Strategist に WebSearch を持たせたら 5テーマ選びに 20分かかった - Observer / Strategist / Marketer 3役分離で 3分にした話
私は最初、1つのエージェントに「観測+戦略+実行」を全部やらせていました。claude -p を1回叩いて「今日のテーマを5つ選んで記事を書いてくれ」と。エレガントな構成のつもりでした。
5テーマ選ぶだけで20分かかりました。
Observer / Strategist / Marketer の3役に分離したら、同じ仕事が3分で終わるようになりました。トークンコストは約60%減。エージェント1人1人は前より小さいことしかしないのに、パイプライン全体は速くなりました。
コツは「エージェントを増やす」ことではありません。判断役からWebSearchを取り上げることです。
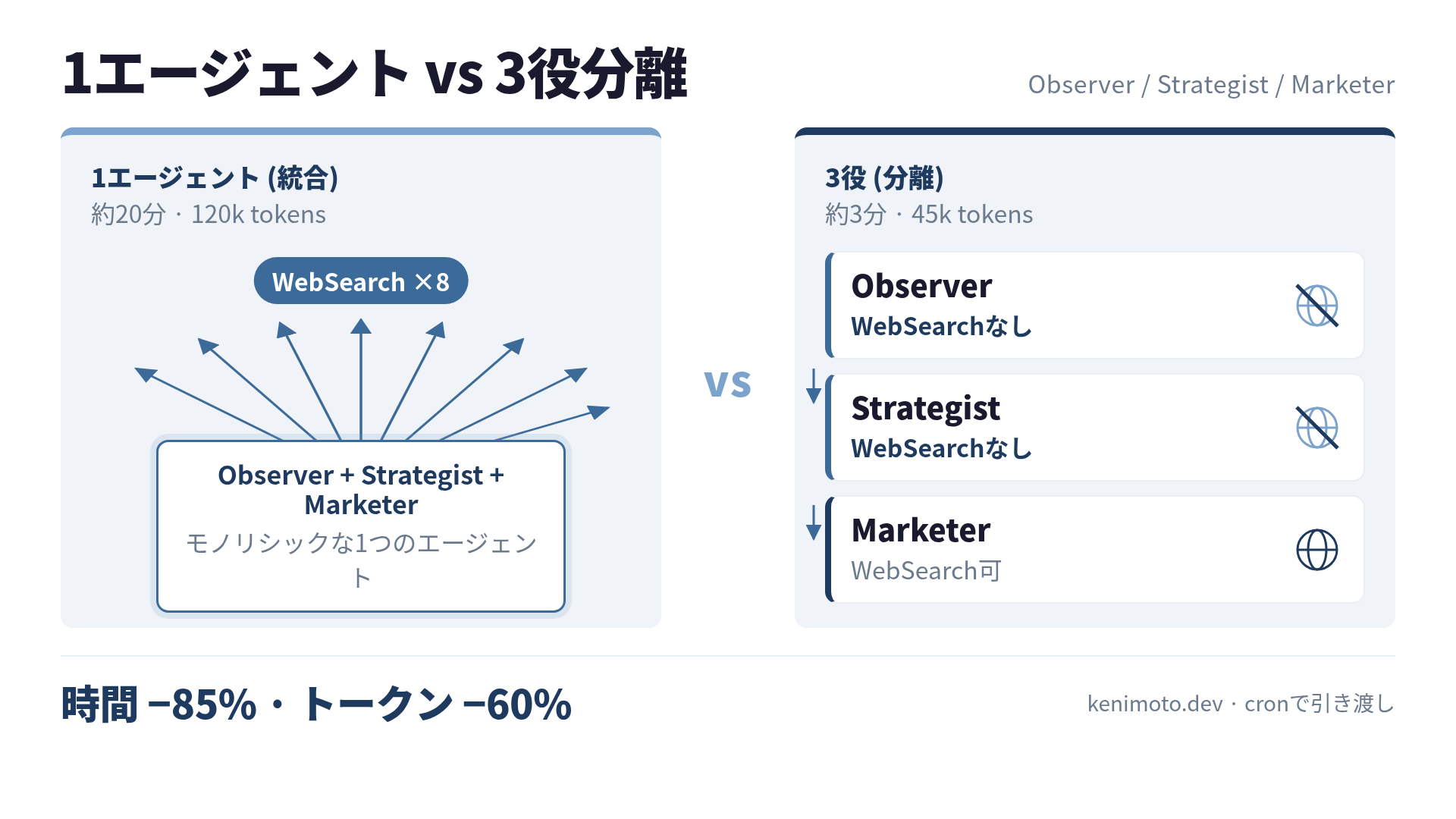
20分かかっていた1エージェント構成
最初の構成は1プロンプト・1エージェント・1ラン。
「昨日のGA4データを見て、今日のテーマを5つ選んで、優先度1位の記事を書いてくれ」
許可ツールは Bash, Read, Write, Edit, Grep, Glob, WebSearch, WebFetch をフル開放。必要そうなものは全部入れていました。
エージェントは各候補テーマについて似たような動きをします。「このジャンルで今ホットな話題は」とWebSearch、「このトレンドの裏取り」でWebSearch、「競合の最近の言及」でまたWebSearch。5テーマ × 3-4回の検索で、1回の実行に15-20回のWebSearchが入る計算です。検索結果はそれぞれ数千トークンを判断コンテキストに積み上げます。
テーマ3を選んでいる頃には、判断コンテキストに4万トークン以上のWebSearch結果が積み上がっています。シグナル対ノイズ比が崩壊します。エージェントは「自分のコンテンツ資産に合ったテーマ」ではなく「最近のニュースで確認できたテーマ」を選び始めました。
表面に出た症状は時間です。1ランあたり約20分。隠れた症状は判断ブレでした。私は週次レビューでエージェントの選定をしょっちゅう上書きしていました。書く素材を持っていないテーマばかり選んでくるからです。
なぜ判断ループにWebSearchを混ぜると壊れるのか
WebSearchそのものは悪くありません。判断ループに混ぜるのが罠です。
判断役にWebSearchを持たせると、2つのことが起きます。
時間: WebSearch 1回は 5-20秒。5テーマ × 4回 = 20回。検索だけで合計100秒以上が消えます。人間が手で1質問するなら誤差ですが、毎日走る自動ジョブだとここが効いてきます。
コンテキスト汚染: 1検索結果は2,000-5,000トークンのHTMLスクレイピング済みページテキストを判断コンテキストに突っ込みます。SEO向けに最適化されたマーケコピーの山で、「このテーマは自分のコンテンツに合うか?」という判断には設計されていません。判断役は「自分のデータ」ではなく「マーケコピーの山」から推論するハメになります。
直し方は地味です。判断役にWebSearchを持たせない。WebSearchは執筆役の持ち物にする。
Role 1: Observer - 集めるだけ
Observerの仕事は「昨日の数字を取ってきてファイルに書く」これだけです。
入力: GA4、Zenn API、Dev.to API、前日のログ。出力: domains/<name>/data/snapshot-YYYY-MM-DD.json。
許可ツール設定:
claude -p "$(cat scripts/prompts/observer-prompt.txt)" \
--allowed-tools "Bash,Read,Write"WebSearchなし、WebFetchなし、Editもなし。Observerは curl で3つのAPIを叩いて、1つのJSONファイルを書く。それだけです。「データを解釈しよう」と気を利かせ始めても、プロンプトで禁じています。スキーマでも縛っています。フィールドは total_views、top_performers_3、errors_yesterday。recommendation フィールドは存在しないので、判断を書こうとしても置く場所がありません。
