AIエージェントを7本cronで毎日回したら、2本が18日間沈黙していた — observabilityでは拾えず、exit-code契約で拾えた話
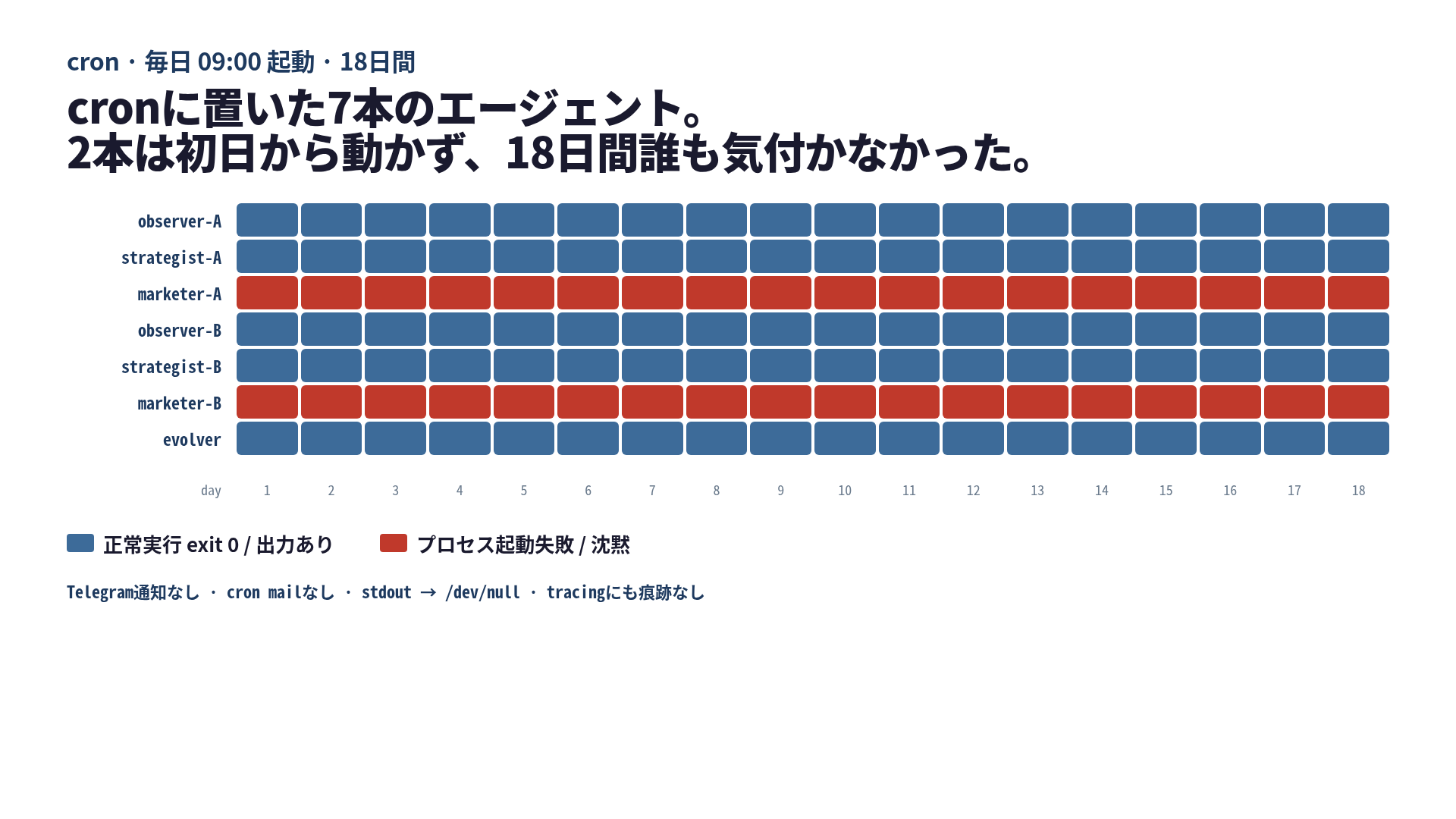
私はcronに7本のAIエージェントを置いていました。そのうち2本が初日から動いていませんでした。気付いたのは18日後です。
この一文で記事は終わるのですが、もし他の誰かがポッドキャストで同じことを言っていたら、私は反論していたと思います。「いやさすがに18日も気付かないわけない。tracingあるし、ダッシュボードあるし、Telegramで何かあれば通知来るでしょう」と。はい、それ全部ありました。それでもこの2本はすり抜けました。理由は単純で、私の監視レイヤは全部「動いているプロセス」を見ていたからです。動いていない2本は、どこにも映っていませんでした。
これは18日間のログです。何を7本動かしていて、どこで2本が静かに死んだか、なぜtracingでは拾えなかったか、そして今は全部のスケジュール実行エージェントに付けている小さなexit-code契約の話です。
7本のエージェントと「問題なさそうに見えた」セットアップ
私は同じサーバ上で2つのコンテンツドメインと1つのself-evolving harnessを回しています。各ドメインにObserver / Strategist / Marketerの3本、それと共通のEvolverが1本。これで合計7本。cronはだいたい次のような書き方でした。
0 9 * * * /home/me/repos/harness-ops/scripts/marketer-A.sh >/dev/null 2>&1
0 9 * * * /home/me/repos/harness-ops/scripts/marketer-B.sh >/dev/null 2>&1それぞれのshell scriptは claude -p "..." をヒアドキュメント付きで呼び、出力をキャプチャして日次ログを書き、エージェントが「公開する」と判断した場合は記事を実際にpushして終わります。Telegram通知用のwebhookも仕込んであって、成功時にも set -e で死んだときにも飛ぶ、はずでした。この構成で2ヶ月ほど運用していました。
セットアップしたときに見落としていたのは、heredocの3行下です。Marketer 2本は別リポジトリにあるPythonヘルパーを呼んでいました。当時はそのリポジトリにcdしてシェルから動作確認していて、確かに通っていたのでチェックインしました。その後、別リポジトリ側を整理する流れでヘルパーのモジュール名を変えました。Marketer側の import 行は古い名前のまま、誰にも気付かれずに残りました。
ここから先はもう察しがつくと思います。python3 helper.py ... は ModuleNotFoundError で即座に exit 1。スクリプトの先頭は set -euo pipefail。10行目あたりで死にます。Telegram通知のブロックはもっと下、Python呼び出しの後ろ側に書いてあったので、そこまで到達しません。>/dev/null 2>&1 でstderrは消えます。cronは MAILTO= を設定していません。毎朝、2本のエージェントが静かに死に、残り5本は普通に記事を公開していました。システム全体は健康に見えていました。
tracingが見ていたもの、見ていなかったもの
ここは正確に書きたいところです。なぜなら18日目の朝、私は数時間かけて「もっとちゃんとしたtracingを入れていれば拾えたんじゃないか」と自分に言い聞かせようとしたからです。結論を先に言うと、ちゃんとしたtracingでも拾えませんでした。
