Dividí mi agente en 3 roles y elegir 5 temas pasó de 20 a 3 minutos
Yo creía que un solo agente haciendo todo era elegante. Una llamada claude -p, “elige los temas de hoy y escribe el principal”, listo. Elegir 5 temas tomaba 20 minutos.
Lo dividí en tres agentes y el mismo trabajo pasó a tomar 3 minutos. El costo en tokens bajó alrededor del 60%. Cada agente, por separado, sabe hacer menos. El pipeline entero quedó más rápido.
El truco no es “más agentes”. El truco es sacarle WebSearch al agente que decide.
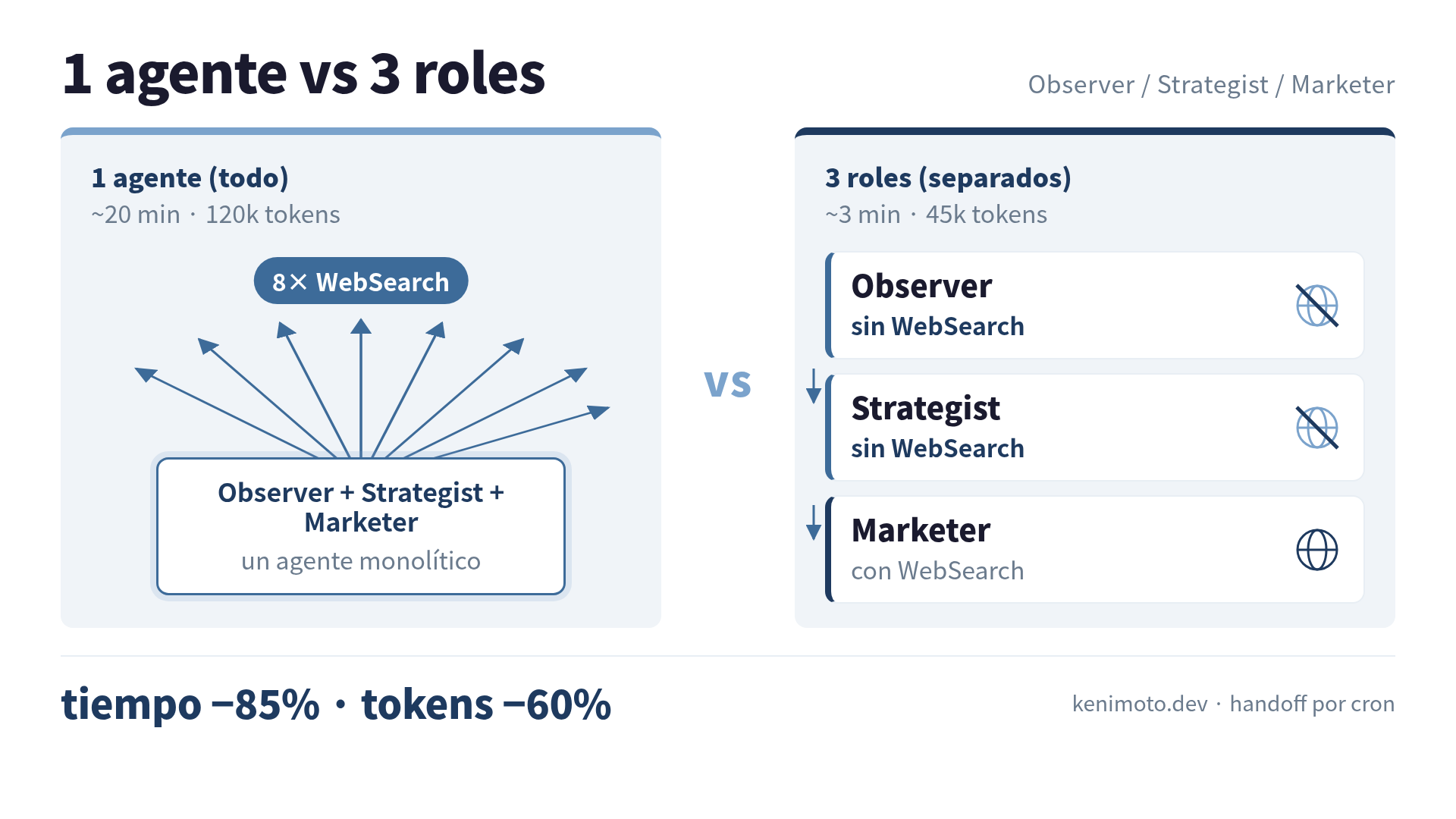
El setup de 1 agente que tomaba 20 minutos
La configuración original era un prompt, un agente, una ejecución:
“Revisa los datos de GA4 de ayer, elige 5 temas para hoy y escribe el de mayor prioridad.”
