マルチエージェントは並列化で速くなる、は幻想だった — 調整コストはエージェント数の二乗で増える
最初に白状しておくと、私は「エージェントを10体並べれば10倍速く終わる」と本気で信じていた時期があります。10個のマイクロサービスを同時にリファクタリングする案件で、1サービスにつき1体、合計10体のClaude Codeを一斉に走らせました。頭の中では、10本のレーンを並走するF1マシンの映像が流れていました。実際に起きたのは、10台が同じ交差点に同時侵入して全員が止まる、朝の駐車場みたいな光景でした。
この記事は、その失敗を「事故の体験談」として語る話ではありません。私は以前、3セッションを並列で8時間走らせて互いの変更を上書きし合った件を書きましたが、あれは現場の事故記録です。今日書きたいのはもっと素っ気ない話で、なぜ並列エージェントが詰まるのかを、調整コストという1つの量に絞って数式で示します。結論を先に言うと、調整コストはエージェント数の二乗で増えます。だから「数を増やせば速くなる」は、ある台数を超えた瞬間に逆向きに働き始めます。
並列化で速くなるのは「調整がゼロ」のときだけ
まず、並列化が本当に効く条件をはっきりさせておきます。タスクが完全に独立していて、エージェント同士が一切やり取りしなくていいなら、台数を増やすほど速くなります。これは正しい。1000枚の画像を別々にリサイズする作業を10体に振れば、おおむね10倍速く終わります。お互いの存在を知る必要すらないからです。
問題は、ソフトウェア開発がそういう作業ではないことです。サービスAのレスポンス形式を変えれば、それを呼ぶサービスBに影響します。共通の package.json は全員が触ります。あるエージェントが書いたテストが、別のエージェントの変更で壊れます。つまりエージェントたちは独立しておらず、互いに状態を共有しています。そして共有がある瞬間、台数を増やすと「調整しなければならない相手の数」が爆発的に増えます。
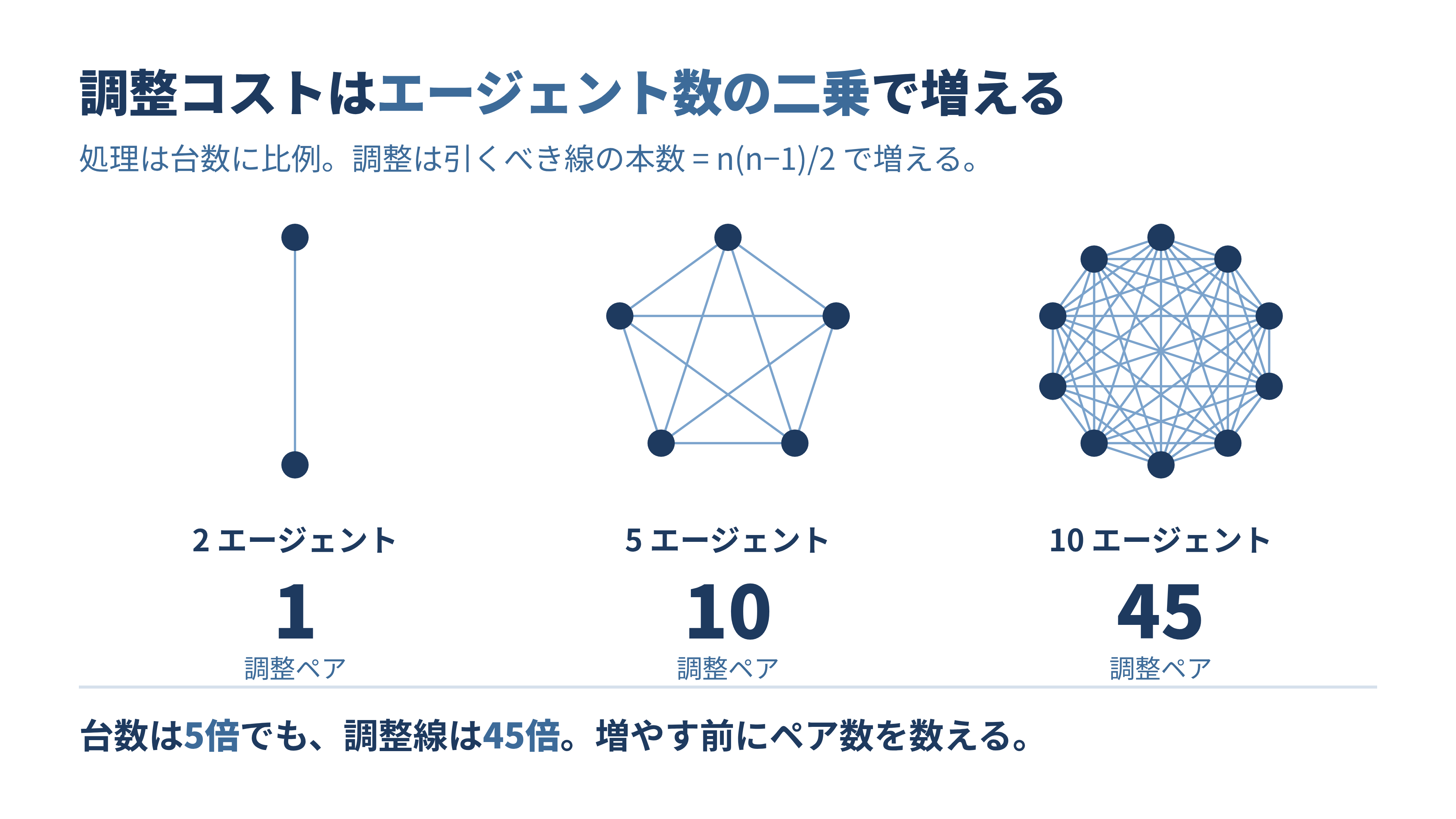
ペアの数を数えてみる
ここが数式の話です。難しくありません。n体のエージェントがいて、全員が互いに整合を取る必要があるとき、調整すべきペアの数は組み合わせの数 C(n, 2) で決まります。式にすると n(n−1)/2 です。実際に値を入れてみます。
| エージェント数 | 調整が必要なペア数 |
|---|---|
| 2体 | 1 |
| 3体 | 3 |
| 5体 | 10 |
| 10体 | 45 |
| 20体 | 190 |
2体から10体へと台数は5倍にしただけなのに、調整ペアは1から45へと45倍に増えています。これが「二乗で増える」の正体です。エージェントを1体足すたびに、その新人は既存の全員と整合を取らなければならない。10体目を足した瞬間、新たに9本の調整線が引かれます。処理を分担して速くなるぶんは台数に比例(線形)してしか増えないのに、調整の負担は二乗で増える。どこかで必ず後者が前者を追い抜きます。
私の10体リファクタリングで具体的に何が45本の線になったかというと、こうです。
- 共有リソースの競合: 10体が同時に
package.jsonを編集してコンフリクトが多発した - API契約の不整合: サービスAが返す形式を変えたのに、サービスBの担当エージェントはそれを知らない
- テストの相互破壊: サービスCのテストが、サービスDの変更で壊れたのに誰も気づかない
- コンテキストの分断: 各エージェントが自分の担当範囲しか見ておらず、全体の整合を判断できない