claude -p の呼び出しからは OTEL のspanを吐かせていて、self-hosted collectorに集めて小さなダッシュボードに表示していました。token消費、tool-call latency、retry率、日次の総エージェント実行数。18日目の朝、ダッシュボードを見ると、日次の総実行数は18日連続でぴたっと「5」を指していました。本来は「7」のはずです。
tracingは「実行されたプロセス」を計測する仕組みです。遅い呼び出し、失敗した呼び出し、retryの嵐、そういうものは映ります。しかし「そもそも起動しなかったプロセス」は映りません。死んだ2本のMarketerは span を1本も吐いていませんでした。なぜなら、span を吐かせる場所が「import に失敗した当のヘルパー」の中だったからです。ダッシュボードから見れば、その2本は「今日存在しなかった」のと同じです。次の日も、その次の日も、ずっと存在しなかったことになっていました。
私はずっと間違った質問を見ていました。「動いているエージェントは元気か?」はtracingが答えられる質問です。「スケジュールされた7本のうち、本当に7本動いたか?」はtracingが答えられない質問です。動かなかった2本は、その「動かなかった」という事実そのものを誰にも報告できないからです。
healthchecks.ioのdead man’s switchの説明ページを読んだことがある人にはおなじみのはずです。「重要なデータ処理ジョブが、従来の監視システムに何の警報も上げずに停止することがある。サイレント失敗は、欠損データや破損結果に誰かが気付くまで、何日も何週間も続きうる」と書いてあります。私はあのページを以前読んでいました。ただ、自分のcronには適用しませんでした。Telegram通知があるから大丈夫と思っていたからです。Telegramは「スクリプトが到達した行」からしか飛びません。

後付けで入れたexit-code契約
直し方は「もっとobservabilityを増やす」ではありませんでした。エージェント自身に「自分の生死を報告してもらう」ことを諦めて、cron wrapper側に「エージェントの代わりに報告する責任」を持たせる方向です。スケジュール実行する全エージェントに、次の小さな契約を結ばせました。
- 意味のあるexit codeを定義する。 「0 = OK、それ以外 = NG」ではなく、もう少し細かく。sysexits.h を緩めに踏襲しました。
0は「エージェントが走って仕事を終えた」、64は「config/環境エラー」(まさにModuleNotFoundErrorのパターン)、65は「走ったが使える出力が得られなかった」、78は「意図的にスキップ」(Marketerが「今日は公開する記事なし」と判断したケース)。 - cron wrapperが報告を持つ。 エージェントスクリプトの仕事は「正しいexit codeで終わる」ことだけ。wrapperの仕事はその exit code を拾って、どこか永続的な場所に push すること。エージェントが成功しようが失敗しようが関係なく。
- 成功時にもheartbeatを飛ばす。 失敗時だけではなく成功時にも飛ばす。沈黙そのものをアラームにする。
cron wrapperはだいたいこんな形に落ち着きました。
#!/usr/bin/env bash
# scripts/cron-wrap.sh <agent-name>
set -uo pipefail
AGENT="$1"
SCRIPT="$HOME/repos/harness-ops/scripts/${AGENT}.sh"
HC_URL="https://hc-ping.com/<uuid-${AGENT}>"
START=$(date -Iseconds)
bash "$SCRIPT"