El agente tenía habilitado Bash, Read, Write, Edit, Grep, Glob, WebSearch, WebFetch. Todo lo que pudiera llegar a necesitar.
Por cada tema candidato hacía más o menos lo mismo: WebSearch para “ver qué es tendencia ahora en este nicho”, WebSearch otra vez para confirmar la tendencia, WebSearch una tercera vez para cruzar con la competencia. Cinco temas, tres o cuatro búsquedas cada uno, 15 a 20 búsquedas por ejecución. Cada búsqueda volcaba algunos miles de tokens de resultado en el contexto.
Cuando el agente estaba eligiendo el tercer tema, el contexto de decisión ya tenía más de 40 mil tokens de resultados de búsqueda de los temas 1 y 2. La relación señal-ruido colapsaba. El agente empezaba a elegir temas que “sonaban confirmados por noticias recientes” en vez de temas que coincidían con el material que yo tenía en stock.
El síntoma visible era el tiempo: cerca de 20 minutos por ejecución. El síntoma oculto era la deriva. En la revisión semanal yo sobrescribía las elecciones del agente con frecuencia, porque no coincidían con el contenido que tenía listo.
Por qué WebSearch en el loop de decisión es una trampa
WebSearch está bien. WebSearch dentro del loop de decisión es la trampa.
Pasan dos cosas cuando dejas que el juez busque:
Tiempo: una búsqueda son 5 a 20 segundos. Cinco temas por cuatro búsquedas son 100 segundos esperando, antes de contar lectura y razonamiento. Para una persona haciendo una sola pregunta es nada. Para un job automatizado que se ejecuta todos los días, se suma rápido.
Contaminación de contexto: cada resultado mete 2 mil a 5 mil tokens de texto raspado de HTML en el contexto de decisión. Nada de eso fue estructurado para responder “¿este tema sirve para mi contenido?”. Fue estructurado para SEO. El juez termina razonando sobre una pila de copy de marketing, en vez de razonar sobre sus propios datos.
El arreglo es poco glamoroso. El juez no debe tener WebSearch. WebSearch pertenece al que escribe.
Rol 1: Observer — solo recolecta
El trabajo del Observer es “traer los números de ayer y escribirlos en un archivo”. Eso es todo.
Entradas: GA4, API de Zenn, API de Dev.to, logs de ayer. Salida: domains/<nombre>/data/snapshot-YYYY-MM-DD.json.
Herramientas permitidas:
claude -p "$(cat scripts/prompts/observer-prompt.txt)" \
--allowed-tools "Bash,Read,Write"Sin WebSearch, sin WebFetch, sin Edit. El Observer llama a tres APIs con curl y escribe un único archivo JSON. Si trata de pasarse de listo e “interpretar los datos”, el prompt le dice que no. El schema también lo sujeta: los campos son total_views, top_performers_3, errors_yesterday. No existe un campo recommendation, así que no hay dónde meter un juicio aunque quisiera.
Suena a una rebaja. Lo es, en el mismo sentido en que una función de un solo propósito es “rebaja” frente a un god object. Cuando el Observer falla, sé exactamente cuál API se rompió, porque eso es lo único que hace.
