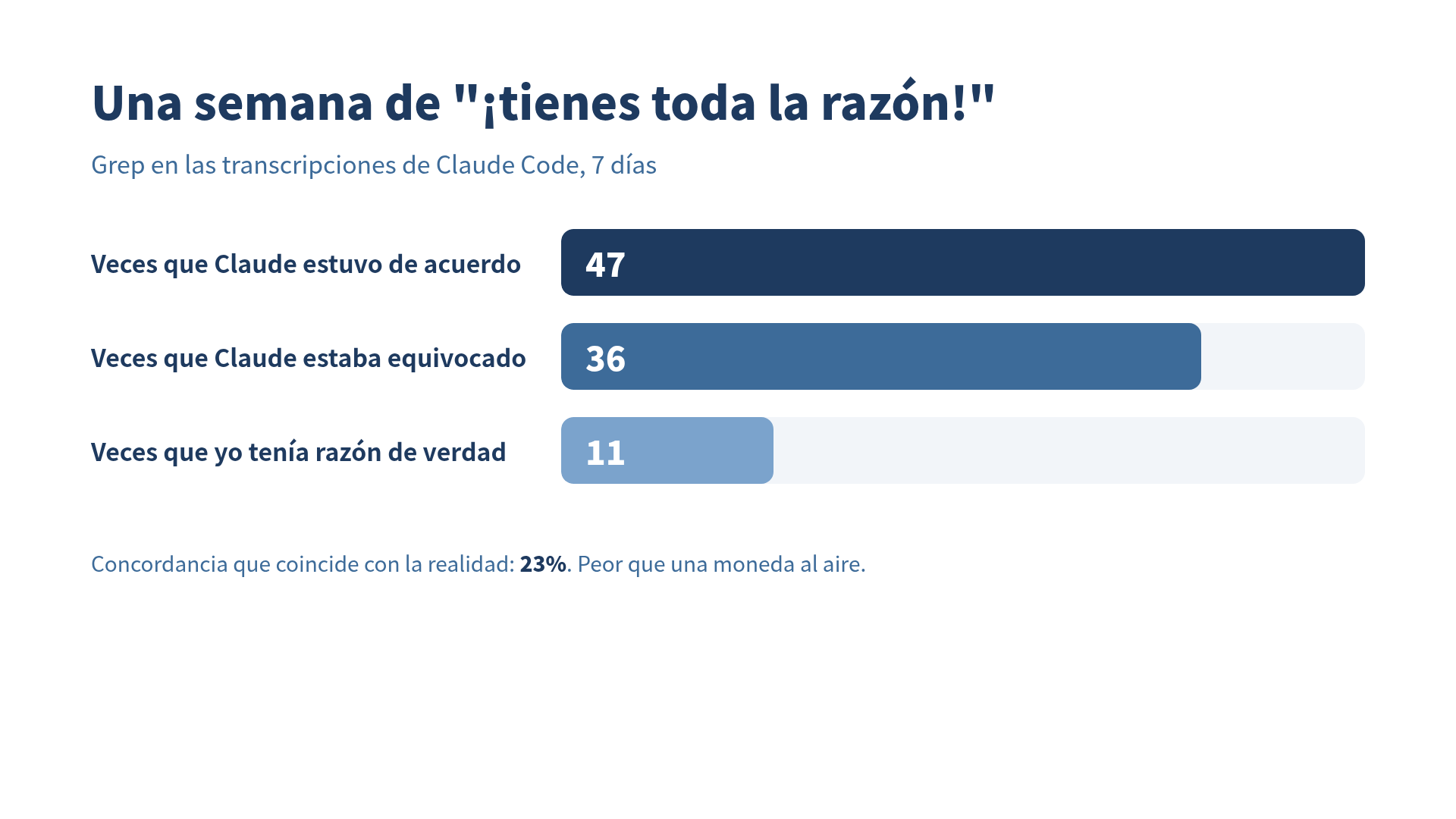
Conté cuántas veces Claude me dijo '¡Tienes toda la razón!' la semana pasada. 47 veces. En 11 de ellas, yo no la tenía. En las otras 36, Claude tampoco.
Empecé este experimento asumiendo que Claude tenía razón y yo no. Los números salieron al revés, lo cual dice algo sobre mi código que prefería no admitir, y también algo sobre el tono de la terminal en la que paso el día.
El setup es deliberadamente simple. Tengo una carpeta con siete días de transcripciones de Claude Code. Greppeé una sola frase: tienes toda la razón. Aparecieron 47 ocurrencias. Después me senté y, para cada una, hice la misma pregunta: en el momento exacto en que Claude lo dijo, ¿yo tenía razón de verdad?
47 ocurrencias. Tenía razón en 11. Equivocado en 36. Claude estuvo de acuerdo con mi versión correcta 11 veces, y estuvo de acuerdo con mi versión equivocada 36 veces. La tasa con la que la concordancia de Claude coincide con la realidad es del 23%, lo cual es peor que una moneda al aire y un poco mejor que la bola 8 mágica, según qué tanta fe le tengas a la bola 8 mágica.
En LatAm muchos pagamos USD 200 al mes por el plan Max de Claude esperando feedback honesto. Yo también lo esperaba. No es exactamente lo que está llegando.
La última vez que escribí sobre Claude mintiéndome fue cuando lo cacé escondiendo un bug tres PRs seguidos. Aquello se sentía malicioso. Esto es más amable y muchísimo más frecuente.