RC=$?
END=$(date -Iseconds)
# 成否によらず1行ずつログを残す
echo "${START} ${AGENT} rc=${RC} end=${END}" >> "$HOME/logs/cron-runs.log"
# exit codeをURLパスに埋めてpingする
# 24h ping切れ → healthchecks.io が私を呼ぶ
curl -fsS --retry 3 "${HC_URL}/${RC}" >/dev/null || true
# 非ゼロのみ即時escalate (78は意図スキップなので除外)
if [[ "$RC" -ne 0 && "$RC" -ne 78 ]]; then
"$HOME/bin/tg-notify.sh" "agent=${AGENT} rc=${RC} see ~/logs/cron-runs.log"
fi
exit 0このwrapperには、書き直すたびに少しずつ詰まったポイントが3つあります。
1つ目は set -euo pipefail ではなく set -uo pipefail にしたこと。エージェントスクリプトが失敗してwrapperごと死んでしまうと、pingに到達しないからです。pingに到達しなければhealthchecks.io側は「24時間後に呼ぶ」モードになりますが、それでは遅すぎます。wrapperは死なずに最後まで走り切って exit code を拾う必要があります。
2つ目はpingのURLにexit codeを埋めたこと。healthchecks.ioもCronitorも、URLの末尾に code を載せると最終exit codeをダッシュボードに残してくれます。なので、ログファイルを開かずに「Aは exit 64 だった」がひと目で分かります。
3つ目は 78 を意図的なスキップとして扱ったこと。Marketerが「今日は公開する記事がない」と判断して終わるケースは失敗ではないので、escalateしません。これをやらないと「今日は静かな日でしたよ」のたびにTelegramが鳴って、私が通知をミュートし始めて、結局運用が破綻します。アラート疲れで運用が死ぬのは、観測が死ぬよりよくある現象です。
入れた当日に拾えたもの
このwrapperを入れたのが、ちょうどMarketerたちが18日目に突入した朝でした。10分以内に marketer-A と marketer-B の両方がhealthchecks.ioのダッシュボードに「最終exit code: 64」で姿を現しました。中身のコードを開く前に、ダッシュボードでひと目で分かりました。
1時間以内に、importを直して、両方のスクリプトを手で走らせて exit 0 を確認、翌朝のcronで2本のMarketerが2週間半サボっていた記事を実際に公開し始めました。tracing側の日次実行数も「7」に戻りました。線はまだ平らですが、平らになっている値が正しい値です。
その翌日には、18日間ずっと健康だったはずのobserver-Bが exit 65 (「使える出力が得られなかった」) を返し始めました。ダッシュボードに反映されるまで20分。これがexit-code契約の本来の役割です。エージェントは動いたけれど出力がゴミだった、というケースを、2週間後ではなく当日に拾えます。
過去の自分に言うとしたら
2ヶ月前にこのcronを置いた自分は、別に怠けていたわけではありません。Telegram通知も、tracingダッシュボードも、日次ログも揃えてありました。Twelve-Factor App の disposability の章も読んでいました。「エージェントが失敗する」のと「エージェントがそもそも動かない」の違いについても考えていて、後者は十分まれだから無視していい、と判断していました。