Rol 2: Strategist — solo decide, sin WebSearch
El Strategist lee lo que escribió el Observer, lee strategy.md para las reglas, lee los últimos 30 días de temas publicados como lista de exclusión y elige 5 temas. Nada más.
claude -p "$(cat scripts/prompts/strategist-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob"Fíjate qué falta: WebSearch, WebFetch. Sacados físicamente del allow-list. El Strategist literalmente no puede alcanzar internet.
Esta fue la parte que más me costó aceptar. “¿Cómo decide los temas de hoy sin ver qué es tendencia?” La pregunta estaba mal. La buena es: ¿estoy escribiendo temas que están reventando en otros lados o temas que coinciden con mi stock de contenido?
El Strategist ve:
- Tres meses de mis propios datos de performance (qué se leyó)
- Mi stock de contenido (capítulos de libro, borradores no publicados)
- Lista de exclusión de 30 días (qué ya escribí)
- Mi propio
strategy.md
Con eso alcanza para elegir 5 temas en unos 90 segundos, no 20 minutos. El consumo de tokens por ejecución del Strategist bajó de unos 80 mil a unos 20 mil, porque ya no hay resultados de WebSearch que leer.
“Sumar evidencia con WebSearch” sonaba a buena idea. En la práctica sumó 8 búsquedas redundantes y 40 mil tokens de ruido.
Rol 3: Marketer — ejecuta, con WebSearch habilitado
El Marketer lee la salida del Strategist, toma el tema de mayor prioridad y escribe el artículo. Aquí es donde aparece WebSearch:
claude -p "$(cat scripts/prompts/marketer-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob,WebSearch,WebFetch"El Marketer usa WebSearch para investigación de ejecución:
- “Versión estable de LangGraph en 2026”
- “URL oficial de Building Effective Agents de Anthropic”
- “Plan de precios de Inngest para workflows con cron”
Esto es citación y chequeo de versiones, no decisión. “¿Conviene escribir este tema?” ya está resuelto. El WebSearch del Marketer está acotado al artículo que tiene enfrente.
De ahí caen dos consecuencias:
- El costo se localiza. El gasto de WebSearch vive dentro del Marketer, donde produce salida visible. El costo por ejecución del Strategist quedó tan bajo que lo ejecuto varias veces por semana sin pensarlo.
- La falla se localiza. Cuando WebSearch está inestable o caído, solo se rompe el que escribe. El Strategist sigue entregando los temas del día. El Observer sigue registrando los números de ayer. El flujo degrada, no se detiene.
La cadena cron: cómo se conectan los tres roles
Los tres agentes no comparten conversación. Comparten archivos.
07:00 Observer → escribe snapshot-2026-05-14.json
09:00 Strategist → lee snapshot, escribe strategist-2026-05-14.md
10:00 Marketer → lee strategist.md, escribe borradores + agenda publicación 22:00
22:00 Observer → registra tracción inicial del día → entrada de mañanaEsto lo ejecuto como cron simple en un VPS pequeño. La versión corta es una línea por job con set -euo pipefail, trap ... ERR, un ping de falla a Telegram y un lock file. Unas 30 líneas de shell por rol.
Si prefieres durabilidad administrada en vez de cron, Temporal Schedules, el trigger cron de Inngest y GitHub Actions cron entran todos en la misma forma. La arquitectura no se preocupa por cuál de los tres la lleva. Yo uso cron porque el modo de falla es “el servidor está apagado”, y eso lo noto rápido.
El handoff siempre es un archivo en disco. JSON para el snapshot, Markdown para el log del strategist, Markdown para el log del marketer. Legible por humano, con fecha, replayable. Puedo volver a ejecutar el Marketer de ayer contra el archivo del Strategist de ayer cambiando una variable de entorno. Backfill gratis, sin heredar Airflow.
Sub-agent vs separación en roles — no confundir
Tengo otro post sobre ejecutar tres sub-agentes de Claude Code en el mismo PR y verlos discordar en 41% de los comentarios. A veces me preguntan si es lo mismo que estoy describiendo aquí.