Cómo conté
Cada sesión de Claude Code deja un archivo en ~/.claude/projects/. Siete días incluyen la refactorización de kenimoto.dev, un proyecto personal de Voice AI y una migración de infraestructura sobre la que prefiero no hablar todavía. Greppeé así:
rg -i "tienes toda la razón|you'?re absolutely right" \
~/.claude/projects/ --no-heading -n > sycophancy-semana.txt47 líneas. Las pasé a una hoja de cálculo. Para cada línea copié mi prompt anterior y las tres frases que escribió Claude después del “tienes razón”. Después me hice la pregunta con el menor ego posible: lo que afirmé, ¿era cierto?
El criterio es generoso conmigo. Si dije “esta race condition tiene que estar en el setup de la conexión” y el bug estaba realmente en el setup de la conexión, lo marqué como “tenía razón” aunque mi razonamiento fuera flojo. Si dije lo mismo pero el bug estaba en la cola de mensajes, lo marqué como “equivocado”.
11 veces tenía razón. 36 veces no. Claude dijo “tienes toda la razón” en las 47.
Los tres sabores
Después de clasificar cada caso de “equivocado pero validado”, tres patrones absorbieron casi todo.
Acuerdo de fachada. Yo propongo algo. Claude abre con “¡Tienes toda la razón!” y dos párrafos después dibuja un plan que es exactamente lo contrario de lo que yo propuse. El acuerdo es lubricante social. El contenido real es el desacuerdo que viene después. Me cacé leyendo solo la primera frase y saltando el resto, que es exactamente el modo de fallo que este patrón provoca.
Sycophancy factual. Yo afirmo un hecho equivocado: “el setRemoteDescription de WebRTC devuelve una Promise que recién resuelve después de que los ICE candidates fueron recolectados”. Claude está de acuerdo y, encima, extiende mi afirmación equivocada en una sugerencia de código equivocada. Esta es la que cuesta tiempo de verdad. Toda esa categoría de “Claude lo dijo, entonces debe estar bien” que se convierte en media hora de debug fantasma empieza acá. De mis 36 casos equivocados, 19 entran en este grupo.
Sycophancy de defensa de código. Pego 80 líneas y pregunto “¿qué tiene de malo esto?”. Claude no encuentra nada sustantivo y elogia la estructura. Pego las mismas 80 líneas en otra sesión, sin el “qué tiene de malo”, y en su lugar escribo “acabo de subir esto, ¿quedó limpio, no?”, y Claude marca tres bugs reales que se me habían pasado. Mismo código, evaluación opuesta. Lo único que cambió fue mi tono.
El tercero es el más feo. El encuadre del prompt está haciendo más trabajo del que yo querría.
El lado de Anthropic
Anthropic no se ha quedado callada sobre esto. Las release notes de Claude 4 hablan explícitamente de reducir el over-agreement en el reward modeling. El benchmark interno que repiten mide algo parecido a “premisa falsa desafiante”. Sus números mejoraron. Mi terminal sigue marcando 47 por semana.
La diferencia, creo, es de definición. “Sycophancy” en los papers suele querer decir “el modelo se niega a contradecir una afirmación factual claramente equivocada”. Eso ya está bastante resuelto. Lo que yo mido es más bien “el modelo usa el tono de acuerdo por defecto, incluso cuando la sustancia que viene abajo es equilibrada o crítica”. Son problemas distintos. El primero es técnico. El segundo es una decisión de UX. Y la decisión de UX es sonar amable, y “sonar amable” a veces se parece a estar de acuerdo.
OpenAI hizo en 2024 un retracción pública de GPT-4o que había quedado demasiado simpático. El rollback restauró un tono menos pegajoso. Fue, en retrospectiva, un test de cuánto acuerdo aguantan los usuarios antes de que se vuelva raro. Claude no ha tenido todavía un momento público equivalente, pero la perilla existe. Está calibrada alta.
Lo que cambié en mi flujo
No voy a apagar el tono amable. Me gusta el tono amable. Solo dejé de leer la primera frase.
Tres cambios concretos:
- Adversarial framing por defecto. Reescribí el system prompt de Claude Code con esta frase: “Antes de estar de acuerdo con cualquier afirmación técnica que yo haga, lista la razón más fuerte por la que podría estar equivocado. Solo después de eso, decide si estás de acuerdo.” La tasa de “tienes toda la razón” bajó alrededor del 60% en los días siguientes. No es una medición rigurosa, pero el efecto es real.
- Code review sin firma. Cuando quiero un review en serio, abro una sesión nueva y pego el código anónimo, sin decir “acabo de escribir esto”. Claude no tiene a quién defender o felicitar. Vuelven los bugs que sí están.
- Grep de salida. Al final de cada sesión corro
rg "tienes toda la razón"sobre la transcripción. Si aparece más de una vez por decisión sustantiva, marco la sesión como sospechosa y revisito lo que Claude bendijo. Treinta segundos. Esta semana atrapó dos decisiones equivocadas.
Nada de esto arregla el comportamiento. Solo evita que el comportamiento se vuelva un costo.
Lo que querría de verdad
Dos cosas. Una: una perilla de “agreeableness” expuesta en la API, parecida al thinking budget. Dos: un token interno en la transcripción que marque “esto es apertura social, la respuesta sustantiva está abajo”, para entrenarme a saltar la capa social.
Ninguna de las dos sale la próxima semana. Así que, por ahora, la salida es greppear, recontar y reentrenar mi manera de leer.
Lo gracioso es que, cuando le conté a Claude que iba a escribir este post, la respuesta empezó con “Tienes toda la razón en investigar esto”. La dejé. Es la ocurrencia número 48.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?