43秒の異常が24時間の障害になった: メトリクスの急変と漸増を見分ける時系列デバッグ
障害対応で私が最初にやらかすのは、たいてい「目に見えている異常」に飛びついてしまうことです。レスポンスが遅い、というアラートが鳴った瞬間、ロードバランサのCPUを疑い、アプリのスレッドダンプを取り、データベースのスロークエリを眺める。30分かけて何も見つからず、ようやくダッシュボードの表示期間を1時間から1週間に広げて、3日前から静かに右肩上がりだったメモリ使用量に気づく。原因はそこにありました。
この遠回りは、ほぼ全部「グラフの形を読まずに数字だけ追った」ことが原因でした。今日はその話を書きます。
たった43秒が24時間に化けた日
数字を1つ置きます。43秒。これは2018年10月21日にGitHubで起きたネットワーク分断の時間です。US East Coastのネットワーク機器の交換作業で、2つのデータセンター間の接続が43秒だけ切れました。通常ならフェイルオーバーが処理して、ユーザーは気づきもしない長さです。
ところがこの43秒のあいだに、両方のデータセンターが独立してデータベースへの書き込みを受け付けてしまいました。いわゆるスプリットブレインです。ネットワークが復旧したあとも、矛盾する書き込みを安全に統合する作業が残り、GitHubの全面復旧には24時間11分かかりました(復旧途中の段階では「24時間5分」という数字も報告されています)。43秒が24時間に化けた。倍率にしておよそ2,000倍です。
ここで効いたのが、タイムラインの正確な再構成でした。「どちらのデータセンターが先に書き込みを受け付けたか」を秒単位で確定できなければ、安全な統合手順そのものが組めません。障害の規模は43秒では決まらず、その43秒を起点に何が連鎖したかで決まりました。時系列を読む力が、復旧速度を直接左右したわけです。
システムのメトリクスは心電図だ
ここで一度たとえ話をさせてください。私はメトリクスのダッシュボードを心電図(EKG)だと思って見ています。健康な心臓には固有のリズムがあって、医師は波形の乱れから異常を読み取ります。システムのメトリクスもまったく同じで、正常なときには正常なリズムがあり、そこからの逸脱が障害の兆候になります。
差分(何が変わったか)が「犯人は誰か」を問うのに対して、時系列分析は「いつ、どんな形で容体が変わったか」を問います。そしてこの「どんな形で」の部分が、原因の性質をかなり正直に教えてくれます。波形を読めれば、聴診器を当てる場所がぐっと絞れるのです。
急変と漸増: 形が原因の種類を教える
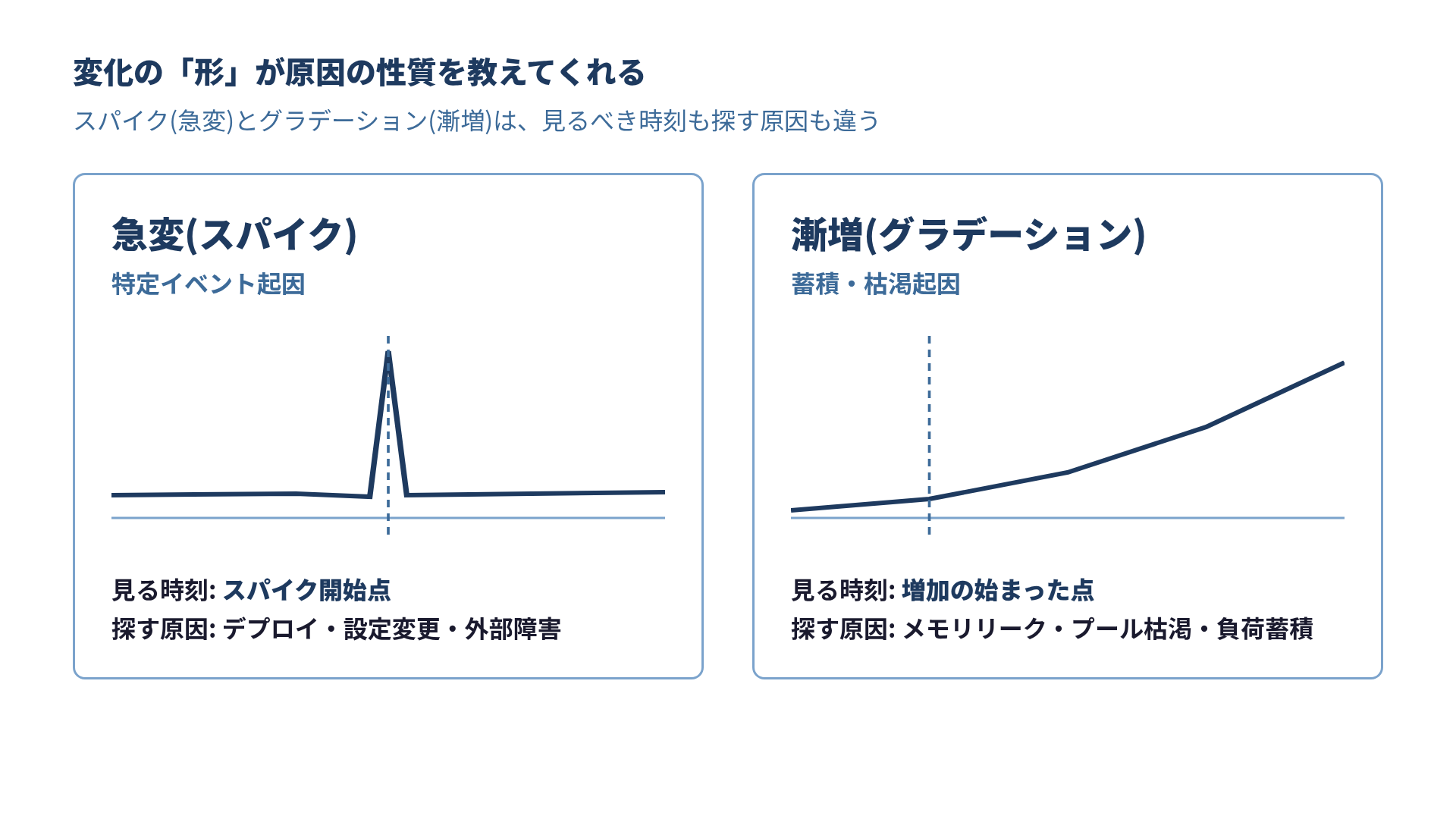
メトリクスの変化は、大きく2つの形に分かれます。
急変(スパイク) は、グラフが突然跳ね上がる、あるいは急降下する形です。これは「特定のイベントが起きた」ことを示しています。デプロイ直後にエラーレートが跳ねる。設定変更の直後にレイテンシが急増する。外部サービスが落ちて接続エラーが一気に増える。スパイクの場合、スパイクの開始時刻がそのまま原因の発生時刻を指します。その瞬間に何が起きたかを調べれば、かなりの確率で原因に届きます。GitHubの事例なら、ネットワーク分断が始まった時刻が、すべての異常の起点でした。
