AIエージェントの予測を1つの数字で信じるな — Simulatorは点推定でなく確率分布を返すべき
私は以前、自作の事業運営エージェントに広告施策の結果を予測させて、その出力を真顔で信じていました。「この施策のCACは2,000円です」。おお、2,000円か。じゃあこれでいこう。実際に回したらCACは3,400円でした。エージェントが嘘をついたわけではありません。私が、1つの数字を信じてしまっただけです。
問題は予測精度ではなく、出力の形でした。エージェントは「2,000円」と点推定で答え、私はそれを確定した未来として受け取った。そこに不確実性の幅はどこにもなかったのです。
この記事は、事業運営の自律エージェント(以下Simulator)の出力を「点推定」から「確率分布」に変えると意思決定がどう変わるか、という話です。結論から言うと、Simulatorが1つの数字を返した瞬間、後続の意思決定エージェントは確実に過信します。そして過信した意思決定は、平均的には正しくても、尾部で壊れます。
点推定が嘘になる瞬間
まず言葉を整理します。Simulatorは、戦略候補を入力に受け取り、過去データから予測される結果を返すモジュールです。「予算Xをチャネル配分Yで投下したらCACはどうなるか」を、実弾を撃つ前に推定する。実際に試せば確実にわかるけれど、試すまでに時間と金がかかる。その手前で候補を10個から3個に絞るために使います。
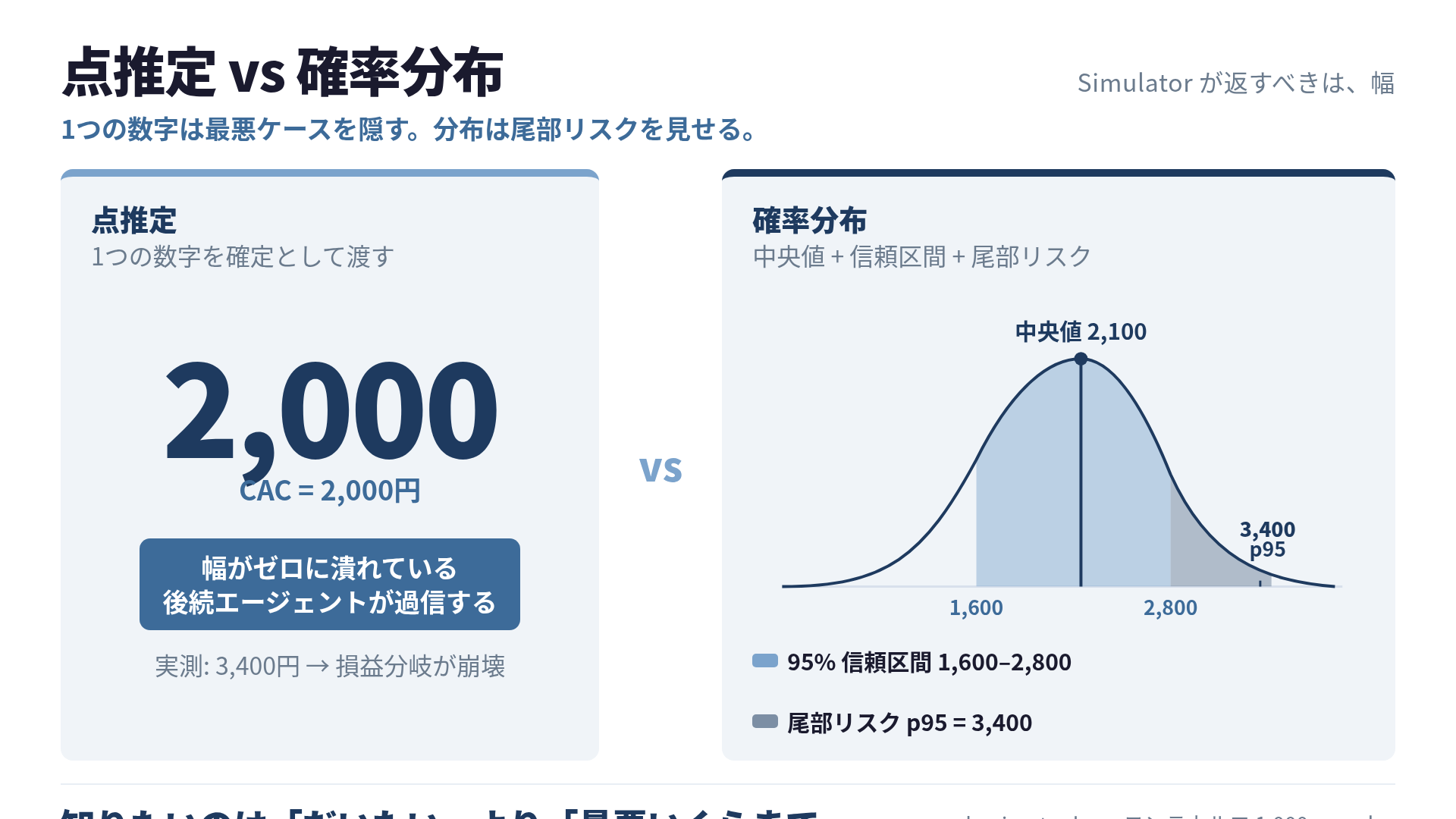
このSimulatorの出力が「CAC=2,000円」という1つの数字だったとします。これは厳密には嘘です。正確には「中央値は2,000円付近だが、1,500円から3,000円のどこかに着地する確率が高く、まれに3,400円まで跳ねる」が真実だからです。点推定はこの幅をゼロに潰して、確率1で2,000円だと言い切っている。エージェントが嘘をつくつもりがなくても、出力の形式が嘘をつかせるわけです。
ここで「いやでも中央値2,000円なら平均的には合ってるじゃん」と思うかもしれません。私もそう思っていました。罠はここにあります。意思決定は平均値の上で行われるのではなく、最悪ケースの上で破綻するからです。
過信する後続エージェント
Simulatorの出力を受け取って実際に判断を下すのは、後続の意思決定エージェント(Strategist)です。私のハーネスでは、Simulatorが候補を絞り、Strategistがその中から実行する施策を1つ選びます。役割を分けている理由は別記事に書きました。
問題は、点推定を受け取ったStrategistの振る舞いです。「CAC=2,000円」という入力を見たStrategistは、これを2,000円という事実として扱います。LLMは入力に書かれた数字を、書かれた確からしさのまま受け取る傾向があります。「2,000円」とだけ書いてあれば、それが2,000円である確率を勝手に高く見積もる。人間が査読の数字を信じすぎるのと同じです。
そして2,000円という前提で予算配分を決め、損益分岐を計算し、「この施策はGOです」と判断する。実際には3,400円に着地して、計算した損益分岐は吹き飛ぶ。Strategistは何も間違っていません。間違った前提を、間違っていない手つきで処理しただけです。ゴミを入れたらゴミが出る、の高級版ですね。
点推定の本当の罪は、不確実性を消すことではありません。隠すことです。幅は実在するのに、出力の形がそれを見えなくする。見えないリスクは、誰も避けられません。
分布で返すと何が変わるか
ではSimulatorに分布を返させます。同じ予測を、こう書き換えます。
{
"metric": "cac",
"median": 2100,
"ci_low": 1600,
"ci_high": 2800,
"p95": 3400,
"samples": 1000,
"model_scope": "marketing-v3 / 過去90日 / paid-social のみ"
}中央値2,100円、95%信頼区間が1,600円から2,800円、上側5%点(p95)は3,400円。これを受け取ったStrategistは、もう「2,000円」とだけ言われたときの判断はできません。「中央値で見ればGOだが、p95の3,400円を踏むと損益分岐を割る」という条件付きの判断に変わります。最悪ケースが入力に明示されているので、最悪ケースを避ける判断ができる。
