Dejé de agregar contexto a mi agente: podar las salidas de herramientas recuperó la precisión
Durante mucho tiempo creí que el contexto siempre suma. Engordaba el archivo CLAUDE.md, le hacía leer todos los archivos que parecían relacionados, y dejaba las salidas de las herramientas tal cual. Pensaba que mientras más información tuviera el agente, mejor trabajaría.
Esa idea se cayó a la mitad de una tarea de migración de tres horas. El agente olvidó, sobre el final, la decisión de diseño que él mismo había tomado al principio. Tocó el archivo equivocado dos veces y metió mano en un directorio que yo le había marcado como prohibido en la primera hora. El problema no era el prompt. El contexto estaba tan inflado que la instrucción importante quedó enterrada.
Así que hice lo contrario. Dejé de agregar y empecé a podar. El resultado: los tokens bajaron cerca de un 40% y la precisión en la tarea larga se recuperó. De eso trata esta nota.
Dónde “más es mejor” deja de ser cierto
El contexto tiene un techo de utilidad.
Claude Sonnet anuncia una ventana de 200 mil tokens. Pero Geoffrey Huntley, de Sourcegraph, reportó que la calidad cae alrededor de los 147 mil a 152 mil tokens. La capacidad de la ventana y la capacidad que de verdad puedes usar son dos cosas distintas.
Esa degradación tiene nombre: “context rot”. A medida que sube la cantidad de tokens, la precisión y la capacidad de recuperar información bajan en silencio. Las sesiones que pasan de 30 minutos, que tocan 20 archivos o más, o que exigen razonar a lo largo de varias fases, entran en un modo de falla distinto. Eso fue exactamente lo que me pasó.
Sirve la comparación con alguien nuevo en el equipo. Le entregas tres páginas y arranca enseguida. Le apilas 300 páginas en el escritorio a esa misma persona y se le va el día buscando dónde dice qué. En algún punto, la cantidad de información y la capacidad de ejecutar se vuelven inversamente proporcionales.
Las 3 categorías que podé
¿Qué borrar? Lo que recorté se dividió en tres grupos.
1. Los datos crudos de las herramientas
Este fue el de mayor impacto. El log completo de npm test, los cientos de líneas de un grep, el JSON gigante de una respuesta de API. El agente acumula todo eso en el contexto. Pero lo único que de verdad hace falta es la conclusión: “fallaron 3 pruebas, los archivos son estos”.
La misma Anthropic ya ofrece la limpieza de resultados de herramientas y la compactación como medidas oficiales. El context editing borra la salida de la herramienta y la compactación resume las conversaciones largas. Lo que yo hacía a mano resultó tener nombre y función propios.
En mi flujo dejé de conservar la salida cruda: anoto los puntos clave aparte y saco el log de la ventana. Solo con eso desapareció la mayor parte de los tokens.
2. Los archivos irrelevantes
Los que abría “por las dudas”. Era una migración y le hacía leer cinco componentes que no tenían nada que ver. Lo que creía un seguro era, en realidad, comprar ruido.
