RDFかプロパティグラフか — GraphRAG 2026を3つの質問で5分で決める
知り合いのデータエンジニアがNeo4jでGraphRAGを組み始めた頃、私は同じ題材をRDF/SPARQLで触っていました。お互い「自分の選択は正しい」と思っていたのですが、ある日同じ質問を両方のグラフに投げて答えを比べたら、得意な問いの種類が綺麗に割れていました。
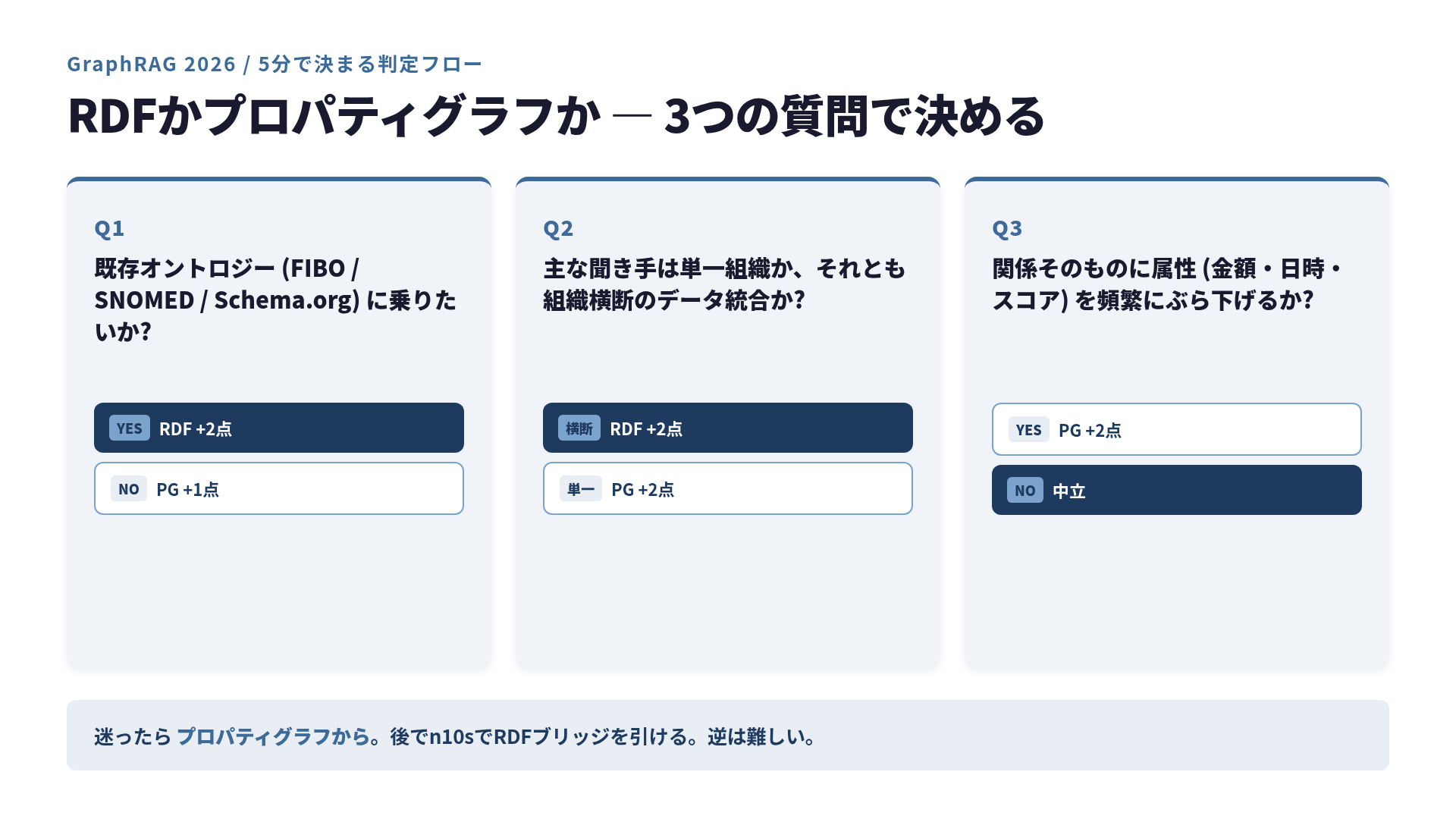
それ以来、私は「先にどっちが偉いか」を議論する前に、3つの質問で5分以内に決めることにしています。書いてしまえば紙1枚です。今日はその紙1枚を共有します。Neo4j 5系のCypher 25とISO GQLが動き始めた2026年版で。
なぜ「先に決めろ」と言うのか
GraphRAG界隈にいる方ならご存知の通り、Microsoftが2024年にGraphRAGを公開してから、知識グラフをLLMの検索層に置く構成は珍しくなくなりました。MicrosoftのGraphRAGは生成した三項組をプロパティグラフ形式に変換します (GraphProducer解説)。Microsoft Fabric Graphに至っては「ラベル付きプロパティグラフ(LPG)のみサポート、RDFはサポートしない」と明言しています (Microsoft Fabric Graph docs)。
つまり大手の最新サービスを使うだけならプロパティグラフ一択に見えます。それでもなぜRDFが残っているのか。理由は単純で、問いの種類が違うから です。「製薬会社の治験データを既存のオントロジーに重ねて推論したい」と「自社CRMの顧客行動をたどってレコメンドしたい」は別の問題です。前者はRDF/SPARQLが30年積み上げてきた推論器とオントロジー資産が効きます。後者はプロパティグラフの素直な可視化とCypherの学習コストの低さが効きます。
判定は5分でいいと書きましたが、判定をしないで進めると、3か月後に「Neo4jで全部組み終わってからオントロジー統合の要件が降ってきて全書き直し」みたいな話になります。逆も起きます。私は両方目撃しました。
質問1: 既存オントロジーに乗りたいか
最初の質問はこれだけです。
自分の領域に、既に世界で標準化されつつあるオントロジーがあって、それに乗りたいか?
