Ollama 12.2 tok/s が34.6 tok/s になった: RTX 4070 で Qwen3 35B を2.8倍速にする1コマンド
「家庭用 GPU でも 35B は無理ではないけど、まあ遅いよね」と諦めていた時期が、私には2週間ありました。RTX 4070 で Qwen3 35B (MoE) を Ollama に投げ、12.2 tok/s でうなりながら出てくるトークンを眺めて、「これがローカルの限界か」と。
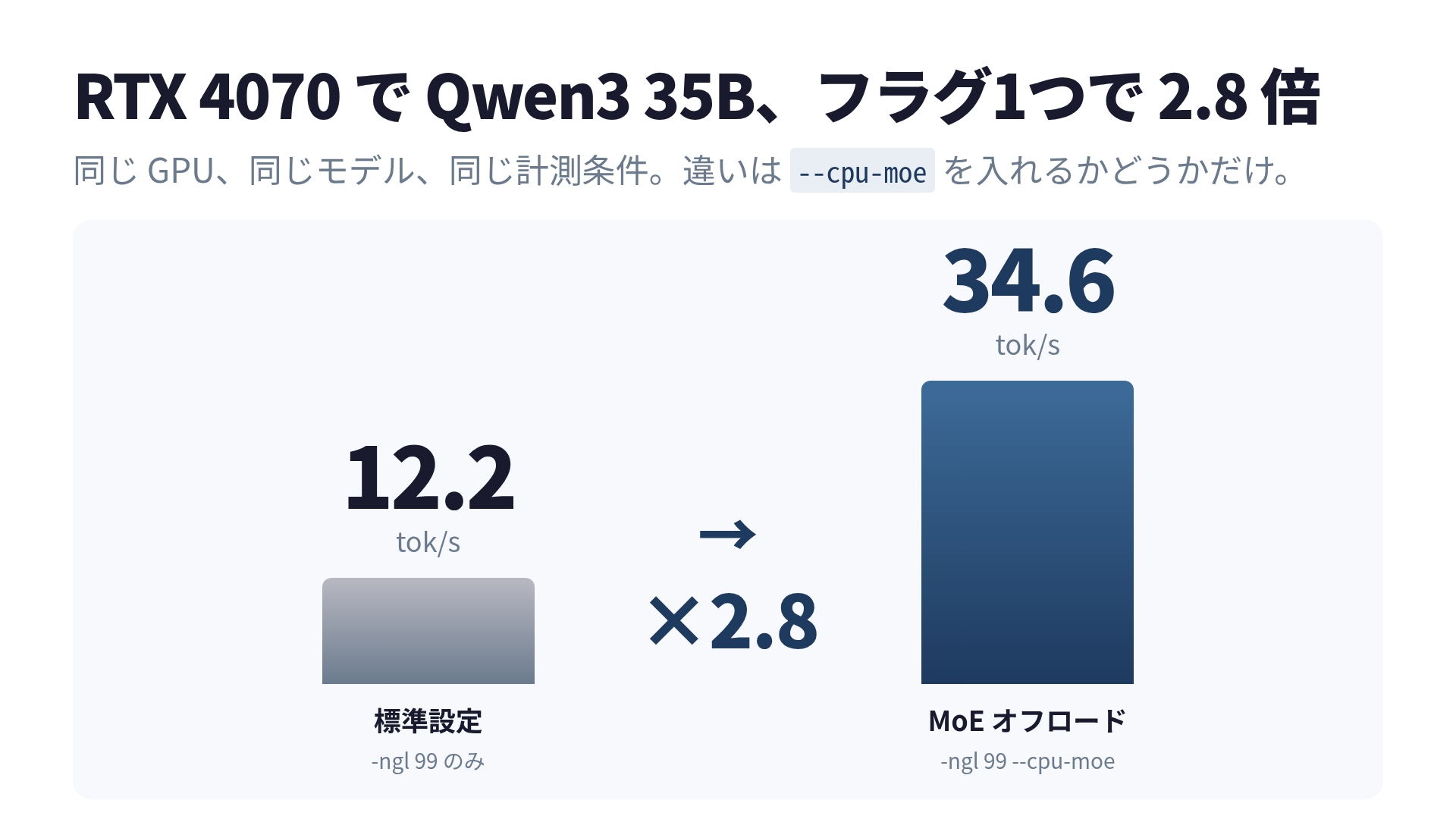
限界ではありませんでした。1つフラグを足したら34.6 tok/s になりました。2.8倍です。書いていることは違わないし、品質も変わっていません。なぜそれまで遅かったのか、なぜそのフラグで変わるのか を計測ログ付きで残します。
結論を先に: 足すフラグはこれだけ
llama.cpp 経由で動かす場合のコマンドはこうです。
./llama-bench -m qwen3-35b.gguf -ngl 99 --cpu-moe -n 128 -r 3-ngl 99は「全レイヤーをGPUに載せたい」という意思表示--cpu-moeは「ただし MoE の expert テンソルだけは CPU メモリに置く」という例外指定-n 128 -r 3は生成128トークンを3回試行 (これは計測の作法、後述)
Ollama を使っているなら Modelfile で PARAMETER num_gpu 99 と、MoE オフロード対応の num_cpu_moe 系パラメータを併用します (Ollama 側の対応状況は ollama/ollama Issue で更新が早いので、最新値を確認してください)。
このフラグ1つで、私の手元では tg128 が 12.2 → 34.6 tok/s、3回試行のばらつきは ±0.82。スループットが約2.8倍に伸びました。
なぜ Ollama の標準は遅かったのか
ここがこの記事の本題です。
Qwen3 35B は MoE (Mixture of Experts) です。総パラメータは 35B ありますが、推論時に「実際に動く」 active パラメータはずっと少ない (Qwen3-MoE 系の active 比率は公式ブログに記載があります)。
つまりこういう構造です。
- attention や normalization 系の「毎ステップ全部使う」テンソル
- expert FFN の「ステップごとに一部だけ使う」テンソル
Ollama の標準的な -ngl の挙動は「とにかく GPU に乗るだけ乗せる」です。MoE の expert テンソルは巨大で、全部 GPU に載せようとすると VRAM が足りず、レイヤー単位でしか載りません。結果、毎ステップ全部使う attention まで CPU 側に追い出されて、計算がボトルネックになります。
ここで --cpu-moe を入れると、判断が逆転します。「expert は CPU 側に置いて構わない、その代わり attention と毎ステップ系を全部 GPU に載せろ」という指示です。expert は CPU に置かれても、毎ステップ全部使われるわけではないので、ペナルティが軽い。一方 attention が GPU で回る分のリターンは大きい。
Hugging Face の MoE オフロード解説 もこの考え方を整理していて、要は「MoE モデルでは CPU オフロードの性能ペナルティは dense モデルよりずっと低い、なぜなら active なパラメータしか毎パスで使われないから」という話です。
家庭用 GPU で MoE を回すときに --cpu-moe を入れない理由は、ありません。
数字を出す前にやったこと: 計測の作法
「2.8倍速くなった」と書くなら、その数字を信用してもらえる出し方をしないと意味がありません。私が llama-bench で守っている3つだけ書いておきます。
