Los Claude Code Skills consumen tokens aunque no se activen. Medí 5 Skills durante 7 horas — los 3 que nunca dispararon se llevaron el 11%.
Yo creía que los Skills de Claude Code eran una mejora gratis sobre los comandos personalizados. No son gratis. Son alquiler.
Esa frase es el artículo completo en quince palabras. El resto es yo mostrando los comprobantes.
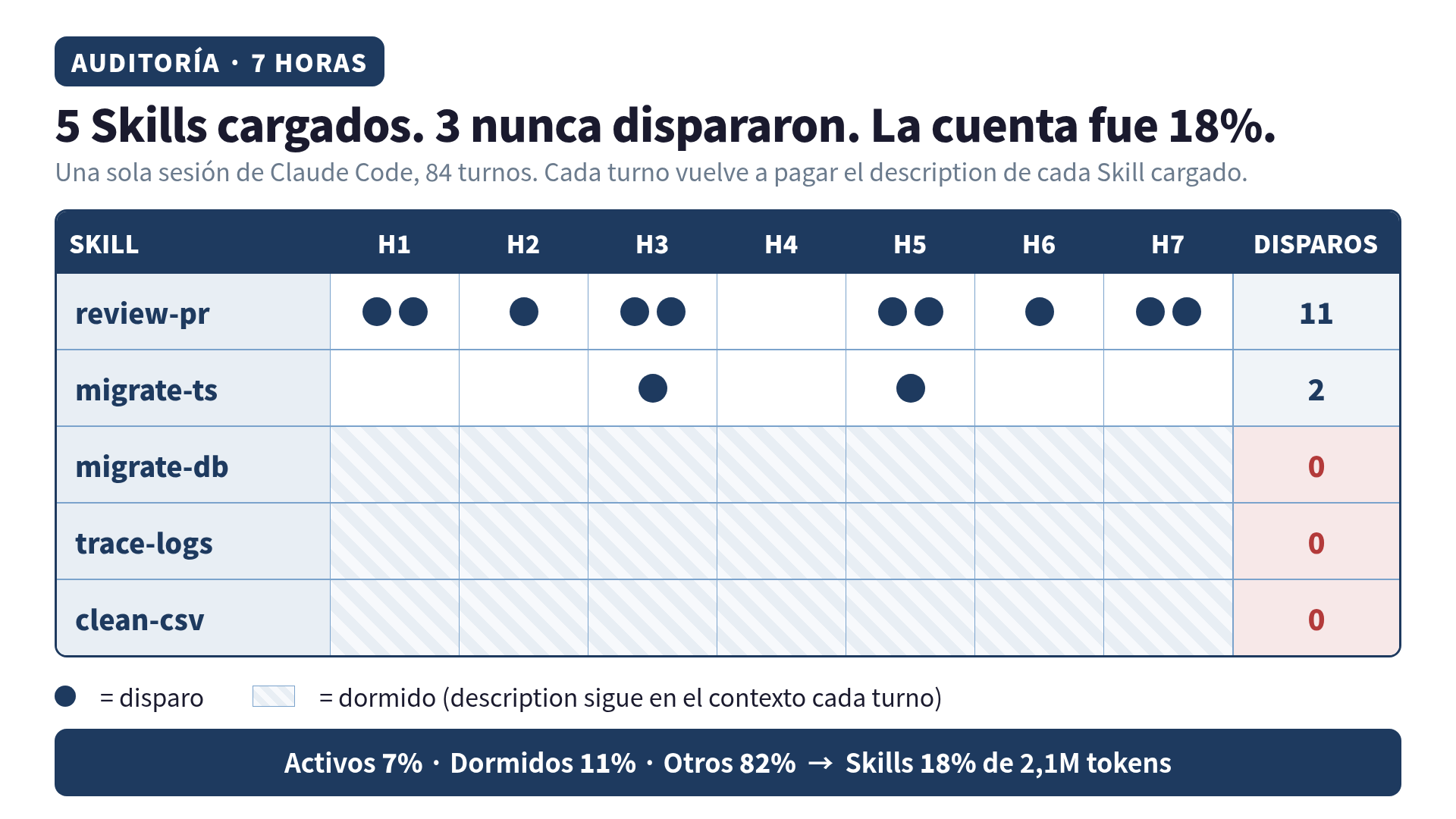
Un martes dejé una sesión de Claude Code corriendo durante 7 horas con 5 Skills cargados: revisor de PR, ayudante de migración de TypeScript, validador de migraciones de base de datos, rastreador de logs y limpiador de CSV. Tres de ellos no se dispararon ni una sola vez en todo el día. Revisé el log de invocaciones dos veces porque me costaba creerlo. Aun así, esos tres solos se llevaron alrededor del 11% del total de tokens de la sesión. Sumando los dos que sí trabajaron, los Skills se quedaron con el 18% de la cuenta.