model_scope フィールドも効きます。この予測は過去90日のpaid-socialデータで訓練されたモデルが出したもので、メール施策やオーガニック流入には適用範囲外だと明示してある。Strategistが文脈外の予測を信じる事故を防げます。点推定にはこの注釈を貼る場所すらありませんでした。
分布の作り方は難しくありません。私はモンテカルロでサンプルを1,000本引いて、その分布から分位点を取り出しています。冒頭のCLIならこうです。
simulator predict --strategy=strategies/paid-social-q3.yaml \
--horizon=30d \
--samples=1000--samples=1000 で1,000本のシナリオを引き、その経験分布から中央値・信頼区間・p95を計算する。モデルの誤差が正規分布でなくても、サンプルを引いて分位点を取るだけなので素直です。分位点予測(quantile regression)で直接p50/p90を推定する手もありますし、近年は予測区間にキャリブレーション保証を付けるconformal predictionも使えます(Bui et al., AAAI 2024)。難易度の高い予測ほど区間が自動で広がる、という性質が後続の意思決定と相性がいい。
分布を渡しただけでは足りない、という不都合
ここで気持ちよく終わりたいのですが、不都合な研究を1つ置いておきます。「予測区間を渡せば意思決定の質が上がる」は、自動では成り立ちません。生産計画の被験者実験では、予測を区間で提示しても判断の質は改善せず、むしろ損失関数の非対称性への適切な反応をかえって鈍らせた、という報告があります(Goodwin et al., EJOR 2010)。区間を渡された人間が、それをうまく使えなかったわけです。
これはエージェントでも同じだと私は見ています。分布を入力したからStrategistが賢くなるのではありません。Strategistの判断ロジック側に「p95がこの閾値を超えたら除外」「信頼区間が中央値の何倍以上に広がったら実弾でなくA/Bテストに回す」といった、分布を消費する明示的なルールを書いて初めて効きます。データを渡すことと、データを使う意思決定設計は別物です。分布は前提条件であって、十分条件ではない。
私のワークフローでは、候補をランキングする段で「信頼区間が広すぎるものは除外する」というルールを明示的に置いています。広い区間は「Simulatorが自信を持てていない」というシグナルなので、そういう候補は実弾でなくA/Bテストという次の検証層に送る。速くて安いが仮定依存のSimulatorと、遅くて高価だがモデル非依存のA/Bテストを、不確実性の幅で振り分けるわけです。
まとめ
私は信長の野望を15年やっていて、布石を打つのが好きです。あのゲームで一番痛い負け方は、確実だと思った一手が外れたときではなく、外れる可能性を最初から見ていなかったときです。点推定は、まさにこの「外れる可能性を画面から消す」操作でした。
整理します。
- Simulatorが点推定で返すと、後続の意思決定エージェントは入力の数字を過信し、最悪ケースを避けられなくなる
- 出力を中央値・信頼区間・p95の分布にすると、Strategistは条件付きの判断ができ、尾部リスクを回避できる
- 分布の生成はモンテカルロのサンプリングと分位点抽出で十分実装できる。分位点予測やconformal predictionも選択肢
- ただし分布を渡すだけでは足りない。意思決定側に「区間が広ければA/Bテストに回す」等のルールを書いて初めて効く
1つの数字は便利です。便利だから信じてしまう。でも事業の意思決定で本当に知りたいのは「だいたいいくらか」ではなく「最悪いくらまで覚悟するか」です。次にあなたのエージェントが点推定を1つ返してきたら、こう聞いてみてください。「で、その数字、95%信頼区間はどこからどこ?」。黙ったら、まだ信じる段階じゃありません。面白くいきましょう。
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
この記事は役に立ちましたか?