漸増(グラデーション) は、メトリクスがゆっくり悪化していく形です。これはリソースの枯渇や負荷の蓄積を示しています。メモリ使用量が数日かけて100%に近づく。コネクションプールの使用率がじわじわ上がる。ディスクが毎日数GBずつ埋まる。レスポンスタイムが週単位で重くなる。こちらで見るべきは「いつ閾値を超えたか」ではなく「いつから増え始めたか」です。その増加の始点に、コードの変更やトラフィックパターンの変化が必ず潜んでいます。
冒頭で私が30分溶かしたのは、漸増を急変だと思い込んでスパイクの瞬間を探し続けたからでした。心電図でいえば、健康診断の数値が3日前から悪化していたのに、今朝の不整脈だけを探していたようなものです。
3つの時間スケールで見ないと初期異常を見逃す
この急変と漸増の見分けが厄介なのは、表示期間によって同じグラフがまったく違う顔をするからです。
障害の5分前から見ると鋭い急変に見えるものが、1週間で引いて見ると漸増の最後の局面だった、ということが普通に起きます。逆に、長い期間では平坦に潰れて見える微小な変化が、短い期間にズームすると初期の異常として浮かび上がることもあります。心電図を1拍だけ見ても不整脈の周期はわからないのと同じです。
なので私は、最低でも3つのスケールで見るようにしています。直近1時間、直近24時間、直近1週間。1時間で「今まさに何が暴れているか」を、24時間で「今日のうちに何かが変わったか」を、1週間で「ベースラインからどうずれたか」を読みます。このうち1つでも飛ばすと、初期異常を取りこぼします。私が3日前のメモリ漸増を見逃したのは、1時間スケールしか見ていなかったからでした。
ベースラインを知っておくことも前提になります。CPU 80%が異常なのか、それとも毎日昼過ぎに80%まで上がるのが平常運転なのかは、平常時の波形を知らなければ判断できません。曜日や時間帯のパターンを頭に入れておくと、「これはいつもの山」「これは違う」の判断が一瞬で済みます。
最初に目に入る異常は、最初の異常ではない

時系列デバッグでいちばん難しく、いちばん効くのが「最初の異常」を見つけることです。ここでいう最初の異常とは、ユーザーに影響が出た時刻ではなく、システム内部で最初に数値が動いた時刻のことです。
2025年11月18日のCloudflare障害が、わかりやすい例です。発端はClickHouseクラスタの権限変更で、これが入ったのが11時05分(UTC)。ところがユーザー向けのレスポンス劣化が始まったのは11時28分でした。あいだに23分の空白があります。
この23分のあいだに何が起きていたか。権限変更によって、ある内部クエリが重複した行を返すようになり、Bot Management用の特徴ファイルのサイズが倍に膨れました。その肥大化したファイルが世界中のプロキシへ伝播し、各プロキシのメモリ上限を超えてクラッシュを引き起こし、そこで初めてユーザーから見えるレスポンス劣化になりました。障害は11時28分から17時06分まで、5時間38分続きました。
ここに罠があります。アラートが鳴った11時28分から調査を始めると、最初に目に入るのはプロキシのクラッシュです。プロキシのメモリを増やそう、再起動しよう、と手を打ちたくなります。でも本当の起点は23分前の権限変更でした。複数のレイヤーでバッファリングが起きると、原因と症状は時間的にずれます。「目に入った異常」を起点に対処すると、症状を追いかけ続けることになります。
最初の異常を起点に置けると、調査の地図が一気に書き換わります。23分前まで遡れたかどうかが、初速を分けたわけです。
相関と因果のあいだに時刻ずれを挟まない
