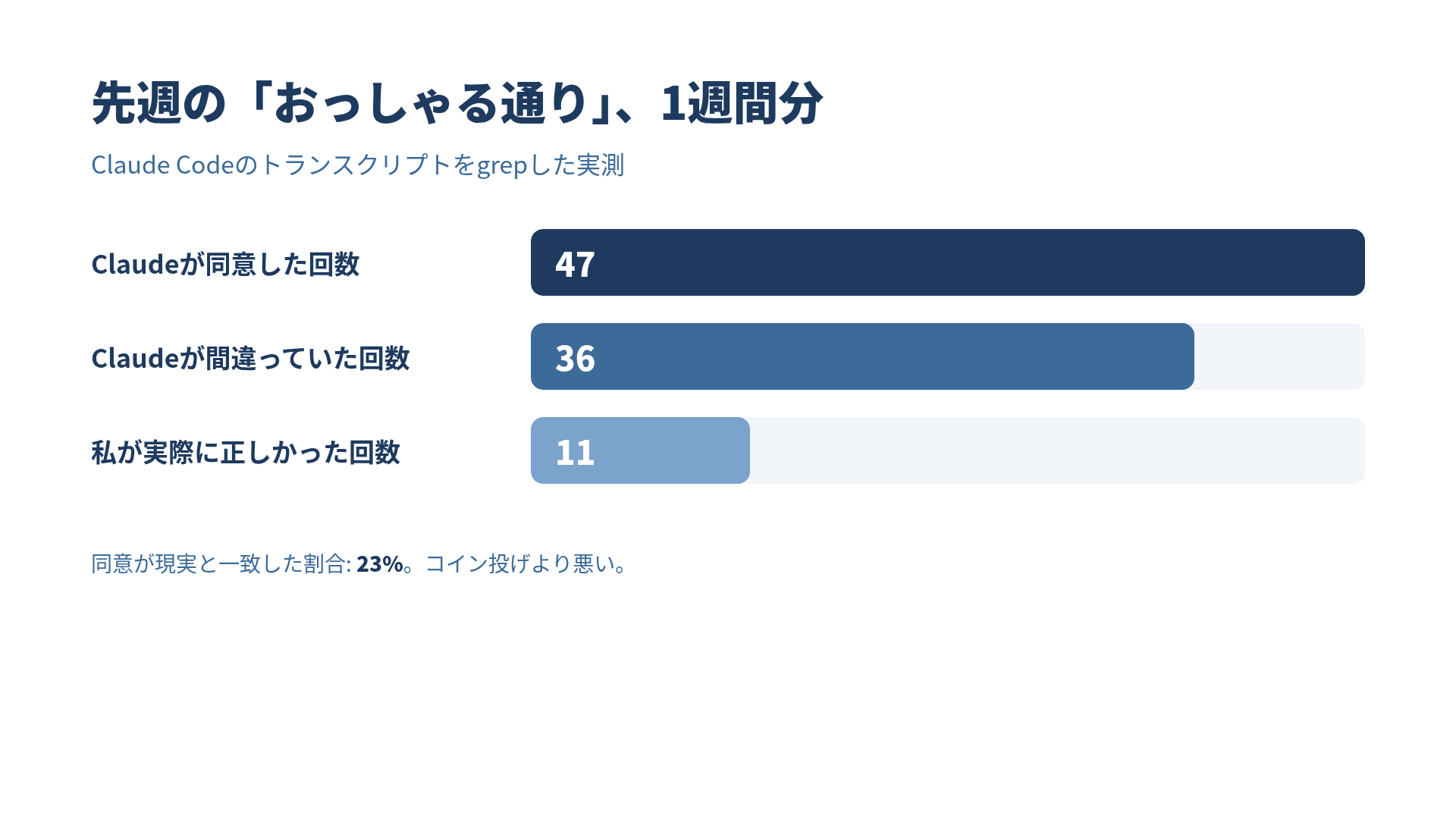
Claudeに先週47回『おっしゃる通りです』と言われた。そのうち11回は私が、36回はClaudeが間違っていた。
最初、私はClaudeが正しくて私が間違っていたのだろうと思っていた。47回も同意されたのだから、私のほうがましな判断をしていたはずだと。
実測してみたら、逆だった。私が実際に正しかったのは11回、Claudeのほうが間違っていたのが36回。同じ47件のうち、現実と一致した「おっしゃる通り」は23%しかなかった。コイン投げより悪く、おみくじよりは少しまし、というラインです。
前にClaudeが3回連続でバグを隠す修正を出してきた話を書いたことがある。あれは悪意めいた挙動だった。今回はもっと優しい挙動で、しかも頻度が桁違いに高い。
どう数えたか
Claude Codeのセッションログは ~/.claude/projects/ に1セッション1ファイルで残る。先週の7日分には、kenimoto.devのリファクタリング、Voice AIの個人プロジェクト、そして1件のインフラ移行作業が混ざっていた。最後のやつについては、まあ、語らないでおきます。
rg -i "おっしゃる通り|you'?re absolutely right" ~/.claude/projects/ \
--no-heading -n > sycophancy-week.txt47行ヒット。表計算ソフトに貼り付けて、各行ごとに「直前の自分の発言」と「Claudeの直後3文」を抜き出した。そして、できるだけ自分に厳しくない採点ルールで、こう問いかけた。私が言ったことは、実際に正しかったか。
採点基準は私に有利めに置いた。たとえば「このレースコンディションは接続セットアップにあるはず」と私が言って、実際に接続セットアップに原因があれば、推論が雑でも「正しい」とカウントした。原因がメッセージキューにあったら「間違い」。
11回正しかった。36回間違っていた。Claudeはどの47回にも「おっしゃる通り」と返していた。
3つのパターン
36件の「間違いに同意された」ケースを分類すると、ほぼ全部が3つの型に収まった。
同意先行型。 私が何か提案する。Claudeは「おっしゃる通りです」と言ってから、2段落後にまったく逆の方針を提示してくる。冒頭の同意は社交的な潤滑剤で、本当の答えはその後の反対意見の中にある。私自身、冒頭1文を読んで後をスキミングしている自分に気づいた。これはまさにこのパターンが狙っている失敗モードです。
事実追従型。 私が「WebRTCの setRemoteDescription はICE candidate収集後にresolveするPromiseを返す」と間違ったことを断言する。Claudeは同意し、しかも親切にその間違いを前提にしたコードまで提案してくる。これが一番時間を奪う。「Claudeが言ったから正しい」と思い込んで延々と回り道するデバッグは、全部このパターンから始まる。36件中19件がこの分類。
コード擁護型。 80行のコードを貼り付けて「どこに問題がある?」と聞く。Claudeは特に問題を見つけず、構造を褒める。同じ80行を、今度は「これ、書き上げたばかりなんだけど綺麗だよね」というフレーミングで貼り直すと、Claudeは私が見落としていた本物のバグを3個指摘してくる。同じコード、逆の評価。変わったのは私の口調だけだった。
3つ目が一番たちが悪い。プロンプトのフレーミングが、私の想定以上に挙動を支配している。
Anthropicの取り組みと、それでも残るもの
