Plugei o mesmo site em 7 rastreadores de citação por IA. Nenhum bateu com o outro.
Antes de pagar USD 200 por mês em qualquer rastreador de citação por IA, leia isso. Eu paguei. Sete vezes. Em paralelo, no mesmo site, na mesma janela de 15 dias. Os sete me responderam coisas completamente diferentes.
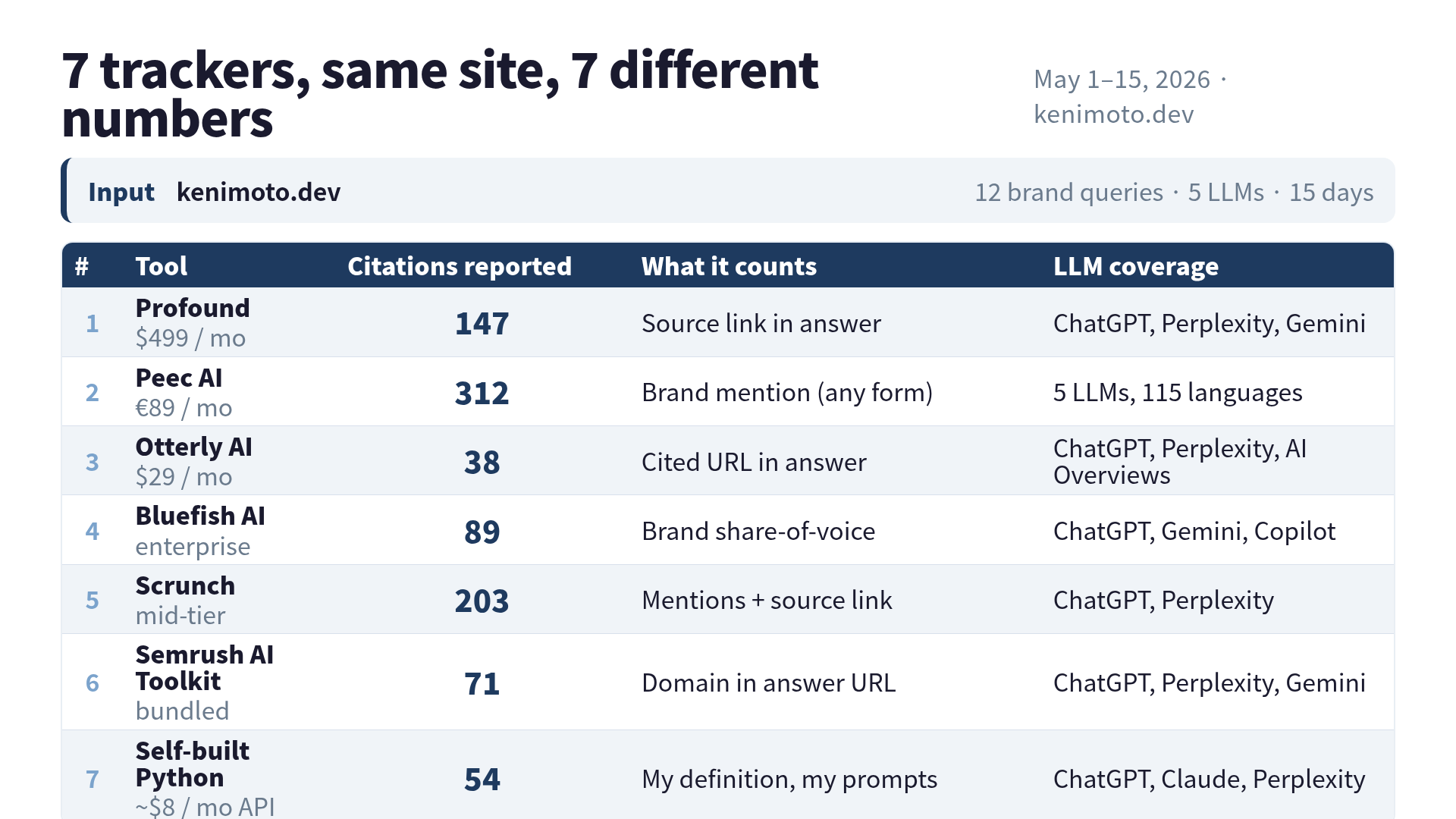
O menor número foi 38. O maior, 312. Não é arredondamento. É 8,2 vezes de diferença para o mesmo input. Spoiler: a que eu acabei mantendo foi a mais barata, USD 29 por mês (cerca de R$ 145). Não porque era a mais certa. Porque era a única que era honesta sobre o que estava contando.