具体例で言うと、金融ならFIBO、医療ならSNOMED CT やRxNorm、Webコンテンツ全般ならSchema.org。これらが既に「概念とその関係」をRDF/OWL形式で定義していて、業界全体でURIが共有されています。
ここに乗りたい場合は、ほぼ自動的にRDFです。プロパティグラフでも同じ意味の構造は組めますが、外部とのデータ交換のたびにRDFへのマッピングを書くことになります。Neo4jのn10s (neosemantics) プラグインでRDFのインポート/エクスポートはできますが、それは「2つの世界の間にブリッジを毎回引いている」状態で、量が増えると保守コストになります。
逆に、自分のドメインにそんな共通語彙が存在しない、あるいは存在しても採用する気がない場合は、この質問でRDFを選ぶ理由はほぼなくなります。社内CRM、SaaSの行動ログ、リポジトリ内のコード関係 — どれも標準オントロジーがあって嬉しい類のドメインではありません。
質問1がYesならRDF寄り、Noなら次の質問へ。
質問2: データの主な聞き手は組織内か、組織横断か
二つ目の質問です。
このグラフから情報を取り出す「主な聞き手」は、自社のアプリケーション一つか、それとも他組織と共有しながら使うか?
RDFのいちばんの強みは、私の感覚では「組織を超えて意味が壊れない」点です。W3Cの仕様としてのURI、SPARQLの連合クエリ (federated query)、OWLによる推論。これは複数の組織が自分のグラフを持ち寄って統合する場面でほとんど無敵です。Linked Open Dataが20年以上続いている理由でもあります。
一方、プロパティグラフは「単一の組織が自分のドメインを表現する」ときに気持ちよく刺さります。Neo4jのCypherは学習コストが低く、MATCH (a:Customer)-[:BOUGHT]->(p:Product) のような表現が直接書けます。エッジに属性 (購入日、金額、チャネル) を直接ぶら下げられるので、業務ロジックがそのままモデルになります。
判断軸として書き下ろすと、
- 同一企業内のサービス用 = プロパティグラフ
- 複数組織でのデータ統合 / 公的データセットとの相互運用 = RDF
- 学術や標準化を視野に入れる = RDF
- 「うちのCRMで使うだけ」 = プロパティグラフ
質問2が「組織横断」ならRDFを残す理由が増えます。「単一組織」ならプロパティグラフ寄りに針が振れます。
質問3: 関係そのものに属性を頻繁にぶら下げたいか
三つ目です。
グラフのエッジ (関係) に、属性をたくさん、頻繁に乗せたいか?