1. ウォームアップ込みで複数回測る。 -r 3 で3回、平均と標準偏差を出させる。最初の1回はモデルロードやキャッシュ温め待ちで遅い。1発測りは信用しない。
2. 計測前に VRAM を空ける。 Chrome のタブが裏で WebGL を握っていただけで、GPU メモリが半分埋まっていたことが過去にあります。nvidia-smi でクリーン状態を確認してから計測。
3. 既知のベースラインを毎回併走させる。 「Qwen3 35B --cpu-moe なし = 12.2 tok/s」というベースラインを毎回1回挟む。これが崩れたら、新しい数字ではなく環境を疑う。
この作法を守らずに「Ollama 速いです」「llama.cpp 速いです」と書いてある記事を、私は最近かなり警戒しながら読んでいます。汚れた数字の上に積まれた結論は、全部汚れているからです。
どこに効いて、どこに効かないか
正直に書いておくと、--cpu-moe は万能ではありません。
| ケース | 効くか |
|---|---|
| Qwen3 35B / Mixtral 8x7B 系の MoE モデル | 大きく効く (1.5〜3倍) |
| Llama 3.1 70B のような dense モデル | 効かない (むしろ遅くなる) |
| 14B 以下の小型モデル (GPU 単体で全部載る) | 効かない |
| VRAM が圧倒的に足りない (4GB クラス) | そもそも全レイヤー GPU に載らないので、本記事の前提が崩れる |
つまり「家庭用GPU + 中型 MoE モデル」が一番おいしいゾーンです。RTX 4070 (12GB) + Qwen3 35B はまさにこのゾーンの中心で、私の手元でいちばん効いたケースでもこの構成でした。
逆に「VRAM 80GB の A100 に Qwen3 35B を全部載せる」状況では --cpu-moe は不要というか、有害です。GPU に全部載るならそのほうが速い。フラグは状況によって入れたり外したりするものです。
「家庭用 GPU でローカル LLM は遅い」の正体
今回のフラグ1つで2.8倍動いたという事実は、もう1段上の含意があると思っています。
「家庭用 GPU でローカル LLM は遅い」と言うとき、そのほとんどはハードウェアの問題ではなく デフォルト設定の問題 です。--cpu-moe のような、モデル構造を踏まえたオフロード戦略を入れていないだけで、ハードウェアの上限ではない。
これは Ollama や llama.cpp の責任ではなくて、MoE モデルが急に普及した2025〜2026年のローカル LLM 周辺の「デフォルトがまだ追いついていない時期」だから起きていることです。Mixtral も、DeepSeek-V2/3 も、Qwen3 系も、全部 MoE です。家庭用 GPU で35B クラスを回したい人にとって、--cpu-moe 相当のフラグを意識しているかどうかで、体感速度が2〜3倍違います。
2週間 12.2 tok/s で諦めていた私みたいな人が、世界にあと何人くらいいるのかと思うと、ちょっと申し訳なくなります。とりあえずこの記事だけでも届くといいなと。
まとめ
- RTX 4070 + Qwen3 35B (MoE) で
--cpu-moeを足すだけで 12.2 → 34.6 tok/s (2.8倍) - 仕組みは「巨大な expert は CPU に置き、毎ステップ使う attention を GPU に専有させる」
- MoE モデルでは CPU オフロードのペナルティが dense モデルよりずっと小さい (active 比率が低いため)
- 計測は
llama-bench -r 3+ VRAM クリーン + 既知ベースライン併走の三点セットで - dense モデルや小型モデルには効かない、家庭用 GPU + 中型 MoE が一番おいしいゾーン
ハードウェアを買い換える前に、フラグを1つ足してみてください。買い替えが2週間遅れるくらいの体感差は出ます。
この記事は役に立ちましたか?