Claude Code・Cursor・Codexを1日並列で走らせて、判断回数を数えたら412回だった
机の上にエージェントが3つ常駐しています。左モニタにClaude Code、右モニタにCursorのバックグラウンドエージェントが黙々とチケットをこなし、その下のtmuxペインでCodex CLIが長時間のデータ移行スクリプトを走らせている。2週間前、私はこの構成を「ようやく見つけた不公平なアドバンテージ」だと表現していました。3並列でだいたい3人ぶんのスループット。算数はきれいで、初日にブログ記事の下書きまで書き始めていたほどです。
そのブログ記事は公開しないままになりました。代わりに書いたのが今回のものです。なぜなら、1日録画して判断回数を数えてみたからです。
合計 412回。
8時間で412回のy/n判断。差分のaccept/reject、ツール呼び出しの承認、暴走したエージェントの停止、タブ切り替え、複数エージェントの提案からどれを採用するかの選択。だいたい70秒に1回、起きている時間ずっと小さな決定を下していました。午後2時40分、その日の朝に手で書いていた型付きイベントを壊すCursorのパッチを承認していて、翌日のPRレビューで指摘されるまで気づきませんでした。差分は14行。私が見ていた時間は9秒です。
請求書の数字は副次的でした。本当のレバーは判断回数のほうです。
スループット算で正当化したセットアップ
3エージェントの構成自体は、AnthropicとCursorが今春に並列セッションをそれぞれ正式版で出した時点で、自然な形に収束しました。Anthropicは2026年5月11日にAgent Viewを出し、その前の4月にデスクトップアプリの全面リデザインで並列セッション対応を入れ、続いて6月12日にDynamic Workflowsを出して、ひとつのClaude Codeセッションが複数リポジトリにまたがって数十のサブエージェントを同時調整できるようになりました。Cursor側は1.0でBackground Agentが全ユーザーGAになり、各バックグラウンドタスクが自前のworktree・自前のモデルセッション・自前のログストリームを持つ構成です。Codex CLIも構造としては同じ形をしています。
なので私の机はだいたい公式ドキュメントどおりの並びでした。
- Claude Code: 機能ブランチでvoice-AIリファクタ、メインセッション + バックグラウンドのサブエージェント2つ
- Cursor:
fix/og-emitでlintチケットを3件、未対面のままバックグラウンドエージェントが消化 - Codex CLI: 別worktreeで長時間のスキーマ移行を
--auto実行
1週間前にコスト試算はしてあって、3並列で1日使い込んでもSonnetの従量課金分が9ドル前後、それに既に契約済みのサブスク2本を足す程度です。ここは問題ではありません。誤差です。スプレッドシートを閉じて、私はちょっと得意げな気分になっていました。
モデル化していなかったコストは、その日の午後に私が払うことになるほうでした。
1日測ってみた、具体的な手順
雰囲気ではなく、数字が欲しかったので机を計測装置にしました。
# tmux: タイムスタンプ付きで全キーストロークを保存
script -f -q ~/logs/2026-06-23-desk.log
# claude-code: print + verboseで accept/reject を構造化出力
claude-code --print --verbose > ~/logs/2026-06-23-claude.jsonl
# cursor: .cursor/logs/ をあとから読む
# codex: ~/.codex/history.jsonl が標準で構造化されているそのまま9時から17時半まで通常運転、昼休憩を45分挟むだけです。事後に30行のPythonを書いて、ソース別に次を数えました。
- 差分に対する accept / apply / yes / [enter]
- 差分に対する reject / discard / no / esc