具体的に言うと、「AさんがBさんに送金した」というエッジに、金額、日時、チャネル、手数料率、不正検知スコアを直接乗せたい、というケース。あるいは「コードAがコードBを呼ぶ」というエッジに、呼び出し回数、最終呼び出し時刻、呼び出し元ファイル、を直接乗せたい、というケース。
プロパティグラフはこの設計が母国語です。エッジ自体がオブジェクトで、ノードと同じように属性を持てます。
CREATE (a:Account {id: "A001"})-[:TRANSFER {
amount: 100000,
currency: "JPY",
timestamp: datetime(),
channel: "mobile_app",
fraud_score: 0.02
}]->(b:Account {id: "B042"})これが書けるかどうかが、業務ロジックがそのままモデルになるか、「もう一段マッピングが要る」かの分岐点です。
RDFでも同じことはできますが、三項組 (主語・述語・目的語) の世界観なので、エッジに属性を載せるには reification という回避テクニックを使います。「この三項組という事実、それ自体について語る」というメタな構造です。RDF 1.2ではRDF-star というショートカット記法が標準入りしましたが、それでも素のプロパティグラフほど自然にはなりません。
質問3が「エッジ属性を頻繁に乗せたい」ならプロパティグラフ。「ほぼノード中心の関係しか張らない」ならRDFも普通に戦えます。
3つの質問の結合
整理するとこうなります。
| 質問 | Yes | No |
|---|---|---|
| 1. 既存オントロジーに乗りたい | RDF +2点 | プロパティグラフ +1点 |
| 2. 組織横断で使う | RDF +2点 | プロパティグラフ +2点 |
| 3. エッジ属性が頻繁 | プロパティグラフ +2点 | 中立 |
合計点でだいたい決まります。3つ全部Noだとプロパティグラフ +3点、3つ全部Yesでも軸が割れます (RDF +4点、プロパティグラフ +2点)。私が今までこのフローを使った範囲では、迷ったケースのほとんどで質問2か3で針が大きく振れて、5分以内に決着しました。
ただしGraphRAG文脈で一つ補足が要ります。LLMからのアクセシビリティ という観点では、2026年6月時点でCypherの方が一歩リードしています。LLMにクエリを書かせる場合、Cypherの方が学習データに大量に乗っており、ZeroShotの正確度が高いという報告が複数あります。GraphRAGをLLMで触らせる前提なら、迷ったときの判断材料として「Cypher側」に薄く重みを足してください。
業界の動き — Cypher 25とGQLが追いついた
2026年に念のため知っておくべき変化は、Cypher側が ISO GQL という標準仕様にほぼ揃ってきたことです。GQLはISO/IEC 39075
として2024年4月に発行され、グラフデータベースの初の国際標準クエリ言語になりました。Neo4j側の動きは具体的です。Neo4j 5系では Cypher 5 と並んで Cypher 25 が選べるようになっており、Cypher 25 はGQL準拠の関数エイリアス (ceiling, local_time, path_length ほか) や IS LABELED 述語など、GQLの機能を取り込み続けています (Cypher Manual)。Neo4j 2026.02 以降の標準設定では、新しいデータベースは Cypher 25 がデフォルトになりました。
「Cypherはベンダーロックインだ」というRDF派の長年のツッコミに、Cypher側がGQLの旗で答えた、というのが2026年の構図です。プロパティグラフを選ぶ心理的ハードルが、一段下がっています。
一方のRDF側は、Stardog、GraphDB、Virtuoso といった既存のトリプルストアが安定運用フェーズに入り、Apache JenaやOxigraphの軽量実装も健在です。W3CではRDF 1.2 / SPARQL 1.2 のWD (Working Draft) が進行中で、特にRDF 1.2のRDF-star導入はエッジ属性の弱点を埋める方向に効きます。RDFが消える兆候はありません。「乗りたい標準が違うだけ」というのが正しい捉え方です。
友人と私で割れた問い
最後に冒頭の話を回収します。Neo4j側の友人 (社内SaaSのレコメンド改善担当) と私 (法務系の規制マッピング) で、同じ質問をぶつけました。
-
「最近6か月で頻繁に使っているユーザーが、購入したことのない商品カテゴリは?」
- Neo4j側は数行のCypherで返ってきました。私のSPARQLは、ユーザーの活動を時系列で扱うために中間ノードをいくつか挟む必要があり、書く長さで負けました。
-
「ある規制Aと、それを参照している規制Bがあって、Bが廃止された場合にAに影響が出るか?」
- 私のRDF/OWLは規制間の参照関係をオントロジーで形式化していたため、推論器が「Aの一部要件はBの廃止で再評価が必要」と返してきました。Neo4j側はクエリを手で書き、しかも「廃止の影響範囲」というドメイン知識をクエリの中に書くことになりました。
得意な問いがきれいに分かれました。これが質問1 (既存オントロジー) と質問2 (組織横断) の差そのものです。私の側は規制文書のオントロジーに乗りたかった (FIBO的な世界観)、友人の側は社内データだけで完結したかった。質問の答えが事前にわかっていれば、お互い5分で同じ結論にたどり着きました。
まとめ — 紙1枚の判定フロー
5分で決まるように、もう一度書きます。
- 既存オントロジーに乗りたいか? → Yes なら RDF寄り
- 組織横断で使うか? → 横断ならRDF、単一組織ならプロパティグラフ
- エッジに属性を頻繁に乗せるか? → 頻繁ならプロパティグラフ
迷ったら プロパティグラフから始めて、必要になったらn10sでRDFブリッジを引く。これはMicrosoft Fabricが現にやっている戦略で、初手のリスクを下げます。逆に最初から既存オントロジーに乗ると分かっているなら、最初からRDFで組んだ方が後悔が少ない。
GraphRAGの実装そのものの議論は別の機会にしますが、土台のグラフモデル選択は、この3つの質問で十分です。3か月後に書き直さない選択を、今5分で。
GraphRAGとプロパティグラフ実装の詳細は、私のKindle本にまとまっています。
ChatGPTの嘘を見抜く!Knowledge Graph実践ガイド — RDF vs Property Graphの選定からGraphRAG実装まで、判定基準と実装パターンを一通り。
この記事は役に立ちましたか?