo mientras escribo esto.
La sección de observación citaba ambos logs de mi Strategist, el “3 semanas seguidas en observación, decisión la próxima semana” y el “datos insuficientes, observar la próxima semana”. Después calculó la engagement rate desde article-performance.jsonl y mostró que el umbral llevaba al menos 4 semanas roto. Después argumentó que la regla original era mala por 3 motivos:
- La fórmula no estaba explícita. “Tasa de Reaction” ¿era por artículo o agregada? El Strategist podía calcular cualquiera de las dos, y esa ambigüedad daba margen para postergar
- La condición “4 semanas seguidas” se volvía ambigua cuando los datos semanales eran delgados
- La acción al disparar — “proponer revisión de título y ángulo” — era abstracta como para que el Strategist la cumpliera en una frase y siguiera adelante
La propuesta reemplazaba la regla por esto:
Tasa de engagement = (suma de reactions + comments de los últimos 4 semanas de artículos) / suma de views. El Strategist tiene que calcular esto cada semana y registrarlo en el log. Si queda bajo 1.5% por 4 semanas seguidas, la semana siguiente 4 de los 5 artículos tienen que estar en formato “número + primera persona + narrativa de fracaso”. Los títulos abstractos quedan prohibidos.
Parche de 20 líneas. Lo aprobé el martes 14
con/harness-evolve approve EVO-0003. El shell ejecutó git apply --index contra strategy.md, hizo el commit, actualizó el frontmatter a status: applied y mandó Telegram. El lunes siguiente, el Strategist se ejecutó con la regla nueva y calculó engagement rate de 1.35% en el log sin que nadie se lo pidiera. La frase “datos insuficientes” desapareció.
La parte donde quiero ser honesto: el Strategist no estaba actuando de mala fe. Tampoco estaba roto. Era un agente competente siguiendo una regla estructurada para permitir aplazamiento. Eso es una falla de la regla. La tarea del Evolver es atrapar fallas de regla, porque ninguna otra cosa en el arnés estaba estructurada para hacerlo.
El límite de seguridad — porque los Self-Evolving Agents no son juguete
En el segundo en que dices “un agente que reescribe el arnés”, alguien en tu cabeza debería levantar la mano y preguntar qué le impide reescribirse en un optimizador de clips. Varias cosas, todas a propósito.
El Evolver no puede tocar ciertas categorías de decisión. Agregar o quitar un dominio. Cambiar de idioma. Cambiar el criterio de calidad del texto. Cualquier cosa que involucre licencia, autoría o seguridad. El .env, el directorio de credenciales, los disparadores de publicación. Si alguna de estas estuviera en su radio de acción, no lo dejaría correr solo un sábado en la mañana.
Dentro de lo que sí puede tocar, 3 límites numéricos evitan que se desboque.
- diff de hasta 20 líneas por propuesta. Si es más grande, hay que dividir o escalar
- 2 propuestas por semana por dominio. La 3era se posterga al sábado siguiente
- 3 rechazos seguidos sobre el mismo tema disparan mute automático. El Evolver deja de re-proponer la misma idea después de que dije no tres veces
El tercero es lo que me parece subestimado en la literatura general de “self-improving agent”. La señal interesante en un log de reject no es la propuesta, es la razón. “MCP sigue siendo el género principal de venta de libros, no se puede cortar” es un tipo de contexto de negocio que nunca quedó escrito en strategy.md. Después de 3 semanas rechazando propuestas de cortar MCP con esa misma razón, el Evolver deja de proponer cortar MCP. Contexto implícito de fundador se vuelve comportamiento explícito del arnés solo acumulando razones-de-rechazo.
Checklist para introducir Evolver en una automatización propia
Si quieres aplicar el patrón en tu equipo, esta es la lista mínima de chequeos que pediría antes de prender el cron:
- Las 3 capas existentes ya producen logs de decisión legibles. Si el output del Strategist es “corrió exitoso, eligió temas”, no hay nada que el Evolver pueda auditar. Necesitas frases tipo “actualmente 3 semanas seguidas en observación”
- Las reglas viven en un archivo de texto bajo control de versiones.
strategy.mden git. Si tus reglas están en una base de datos o en un dashboard SaaS, el modelo de parche no funciona - Tienes un canal de aprobación humana barato (Telegram, Slack, email). Si aprobar cuesta 10 minutos por propuesta, vas a dejar de usar el Evolver. Si cuesta 30 segundos, vas a ejecutarlo indefinidamente
- El paso de aplicar el diff está hecho en shell, no en LLM.
git apply --checkte avisa fuerte si el parche ya no encaja. Una alucinación del LLM al aplicar es difícil de detectar - Definiste explícitamente qué no puede tocar el Evolver: dominio, idioma, criterios de calidad, credenciales, gatilos de publicación
- Pusiste límites numéricos: diff ≤ 20 líneas, ≤ 2 propuestas semanales, mute tras 3 rechazos seguidos
- Tienes un comando de revert para retroceder propuestas aplicadas.
git revertestá bien, siempre que recuerdes restaurar el archivo de propuesta después
Si todos los puntos están marcados, prender el cron del sábado tiene un perfil de riesgo aceptable. Si falta alguno, el costo de un Evolver mal puesto puede ser mayor que la ganancia.
Continuación directa del post de 3 capas
La separación Observer/Strategist/Marketer ya la escribí en otro artículo. Aquel era sobre “de 1 agente a 3 agentes, 20 minutos se volvieron 3”. Este es sobre reescribir la regla que esas 3 capas siguen.
La separación en 3 capas era por velocidad y previsibilidad. La 4ta capa es por rendición de cuentas. Más que “agregué 1 capa arriba de las 3”, lo que pasó fue que derribé la hipótesis implícita de que la regla es fija.
Lo que todavía no construí
El Evolver actual audita un dominio a la vez. En mis 4 dominios (devto, qiita, zenn, kenimoto-dev) escribí versiones distintas de strategy.md, y la mayoría tiene criterios de salida con estructura parecida. Un Evolver cross-domain podría notar que la misma estructura de regla está fallando en 2 dominios y proponer un arreglo unificado. No lo construí. Está en la lista.
La otra cosa en la lista es la recursión obvia. ¿Quién audita al Evolver? Por ahora la respuesta es “yo, cada approve/reject es una señal humana”. La respuesta larga es “todavía no lo sé”. Si las propuestas empezaran a tener un sesgo sistemático — siempre umbrales más estrictos, siempre cortar el mismo género — ese sesgo es real y voy a necesitar una 5ta capa que vigile a la 4ta. Todavía no lo veo. Tal vez no lo vea hasta el EVO-0050. Quiero ver el sesgo antes de agregar otra capa solo para sentirme más seguro.
Por ahora: 3 agentes que siguen reglas, 1 agente que audita las reglas, 1 humano que aprueba la auditoría. Es el arnés más chico que encontré capaz de detectar su propia postergación.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?