3. Las idas y vueltas viejas de la conversación
El tanteo del inicio. Cuando ya quedó decidido “vamos por este camino”, las tres alternativas descartadas que llevaron ahí ya no sirven. Dejas la decisión y tiras el proceso. Si le pasas una instrucción propia a /compact, recortas solo el ruido y conservas las decisiones importantes.
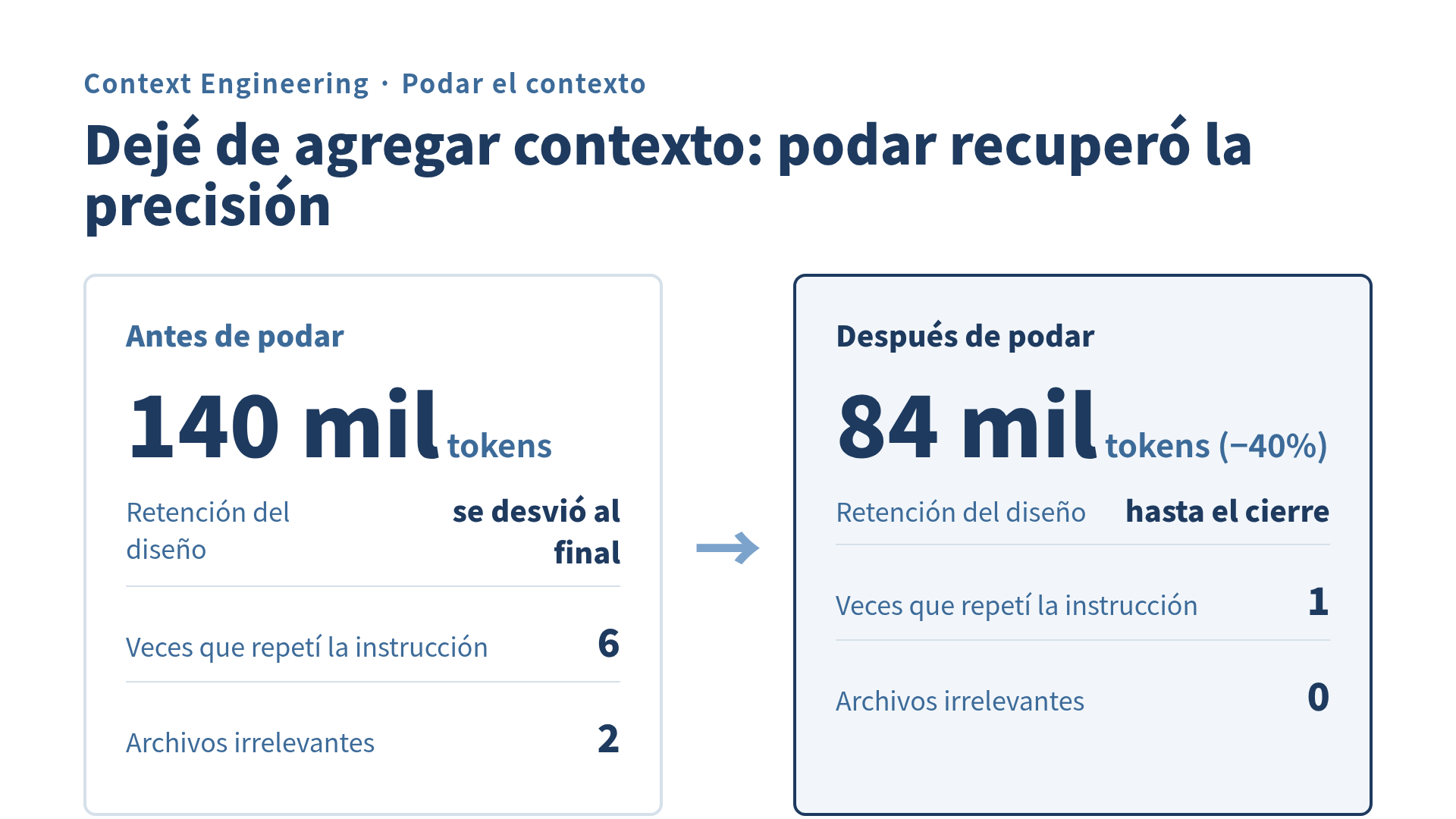
Los números, antes y después de podar
Comparé la misma tarea de migración antes y después de la poda.
| Métrica | Antes de podar | Después de podar |
|---|---|---|
| Tokens usados | ~140 mil | ~84 mil |
| Retención del diseño | se desvió al final | se mantuvo hasta el cierre |
| Veces que tuve que repetir la instrucción | 6 | 1 |
| Archivos irrelevantes tocados | 2 | 0 |
Los tokens bajaron cerca de un 40%. Pero lo que de verdad funcionó fue que el agente recordó la instrucción inicial hasta el final. Las repeticiones pasaron de 6 a 1, porque dejé de pisar el valle de degradación de los 140 mil tokens.
Quiero subrayar algo: no agregué ninguna técnica nueva. Al revés, quité. Es la dirección opuesta a sumar capas de RAG. No le añadí inteligencia; le saqué el estorbo, y la inteligencia que ya tenía volvió. Eso fue todo.
Por qué “no incluir” cuesta más que “agregar”
Con honestidad: podar cuesta más que sumar.
Sumar es fácil. Abres el archivo que te da inseguridad y listo. No exige criterio. Podar, en cambio, te pide decidir “esto no hace falta”. Y ahí peleas con el miedo de que lo que borraste fuera necesario.
Mi criterio es simple. “¿Esta información sirve, de forma directa, para avanzar el paso que estoy haciendo ahora?”. Si no sirve, no entra. Si después hace falta, voy a buscarla en ese momento. El agente puede volver a leer un archivo cuando lo necesite. Apilarlo todo por adelantado servía para calmar mi inseguridad; al agente no le aportaba nada.
Los modelos nuevos de Anthropic ya traen “context awareness”: saben cuánta ventana les queda y sostienen la tarea hasta el final sin quedarse sin aire. Pero esa función parte de tener margen en la ventana. Si la llenas desde el arranque con logs crudos, ese margen no existe desde el primer minuto.
En resumen
Cuando la precisión se cae en una tarea larga, mi primera reacción fue “debe faltar información”. Era al revés. Sobraba información y diluía la instrucción que importaba.
Hice tres cosas. Cambié los datos crudos de las herramientas por sus puntos clave. Dejé de abrir archivos irrelevantes. Tiré el tanteo posterior a cada decisión. Con eso los tokens bajaron un 40%, dejé de pisar el valle del context rot y el agente sostuvo el rumbo hasta el cierre.
La ingeniería de contexto suena a un asunto de qué agregar y cómo. Pero en las tareas largas lo que rinde es el criterio de qué no incluir. Dejas de apilar papeles en el escritorio y conservas solo tres. Ahí es cuando la persona nueva vuelve a ser útil.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?