- 複数エージェント間で「こっちを採用」と明示的に選んだ回数
- Bash / Write / MCP の各ツール呼び出し承認
プロンプトのタイピング量はカウントしていません。読んでいる時間もカウントしていません。binaryに判定した瞬間だけを数えています。
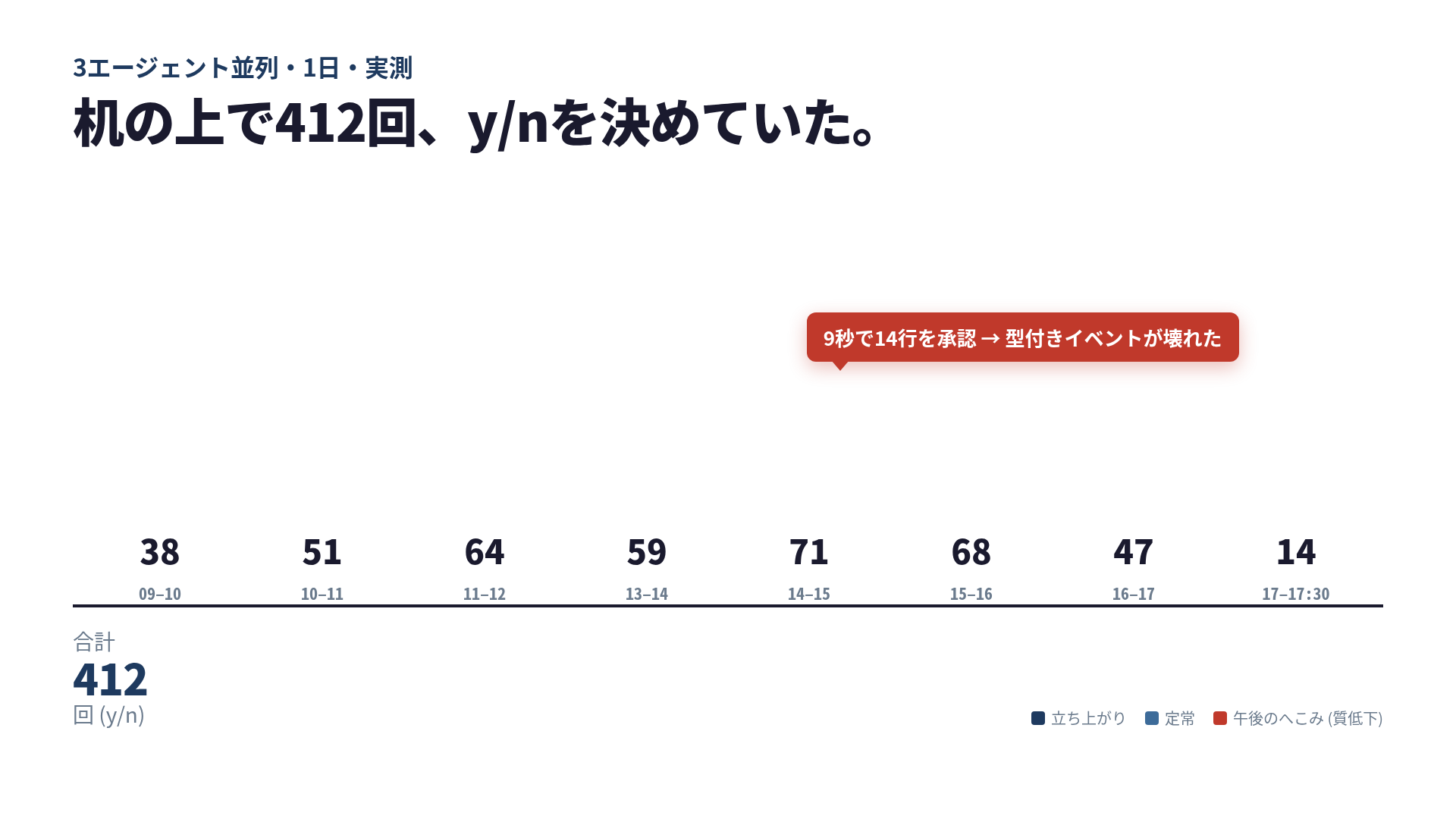
合計は412回。サイズより、時間帯ごとの形のほうが印象に残りました。
| 時間帯 | 判断回数 | メモ |
|---|---|---|
| 09–10 | 38 | セットアップ + 小さい初期差分、慎重 |
| 10–11 | 51 | Cursorが最初のチケットを上げてきた |
| 11–12 | 64 | 3ストリーム同時稼働、スループットのピーク |
| 13–14 | 59 | 昼食後、まだ精度は出ている |
| 14–15 | 71 | 体感は「絶好調」、実態は浅い |
| 15–16 | 68 | 例の壊れた承認はここ |
| 16–17 | 47 | 自分の意思でペースを落とした |
| 17–17 | 14 | 終了 |
事前に予想していた数字は150でした。実測は3倍近い。差分の大部分は、バックグラウンドの2エージェントが私に「束で」決定を送ってきていた、私が予算化していなかった分です。
1日400回の判断が本当に問題である理由
「夕方に疲れた」は気のせいで片付けられます。論文を片付けるのは難しい。
Roy Baumeisterのグループによる古典実験は、Vohs et al. 2008で読めます。学生を2群に分け、同じ商品群について、A群は「選ばせ」、B群は「ただ評価させ」ました。そのあと両群に別の認知課題を出すと、選ばせたA群のほうがその後の課題で成績が落ちました。情報量はほぼ同じ、違いは「決めたか/決めなかったか」だけです。
ego depletion (自我消耗) の枠組み自体は再現性論争で叩かれていて、「燃料が物理的に減る」モデルは弱まっています。私は強い主張は要りません。弱い形、「決断列の長さが、後続の決定の質を下げる」だけで十分です。この弱い形は、ほぼどこを見ても再現されています。
法廷でも、です。Danziger et al. 2011 (PNAS)は、イスラエル仮釈放委員会の判事8名による1,000件以上の判断を50日間ぶん分析しました。食事休憩直後の承認率は約65%、次の休憩直前は0%近く。同じ判事が、同じような案件を、時間帯で承認したり否決したりしていました。配列のバイアスへの反論論文があるのは公平に書いておきます。傾きの大きさには議論の余地があります。曲線の形自体には、ありません。
判事の判断は私の判断より「大きい」ものです。それでも、構造 ─ 同じ判定者・連続した binary 判断列・回復区間なし ─ は私が机の上で測ったものと同じ形をしています。私の午後3時のへこみは性格の問題ではなく、仮釈放率と同じカーブでした。
そこにAI固有のレイヤーが乗ります。Towards Decoding Developer Cognition in the Age of AI Assistantsが明確に書いているとおり、AI提案を読むのは自分が書いたコードを読むのとは認知的に別の作業です。受け入れる前に、モデルの論理を逆引きして自分のメンタルモデルに再マッピングする必要があります。CHI 2026のWhen Help Hurts: Verification Load and Fatigue with AI Coding Assistantsでは、60人の開発者で実際にこれを測っています。AI補助によって主観的負荷は下がり、所要時間も短くなる。一方で行動データから推定された verification-load は上昇し、その上昇が反復利用に伴うストレスと品質低下を説明していた、という結果でした。18.2ポイント楽になった主観は、次の午後から前借りした疲労です。
3並列のエージェント上でAcceptを1回押すというのは、70秒の単純なイベントではなく、論文が「蓄積する」と言っている検証サイクルに囲まれた70秒のイベントです。