ミスは「動かない」をレアケース扱いしたところでした。7本のスケジュール実行、3本のPythonヘルパー、独立に動く2本のリポジトリ、スクリプトの中盤にTelegram通知を仕込んでいるという構成では、「そもそも動かなかった」が最頻のサイレント失敗モードです。他の失敗よりも一桁以上多いと思います。
なので、過去の自分に言うとしたらコストの低い順に3つ。
MAILTO=はタダ。 cronにMAILTO=your-mail@example.comを1行足すだけで、ジョブのstderrが自動でメール送付されます。アラート用コードに到達する前に死んだジョブでも届きます。これだけで私の18日間は1日目に終わっていました。systemd timerに移行している場合は archwikiの systemd timer のページ にOnFailure=での通知パターンがまとまっています。- エージェントごとに自分が所有するwrapperを噛ませる。 エージェント本体に詰め込まない。wrapperの仕事は「exit codeを拾う」「pingする」だけ。エージェントよりも汚い書き方になってかまわないので、代わりに今後ほとんど変更しないようにする。
- 沈黙を「うるさく」させる仕組みは success heartbeat。 失敗通知はどこにでもあるけれど、「そもそも動かなかったエージェント」については何も教えてくれません。成功時にpingを飛ばして、ping切れで呼び出されるdead man’s switchを置く。これが「2本が静かに死んでいる」を18日問題から1日問題に変えます。
なお、kenimoto.devでも書いた Claude Code Hooks v2 — 25のライフサイクルイベントの記事はエージェントが起動した「あとの」話なので、本記事の「そもそも起動しなかった」とは別レイヤを扱っています。Hookが発火する前提が崩れたときに何が起きるか、というのが今日の話でした。
tracingとobservabilityは、生きているプロセスを見るための道具です。exit-code契約は、そもそも生きているべきだったことを記録するための道具です。両方が必要で、cronの「set it and forget it」運用は後者がないと簡単に崩れます。私のは18日間崩れていて、私は毎朝そのサーバのダッシュボードを見ていました。
ダッシュボードは健康でした。ダッシュボードが見ていた質問のほうが、間違っていただけです。
まとめ
- cronに置いた7本のエージェントのうち2本が、初日から
ModuleNotFoundErrorで死に、18日間誰にも気付かれなかった - tracingは「実行されたプロセス」を見る仕組みなので、「起動しなかったプロセス」は構造的に拾えない
- 解決はexit-code契約(
0/64/65/78)とcron wrapperが代理で報告する仕組み、それと「成功時のheartbeat + dead man’s switch」の3点セット - 一番安いのは
MAILTO=を1行足すこと。これだけで多くのサイレント失敗は当日中に拾える
関連
- Claude Codeを3セッション並列で8時間動かしたら、2回コンテキストを上書きしていた話 — 同時並列セッション側の事故。「衝突」と「沈黙」で対の関係。
- 他のエージェントを監査する4層目を足したら、Strategistが3週間サボっていた — 動いてはいるが procrastinate しているエージェントを上位層で監査する話。本記事のexit-code契約とレイヤが違う。
ハーネス全体のhooks / ライフサイクル / フィードバックループの章を含めて、本格的に読みたい方はこちらにまとめてあります: Harness Engineering Guide: ツールから複利的生産性へ。
この記事は役に立ちましたか?