Hasta ese día yo les decía a los compañeros que “los Skills solo cuestan cuando se disparan, así que podés dejarlos cargados sin problema”. Estaba equivocado, y de una forma que se puede medir en dinero.
Cómo se cargan los Skills en realidad
Está todo en la documentación. Yo lo leí por arriba.
Cuando empieza la sesión, Claude Code lee todos los Skills en el alcance. Lo que entra al contexto en ese momento es solo el name y el description del frontmatter del SKILL.md. El cuerpo del Skill todavía no entra. El cuerpo se carga recién cuando Claude decide que el description coincide con tu prompt actual, o cuando vos escribís /nombre-del-skill a mano. Una vez cargado, el cuerpo se queda en el contexto hasta que termina la sesión o se dispara la compactación.
Lo que yo no había internalizado: el description está en el contexto en cada turno. No solo al inicio de la sesión. Cada mensaje tuyo, cada respuesta de Claude, el description de cada Skill cargado sigue ahí como parte del prompt. Cinco Skills con description de unos 300 tokens cada uno son ~1.500 tokens de “esto es lo que estos Skills saben hacer” que se recobran en cada turno.
En una sesión de 80 turnos, ese mismo bloque de texto se paga 160 veces. Cada uno es chico. Pero es constante. Es el Skill cobrando alquiler.
La sesión que medí
Uso Claude Code como herramienta principal de trabajo. El día de la medición fue un martes normal: triaje de PRs a la mañana, refactor largo a la tarde, exploración en la shell al final del día. Una sola sesión, abierta todo el tiempo, con --output-format json --verbose pasando por un wrapper de log que guardaba el campo usage en cada respuesta.
Los 5 Skills que estaban en ~/.claude/skills/:
| Skill | longitud del description | función | ¿se disparó? |
|---|---|---|---|
review-pr | ~310 tokens | flujo de revisión de PR | sí (11 veces) |
migrate-ts | ~290 tokens | ayudante de migración TS | sí (2 veces) |
migrate-db | ~340 tokens | validador de migración DB | no |
trace-logs | ~270 tokens | rastreo de patrones en logs | no |
clean-csv | ~280 tokens | recetas de limpieza de CSV | no |
Total de description cargado por turno: ~1.490 tokens de metadatos de Skill, sentados encima del CLAUDE.md, el contexto del proyecto y la conversación viva.
La sesión duró 7h12, 84 turnos, ~2,1 millones de tokens entre entrada y salida (con prompt caching activo casi todo el tiempo).
El comprobante
Partí el consumo en tres categorías: total, “lo que habría sido sin Skills cargados” (estimación restando el overhead de description y el cuerpo de los dos que sí dispararon) y la diferencia. Los números reales:
| Categoría | Tokens | Porcentaje |
|---|---|---|
| Conversación, CLAUDE.md, lectura de código | 1.720K | 82% |
Skills activos (review-pr + migrate-ts) | 147K | 7% |
| Skills dormidos (descriptions, 3 nunca dispararon) | 231K | 11% |
| Total | 2.098K | 100% |
Los dos Skills que sí trabajaron costaron 7%. Está bien. Me ahorraron por lo menos esa misma cantidad en prompts que no tuve que volver a escribir.
Los tres que nunca coincidieron con nada costaron 11%. Retorno: cero. Con prompt caching activo, el costo de description por turno se absorbe parcialmente, pero solo parcialmente: cada vez que mi prompt cambia, la frontera del cache se mueve, el description se re-tokeniza y aparece en el input_tokens del billing. Once por ciento.
En una cuenta de Claude Code Max (USD 200/mes), 18% son USD 36/mes. De esos, USD 22/mes son los tres dormidos. Estaba pagando esa cifra por mantener tres archivos de texto en el contexto. No me animo ni a contarlo en la mesa familiar.
(Aproximadamente ARS 28.000, MXN 380 o CLP 20.000 al cambio de mayo 2026, según tu país.)