計測後に変えたハーネスの動き
3並列をやめたわけではありません。スループットは本物です。直し方は「エージェントを減らす」ではなく、「412回の大半が、私の画面に届く前に消える」状態を作ることでした。
下の4つを翌週から入れて、同等のワークロードの日で 412 → 168 まで落ちました。机の上のエージェント数は変えていません。
人間の目を必要としない差分を事前承認する。412回のほとんどは興味深い選択ではありませんでした。lintの細かい修正、import順、prettier再実行、1行の型import。これらを allow-patterns.json でハーネス層で自動 accept にまとめると、約120イベントが消えました。品質は動いていません。3層に分けるレイヤリングの考え方はハーネス・エンジニアリングで詳しく書いています。本書版の「判断は人、実行はエージェント」です。
絶対に通したくないパターンを事前拒否する。短いdenylist ─ eval 禁止、curl | sh 禁止、secrets ディレクトリの編集禁止、未許可MCPサーバー禁止 ─ にマッチした差分は1行ログだけ残して自動 reject。約40イベント減。どれもレビュー時に確実に弾く判断だったので、その判断を機械側に移しただけです。
同じタスクに冗長にエージェントを当てない。同じlintキューの修正案をClaudeとCursorに二重で出させて「よさそうな方を採用」していた日があって、これがチケットごとに「勝者を選ぶ」判断税を払っていました。今は仕事の種類ごとにエージェントを固定しています。約50イベント減。しかも一番質の悪い種類のイベント ─ もっともらしい2つの出力を見比べて「どっちの論理がより間違っていないか」を選ぶやつ ─ がこれで消えます。
重要度の高い判断を午前に寄せる。午後のへこみが本物だと認めてしまえば、スケジュールはほぼ自動で決まります。PRレビュー、アーキテクチャ判断、間違えると1週間のロスになる類の決定は、9時から正午のブロックに固める。午後は、ハーネスが自動消化してくれる残りの2/3のタスクに充てる。先週の午後2時40分の壊れたマージは、10時半の私なら確実に弾けています。なら、10時半の私を、危険のある時間に動かせばよい。
合計: 412 → 168。エージェント数も予算も同じ、判断イベントだけ約6割減。減った分のほぼ全部が、つまらないほうの分布から消えています。
本当に意味があった数字
この計測を始めたとき、私が書こうとしていたのは料金についての記事でした。スプレッドシートを開いていて、エージェントごとのコストを従量とサブスクで分けたチャートまで作っていました。
そのチャートはこの記事の主役ではありません。誤差です。
並列エージェントの請求は、2つの通貨で来ます。ドルでの請求は小さいほう。判断回数での請求が大きいほうで、こちらは午後のパフォーマンス低下という形で支払うので、どの明細にも載りません。1日テープ録画して数えるまでは、ドルの数字が話の全部だと信じてしまいます。私が信じていたのと同じように。
この記事から1つだけ持ち帰るとしたら、こうです。自分の判断回数を、1日だけでも数えてみてください。私の数字を信じる必要はありません。普通の業務日に claude-code --print --verbose と script -f を仕掛けて、終わりにbinaryの判断イベントを数える。出てきた数字がいくつであれ、明日もその数字を払うことになります。次に問うべきは「この6割を、画面に届く前にハーネスで吸収できないか」です。
午後2時40分の私が、9秒で14行を承認する代わりにしておくべきだった問いです。
この議論の完全版: ハーネスの3層 ─ 制約・観測・自動化 ─ と、画面に届く前に判断を吸収するツール別パターンは、ハーネス・エンジニアリングで詳しく扱っています。複数エージェントを本気で運用しつつ、午後の自分にverification taxを払わせないためのフィールドガイドです。
このブログの関連記事:
この記事は役に立ちましたか?