ダウングレードに見えるかもしれません。実際そうです。神オブジェクトを単機能関数に分割するのと同じ意味でのダウングレードです。Observerが落ちたら、どのAPIが壊れたか即わかります。それしかやっていないので。
Role 2: Strategist - 判断するだけ、WebSearchなし
StrategistはObserverが書いたsnapshotを読み、strategy.md のルールを読み、過去30日の公開テーマを除外リストとして読み、5テーマを決めます。以上。
claude -p "$(cat scripts/prompts/strategist-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob"抜けているものに注目してください。WebSearch、WebFetch がない。物理的に許可ツールから外しています。Strategist は外部にアクセスする手段がありません。
ここは私も最後まで抵抗しました。「最新トレンドを見ないでどうやって今日のテーマを判断するんだ」。これは問いが間違っていました。正しい問いは「自分は他所でバズっているテーマを書くのか、自分のコンテンツ資産に合うテーマを書くのか」です。
Strategistが見るもの:
- 3ヶ月分の自分のパフォーマンスデータ (何が読まれたか)
- 自分のコンテンツ資産 (Book章、未公開ドラフト)
- 30日除外リスト (何を書いたか)
- 自分の
strategy.md
これだけあれば5テーマを90秒で選べます。20分ではありません。Strategist 1ランあたりのトークン消費は約8万から約2万に下がりました。読むWebSearch結果がないからです。
「WebSearchで根拠を増やす」は良いアイデアに聞こえました。実際に起きたのは、8回の冗長な検索と4万トークンのノイズの追加でした。
Role 3: Marketer - 実行する、WebSearchはここ
MarketerはStrategistの判断ログを読み、優先度1位のテーマを取り、記事を書きます。WebSearchが出てくるのはここです。
claude -p "$(cat scripts/prompts/marketer-prompt.txt)" \
--allowed-tools "Bash,Read,Write,Edit,Grep,Glob,WebSearch,WebFetch"Marketer のWebSearchは「執筆中の調査」用です。
- 「LangGraph の2026年安定版バージョン」
- 「Anthropic の Building Effective Agents 公式URL」
- 「Inngest のcronトリガー料金プラン」
これは引用と裏取りであって判断ではありません。「このテーマを書くか」はもう決まっています。Marketer のWebSearchは目の前の記事の範囲に閉じています。
ここから2つの副作用が出ます。
- コストが局所化する: WebSearch 課金は Marketer の中で発生し、目に見える成果物 (記事) を生みます。Strategist の1ランあたりコストは小さくなったので、週に複数回回しても気になりません。
- 失敗が局所化する: WebSearch が不調や障害のときに壊れるのは Marketer (書く役) だけです。Strategist は今日の判断を出します。Observer は昨日の数字を記録します。パイプラインは劣化はしても止まりません。
cronチェーン - 3役はどう繋がるか
3役は会話履歴で繋がりません。ファイルで繋がります。
07:00 Observer → snapshot-2026-05-14.json を書く
09:00 Strategist → snapshot を読み、strategist-2026-05-14.md を書く
10:00 Marketer → strategist.md を読み、下書き + 22:00 公開予約