La auditoría del día siguiente
A la mañana siguiente repetí la misma carga de trabajo (mismo set de PRs, mismos tipos de prompt) con solo los dos Skills que habían disparado el día anterior. Consumo total: ~1.872K tokens. Caída de ~11% respecto al día previo. Dentro del ruido natural de “dos días nunca son iguales”, el número coincide con el alquiler que cobraban los tres dormidos.
Si querés hacer la misma medición en tu setup, alcanza con envolver el claude en un wrapper que lea el JSON del usage:
claude -p "$TU_PROMPT" --output-format json --verbose \
| jq '{input: .usage.input_tokens, cached: .usage.cache_read_input_tokens, output: .usage.output_tokens}'La línea que importa es input_tokens. Si tiene una deriva hacia arriba después de que agregás un Skill nuevo, estás pagando alquiler de description.
Por qué me agarró desprevenido
Yo trataba al Skill como un import de lenguaje de programación: costo cero hasta ser llamado. El import es gratis porque el compilador descarta lo que no se referencia. Claude Code no puede descartar. El description es justamente el material que usa para decidir si invoca o no. Si el description se cargara perezosamente, no tendría con qué decidir disparar el Skill en primer lugar.
Es una decisión de diseño coherente. De hecho, es la decisión correcta. Pero la consecuencia es que el costo marginal de “tener un Skill instalado y nunca usarlo” no es cero. Es un impuesto por turno que se va sumando a lo largo de la sesión.
No confundas esto con los Hooks. Los Hooks los dispara Claude Code a propósito en respuesta a eventos: pre-tool, post-tool, session-end. Los Hooks no se describen en el system prompt para hacer matching; se configuran en settings.json y el harness los llama cuando corresponde. Un Hook que nunca dispara cuesta cero de verdad. Un Skill que nunca dispara cuesta description × cada turno. Son mecanismos distintos viviendo en el mismo Claude Code.
Tampoco es lo mismo que un MCP server inactivo. Un MCP server inscribe la lista completa de herramientas en el system prompt al inicio de la sesión (una medición pública conocida dio ~27.000 tokens por servidor), pero ese es un costo fijo por servidor, no por turno. El Skill es más chico por unidad, pero suele haber más de ellos, y el ”× cada turno” termina multiplicando.
Checklist: cómo auditar tus Skills antes de que se lleven tu presupuesto
Acá lo hago una vez por mes. Diez minutos.
- Listá todos los Skills en el alcance.
ls ~/.claude/skills/, más el.claude/skills/del proyecto, más cualquier Skill que venga de un Plugin. Anotalos en un archivo. - Para cada Skill, fijate cuándo se disparó por última vez. Si estás logueando sesiones con
--output-format json, alcanza con ungreppor el nombre del Skill en las entradas de tool-use. Si no estás logueando, vas a depender de la memoria, y la memoria miente. - Marcá como “candidato” todo Skill sin invocaciones en los últimos 30 días. Todavía no borrés. Solo marcá.
- Mové el candidato al desván por una semana. Yo literalmente hago
mv ~/.claude/skills/<nombre>/ ~/.claude/skills-desvan/. Trabajá una semana así. Si no lo extrañaste, era alquiler. - Volvé a medir la línea base de
input_tokens. Misma carga de trabajo, sin los candidatos cargados. Si la línea bajó de forma clara, acabás de encontrar tu ahorro.
La trampa que conviene evitar: no borrés al candidato en el momento. A veces hay Skills que no disparan hace 30 días porque los usás en un cierre trimestral que te olvidás. “Al desván” es el término medio seguro.
Qué cambié en mi setup
Tres Skills se fueron al desván. Uno vuelve el mes que viene porque tengo una migración de base de datos programada. Los otros dos, probablemente se quedan ahí. Los dos activos siguen como están.
La sesión que estoy corriendo ahora para escribir este artículo también tiene solo dos Skills cargados. La línea del input_tokens por turno me quedó plana de un modo que antes no era (venía subiendo de a poco). 11% en voz alta suena poco. USD 22/mes solo por mantener tres archivos de texto en el contexto sin disparar nada tiene otra cara. En cuenta de API medida, depende del uso, pero es la misma historia con otro formato.
Cargar muchos Skills no está mal. Es práctico. Solo hay que saber que esa practicidad tiene un impuesto por turno, y que el impuesto es invisible hasta que te tomás el trabajo de mirarlo.
La frase que voy a pegar en el monitor: cargado ≠ activo ≠ pagado solo cuando se usa.
Corré el claude -p con --output-format json una vez y mirá el usage.input_tokens. El número está ahí hace rato contando esta historia. Yo era el que no estaba mirando.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?