ただし、ここで足元をすくわれることがあります。複数のメトリクスを同じ時間軸に重ねて「レイテンシのスパイクとCPUのスパイクが同時刻だからCPU起因だ」と読むのは強力な手筋ですが、その「同時刻」が本当に同時刻である保証は、案外もろいのです。
分散システムでは、サーバーごとに時計が少しずつずれています。NTPで全サーバーの時刻を同期させておかないと、数秒のずれでイベントの前後関係が逆転して見えます。原因のログが結果のログより後ろに記録されていたら、人間の脳は素直に因果を取り違えます。GitHubの事例で2つのデータセンターのイベントを突き合わせられたのも、正確なタイムスタンプがあったからでした。
時刻基準を揃える前提は3つあります。NTPで時計を合わせること。ログのタイムスタンプ形式を統一すること(あるサービスはUTC、別のサービスはJST、さらに別のサービスはUnixエポック秒、では突き合わせに余計な時間がかかります)。そして問題の粒度に合った解像度を持つこと(秒単位のメトリクスではミリ秒の因果は見えません)。
サービスを横断して時刻と因果をつなぐ標準的な道具が、分散トレーシングです。W3Cの Trace Context は、traceparent という共通フォーマットのHTTPヘッダで、リクエストがサービス間を渡り歩いても同じトレースIDで追えるようにする仕様です。2025年時点で Level 2 が Candidate Recommendation の段階まで進み、トレースIDの乱数性を示すフラグが追加されるなど、相関の信頼性を上げる方向で改訂が続いています。手元の時計を合わせるのがNTPなら、リクエストの旅路に共通のIDを持たせるのがトレーシングです。両方そろって初めて、別々のサービスのログを安心して同じ時間軸に並べられます。
それでも、時系列分析が見つけてくれるのはあくまで相関です。デプロイ直後にエラーが増えたとして、たまたま同じタイミングで外部サービスが落ちていた可能性は消えません。相関を因果に昇格させるには、ロールバックして実際にエラーが消えるか、設定を戻して回復するかを確かめる、再現の一手が要ります。とはいえ、時系列上の相関は因果を確定する前のフィルタとしては最も有力な手がかりです。
なお、原因が人間でもAIでもない「コードそのものが嘘をつく」タイプのバグについては、別の軸でClaudeがバグを隠す10の技法に書きました。あちらはAIが生成したコードに潜む欺瞞の話で、今日の時系列観測の技法とはレイヤーが違いますが、合わせて読むと「観測でわかること」と「観測の外で起きること」の境界が見えると思います。
まとめ
障害対応の初速は、グラフの形を読めるかどうかでだいたい決まります。
- 急変(スパイク)はイベント起因、スパイクの開始時刻が原因の時刻を指す
- 漸増(グラデーション)は蓄積・枯渇起因、増加の始点を探す
- 直近1時間・24時間・1週間の3スケールで見る。1つ飛ばすと初期異常を見逃す
- 「最初の異常」はユーザー影響時刻ではなく、システム内部で最初に数値が動いた時刻
- 相関を因果と取り違えないために、NTP同期・タイムスタンプ統一・トレース相関で時刻基準を揃える
メトリクスは嘘をつきません。でも、読み手が正しい問いを持っていなければ、ただの折れ線として黙ったままです。今日のいちばんの教訓は、私のように30分溶かす前に、まず表示期間を1週間に広げてみることです。
この記事は役に立ちましたか?