No lo es. Se parecen en una diapositiva y se comportan distinto en la práctica.
| Sub-agent (Task tool de Claude Code) | Separación en roles (cron) | |
|---|---|---|
| Alcance | Misma sesión, mismo agente padre | Tres procesos, tres ejecuciones |
| Estado | El padre pasa el contexto como entrada | Archivo en disco |
| Tiempo | Sincrónico, el padre espera | Asincrónico, con horas de diferencia |
| Falla | El padre maneja el retry | Cada job reintenta por su cuenta |
| Caso de uso | ”Explorá este repo en paralelo" | "Corré el PDCA de ayer cada mañana” |
Sub-agent sirve para paralelismo dentro de una tarea. Separación en roles sirve para pipelines desplazados en el tiempo. Mezclarlos te da lo peor de los dos: la superficie de debug del cron, más la deriva de contexto compartido de los sub-agents.
La regla que uso: si la respuesta tiene que volver en la misma conversación, es sub-agent. Si la respuesta tiene que sobrevivir a un reinicio del servidor, es un job de cron separado.
Guía práctica: matriz de roles y allow-list
Antes de armarlo en tu propio loop, esta es la matriz que conviene tener clara desde el principio:
| Rol | Lee | Escribe | WebSearch | Hora de ejecución |
|---|---|---|---|---|
| Observer (AM) | APIs, logs de ayer | snapshot-YYYY-MM-DD.json | No | 07 |
| Strategist | snapshot, strategy.md, lista de exclusión | strategist-YYYY-MM-DD.md | No | 09 |
| Marketer | strategist.md, stock | Borradores + log marketer | Sí | 10 |
| Observer (PM) | Métricas del día | Snapshot vespertino | No | 22 |
Los dos elementos no negociables son: (1) Strategist sin WebSearch en el allow-list, (2) el handoff entre roles siempre es un archivo con fecha. Si rompes uno de los dos, pierdes la mayor parte de la ganancia.
En la región
Aquí en la región, los agentes IA ya están en producción. Mercado Pago lanzó un Asistente Personal con IA en Argentina con más de 100 funcionalidades disponibles. Rappi implementó Amazon Connect con herramientas de IA como parte de su plan de automatización regional. Nubank procesa millones de transacciones en tiempo real con IA. Ninguno de esos equipos pone un único agente a hacer observación, decisión y ejecución en un mismo loop. En escala, separar los roles es lo que vuelve al pipeline confiable.
Números medidos
Estos son mis números corriendo ambos setups sobre el mismo stack de contenido.
| Métrica | 1 agente | 3 roles | Cambio |
|---|---|---|---|
| Tiempo para elegir 5 temas | ~20 min | ~3 min | -85% |
| Tokens por ejecución diaria | ~120k | ~45k | -62% |
| Gasto mensual de API | ~USD 60 | ~USD 22 | -63% |
| Re-elección de tema (revisión semanal) | 2-3/sem | 0-1/sem | baja |
| Caída de WebSearch detiene el flujo | sí | no | resuelto |
| Tiempo medio para debuggear falla | 30-60 min | 5-10 min | -80% |
La cuenta de tokens fue la que me sorprendió. Yo asumía que dividir en tres agentes iba a aumentar el consumo total por contexto duplicado. No aumentó. El tráfico de WebSearch que desapareció era más grande que el overhead nuevo por rol.
El tiempo de debug es el que pesa día a día. Con un solo agente, “el job falló a las 09
” no me dice nada. Con tres roles, “el Strategist falló a las 09” me dice qué script de 30 líneas abrir.“Sumar agentes lo hizo más rápido” suena raro a primera vista. Solo es más rápido porque saqué WebSearch del loop de decisión. La división fue lo que permitió quitarlo de verdad: en el momento en que el Observer y el Strategist ya no podían alcanzar internet, la tentación de “una búsqueda más” desapareció.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?