どれも「エージェントが無能だから」起きたわけではありません。各エージェントは自分の持ち場では正しく仕事をしています。破綻したのは、45本の調整線を誰も引いていなかったからです。これは分散システムでいうビザンチン将軍問題の縮図で、各将軍が自分の判断で動くのに、将軍間の通信が不完全だと全体として矛盾した行動になる、あれと同じ構図です。
2026年の実測も「3〜4体が現実的な上限」と言っている
私の体験談だけだと根性論に聞こえるので、最近のデータを並べます。2026年の運用知見では、エージェントチームの現実的なサイズは3〜4体が上限とされています。理由はまさに調整コストの急増です。4体のパイプラインでは、実際の処理が500msなのに対して、調整のオーバーヘッドがおよそ950msに達したという測定があります。仕事そのものより、仕事の段取りのほうが時間を食っている状態です。
数字はもう少し続きます。ツールが多い環境(APIやツールが10個を超えるあたり)では、コンテキストの分断と記憶の分割によって2〜6倍の効率低下が起きるとされています。そして本番投入されたマルチエージェント系の失敗率は41〜86.7%という、目を疑う幅のレンジで報告されています。原因の多くは仕様のあいまいさと、調整プロトコルが構造化されていないことです。要するに、私が10体でぶつかった45本の調整線を、本番システムも同じように踏み抜いています。
ここで効率の話を金額に翻訳すると、もっと刺さります。テストでは0.50ドルで済んでいたワークフローが、10万回の実行規模になると月5万ドルに化けるケースが報告されています。オーケストレータがタスク分解と結果集約のために、ワーカーの呼び出しとは別に何度もLLMを叩くからです。調整コストは時間だけでなく、そのまま請求書に乗ります。
では何体が正解か
数式は「少ないほどいい」とは言っていません。「調整線が引けないなら増やすな」と言っています。順序が逆です。台数を先に決めて調整方法を後から考えるのは詰まる手順です。引ける調整線の本数から台数を逆算します。
私が10体の失敗から持ち帰った原則は3つでした。第一に、エージェント数は最小限にする。並列で速くなるぶんは線形、調整コストは二乗なので、3体を超えるなら明確なオーケストレーション戦略が前提条件になります。第二に、共有状態を最小化する。各エージェントが触るファイルの範囲をきっぱり分け、共有リソースは「1体だけがオーナー」にするかロックをかけます。package.json を全員が触れる状態は、45本の調整線を自分から引きに行っているのと同じです。第三に、通信プロトコルを先に決める。何を、どの形式で、いつ伝えるか。これがないと各エージェントは孤島になり、全体の整合は誰も保証できません。
結局のところ、マルチエージェントの設計は「速いエンジンを10個積む」発想ではなく、「10個のエンジンをどう連動させるか」の配線設計です。私が最初に思い描いていたF1の並走映像は完全に間違っていて、正しい比喩はオーケストラでした。奏者を増やせば音は増えますが、指揮者がいなければ増えるのは音量ではありません。不協和音です。10体並べて10倍速くなると思っていた私は、要するに指揮者なしで45人を舞台に上げて、なぜ揃わないのかと客席で首をかしげていたわけです。
エージェント数を増やす前に、引くべき調整線が何本になるか数えてみてください。n(n−1)/2 を一度電卓に入れるだけで、たいていの「とりあえず並列化」は思いとどまれます。私のように45本目で気づくより、ずっと安く済みます。
この調整コストの問題を含め、エージェントを支える足場(ハーネス)をどう設計するかについては、書籍『ハーネス・エンジニアリング』で体系的にまとめています。並列数の決め方だけでなく、共有状態の分離や通信プロトコルの設計まで、現場で踏んだ地雷を含めて書きました。
この記事は役に立ちましたか?