22:00 Observer → 今日の初動を記録 → 明日のインプットこれを私はVPS上の素のcronで回しています。crontab全文はharness-engineering-guide 第11章に載せていますが、要点は1ジョブ1行、set -euo pipefail、trap ... ERR、Telegram失敗通知、ロックファイル。1役あたりシェル約30行です。
cronより耐久性が欲しいなら、Temporal Schedules、Inngest のcronトリガー、GitHub Actions cron のどれも同じ形に乗ります。アーキテクチャはどれを使うかには無関心です。私がcronなのは「サーバーが落ちたら気付く」という失敗モードで運用したいからです。
引き継ぎは常にファイル。snapshot は JSON、strategist ログは Markdown、marketer ログも Markdown。人間も読める、日付付き、再実行可能。環境変数を1つ変えれば昨日の Marketer を昨日の Strategist ファイルに対して再走できます。Airflow を導入しなくても backfill が自然に手に入ります。
Sub-agent との違い
私は別の記事でClaude Code の Sub-agent 3つに同じPRをレビューさせたら41%意見が分かれた話を書いています。「Sub-agent と3役分離って同じことじゃないの?」と聞かれることがありますが、別物です。
スライドだと似て見えますが、実運用ではまったく違う振る舞いをします。
| Sub-agent (Claude Code Task tool) | 3役分離 (cron) | |
|---|---|---|
| スコープ | 同一セッション、親エージェント配下 | 3プロセス、3ラン独立 |
| 状態 | 親が文脈を引き渡す | ディスク上のファイル |
| タイミング | 同期、親が待つ | 非同期、数時間空く |
| 失敗時 | 親がリトライ責任を持つ | 各ジョブが独立リトライ |
| 用途 | 「このコードベースを並列探索」 | 「昨日のPDCAを毎朝回す」 |
Sub-agent は1タスク内の並列性のための仕組みです。3役分離は時間をまたいだパイプラインのための仕組みです。混ぜると両方の最悪が出ます。cronのデバッグ難易度に、Sub-agentの共有コンテキストドリフトが上乗せされます。
私が使っている判定基準: 同じ会話内で答えを返したいなら Sub-agent。サーバー再起動を挟んでも生き残らせたいなら cron で別ジョブ。
実測値
同じコンテンツスタックで両方の構成を回した実測です。
| 指標 | 1エージェント | 3役分離 | 変化 |
|---|---|---|---|
| 5テーマ選定時間 | 約20分 | 約3分 | -85% |
| 1日分のトークン | 約12万 | 約4.5万 | -62% |
| 月額API料金 | 約$60 | 約$22 | -63% |
| 週次再判定回数 | 週2-3回 | 週0-1回 | 減 |
| WebSearch障害でパイプ停止 | あり | なし | 解消 |
| 失敗時の平均デバッグ時間 | 30-60分 | 5-10分 | -80% |
意外だったのはトークンの計算でした。3エージェントに分けたらコンテキスト重複でトークンは増えると思っていました。実際は減りました。消えたWebSearch トラフィックが、役ごとに増えるオーバーヘッドより大きかったからです。
日々効くのはデバッグ時間です。1エージェント構成の「09
」では何も分かりません。3役構成の「09」なら、読むべき30行のスクリプトが確定します。「エージェントを増やしたら速くなった」は直感に反します。本当は、増やしたから速くなったのではなく、判断役からWebSearchを取り上げたから速くなったのです。3役に分けたのは、それを物理的に強制できる構造を作るためでした。Observer と Strategist が外部にアクセスできなくなった瞬間、「もう1回だけ検索してみよう」という誘惑が消えました。
関連記事: 自然言語エージェントハーネス (arxiv論文の整理)(英語版)でハーネスの概念を、本記事で実装パターンを書いています。crontab全文・プロンプトファイル・各役の許可ツール設定の完全版は Harness Engineering: AIを使うから、AIを統べるへ にまとめています。
この記事は役に立ちましたか?