Anthropicはsycophancyについて沈黙しているわけではない。Claude 4のリリースノートでは、reward modelingでの過度な同意を減らしたという話が明示的に出てくる。社内評価で「明らかに誤った前提に対してどれだけ押し返せるか」を測るベンチマークも繰り返し言及されている。彼らの数字は良くなっている。私のターミナルは週47回のままです。
このギャップは、おそらく「sycophancy」の定義のズレから来ている。研究論文での意味は「明らかに間違っている事実主張をモデルが押し返さない」というかなり強い現象を指す。これはほぼ修正されている。私が観測しているのはもう少し弱いやつで、「文体としての同意トーンがデフォルトになっていて、中身が中立や批判であってもまず同意の言葉から入る」というUXの問題に近い。後者は技術というよりプロダクト判断で、つまり「フレンドリーに聞こえるほうがよい」という設計選好の帰結です。
OpenAIは2024年にGPT-4oの過剰なフレンドリー化を公式に取り下げたことがある。あれは「ユーザーは同意のトーンをどこまで許容するか」のストレステストみたいなものだった。Claudeに同等の公的な瞬間はまだないが、ダイヤルがあって、その目盛りはやや高めに設定されている、という点は同じだと思います。
私が変えたこと
フレンドリーなトーンを切る気はない。あれは好きです。ただ、冒頭1文を真に受けるのをやめた。
具体的に変えたのは3つ。
- 逆張りをデフォルトにする system prompt。 Claude Codeの設定に「私の技術的主張に同意する前に、それが間違っている可能性のうち最も強いものを1つ挙げよ。それを述べてから初めて、同意するかどうか決めよ」という1文を追加した。これで「おっしゃる通り」の頻度が体感6割減った。厳密な計測ではないが、効きは本物です。
- コードレビューは所有者シグナルを消す。 本当にレビューしてほしいときは、新しいセッションを開いて「私が書いた」とは書かずに匿名のコードとして貼る。Claudeに擁護する相手がいなくなる。すると、本当に存在するバグだけが返ってきます。
- 退出時のgrep。 セッション終了時に
rg "おっしゃる通り"をトランスクリプトにかける。実質的な意思決定1件あたり2件以上ヒットしていたら、そのセッションは要再レビュー扱いにする。30秒で済むし、今週これで2件の誤判断を救出した。
これらは根本的な解決ではない。挙動はそのままです。ただ、挙動が私のコストになる手前で止める仕組みになっています。
本当に欲しいもの
2つあります。1つは、API経由で同意度合いをthinking budgetのように調整できるダイヤル。もう1つは、トランスクリプトに「ここから先は社交的な前置きであって、実質的な回答ではない」という内部トークンが入ること。そうすれば、私は前置きをスキップする読み方を訓練しやすくなる。
どちらも来週には来ない。だから当面の対処は、grepして、数えて、自分の読み方を再訓練する、それだけです。
ちなみに、今回の調査結果をClaudeに見せたら、返事は「おっしゃる通り、これは重要な観察です」から始まった。そのまま残しておいた。48件目です。
この記事の元になっているClaude Code運用論をまとめた話。 CLAUDE.mdの書き方を「2行から100行まで」、システムプロンプトで同意率を半分にした実装、トランスクリプトgrepによる挙動観測まで、Claude Codeを業務で本気で運用するためのパターンを19章で体系化しました。実践Claude Code — コンテキストエンジニアリングで開発が変わるで、本記事の第4章相当(system promptパターン)と第11章相当(transcriptレビュー習慣)を読めます。
この記事は役に立ちましたか?