O setup
Eu rodo o kenimoto.dev em quatro idiomas e há meses tento entender se a busca por IA de fato enxerga o meu site. Os trials gratuitos das principais ferramentas de citation tracking iam empilhando no meu email. Em algum momento, decidi rodar todos ao mesmo tempo, com o mesmo input, e comparar.
As regras que me impus:
- Um site só:
kenimoto.dev(incluindo/ja/,/pt/,/es/) - Uma janela só: 1 a 15 de maio de 2026, 15 dias
- 12 brand queries, escritas uma vez e compartilhadas com todas as ferramentas. Coisas como “melhor setup de subagentes do Claude Code”, “como medir citações de LLM”, “stack de voice AI abaixo de 300ms de latência”
- Cinco LLMs de interesse: ChatGPT, Claude, Gemini, Perplexity, Copilot. Nem toda ferramenta cobre todos, e isso importa mais do que parece
Escolhi sete ferramentas. Seis comerciais e uma que eu mesmo escrevi numa tarde. Sete porque o título do post escreve sozinho, mas também porque sete é mais ou menos quantas ferramentas uma equipe de LLMO normal consideraria antes de comprar uma.
As sete:
- Profound (USD 499/mês plano lite, foco enterprise, SOC 2 / HIPAA)
- Peec AI (EUR 89/mês, Berlim, foco multilíngue, 115+ idiomas)
- Otterly AI (USD 29/mês, a mais barata, integração com Semrush)
- Bluefish AI (cotação enterprise, foco Fortune 500)
- Scrunch (faixa intermediária)
- Semrush AI Toolkit (vem dentro da suíte de SEO)
- Meu script Python (usa as APIs da OpenAI, Anthropic e Perplexity, cerca de USD 8/mês em chamadas)
Cadastrei o kenimoto.dev em cada uma, configurei as mesmas 12 queries onde a interface deixava, esperei 15 dias e exportei o número de citações.
Os números
Eis o que cada ferramenta me disse sobre o mesmo site, na mesma janela:
| Ferramenta | Citações | Vs. menor |
|---|---|---|
| Otterly AI | 38 | 1,0x |
| Script Python | 54 | 1,4x |
| Semrush AI Toolkit | 71 | 1,9x |
| Bluefish AI | 89 | 2,3x |
| Profound | 147 | 3,9x |
| Scrunch | 203 | 5,3x |
| Peec AI | 312 | 8,2x |
Entre o menor e o maior, 8,2 vezes. Não é “arredondamento diferente”. Não é “fora do intervalo de confiança”. É oito vezes.
Eu fiquei olhando o export achando que tinha lido errado. Aí fui ler a doc de cada ferramenta sobre o que ela chamava de “citação”. A resposta estava ali.
Por que os sete números divergem
Depois de ler as docs lado a lado, parou de ser um mistério e virou um problema de definição. A divergência mora em quatro eixos.
1. O que conta como “citação”
Esse é o grande. Cada ferramenta está contando uma coisa diferente e chamando todas pelo mesmo nome.
- Profound só conta quando a resposta da LLM inclui um link clicável de fonte apontando para o seu domínio. Rigoroso, útil para atribuição. Perde toda menção em que a LLM só fala do nome da marca sem linkar.
- Peec AI conta qualquer menção do nome da marca no texto da resposta, com ou sem link. Se o Perplexity diz “o Ken Imoto escreveu um guia útil sobre voice AI”, isso é uma citação, mesmo sem link. Por isso o número deles é o maior.
- Otterly AI conta URLs citados na resposta, parecido com Profound, mas deduplica por query e por dia, o que afunda o número.
- Bluefish AI está rodando um cálculo de share-of-voice contra concorrentes. A “citação” deles está mais perto de um ranking do que de uma contagem.
- Scrunch conta tanto menções quanto links de fonte, sem deduplicação. Por isso fica no meio-alto.
- Semrush só conta quando o seu domínio aparece no campo de URL da resposta estruturada. Interpretação mais rígida.
- Meu script Python conta o que eu decidir contar. Hoje: “a string da marca aparece no texto da resposta, deduplicado por query, média de três amostras”.
Pega quaisquer duas dessas definições. Elas não vão bater. Não é falha de fornecedor. É a área inteira ainda não ter uma definição compartilhada.
2. Quais LLMs cada uma amostra
Nenhuma ferramenta cobre os cinco LLMs que me interessam.
| Ferramenta | ChatGPT | Claude | Gemini | Perplexity | Copilot |
|---|---|---|---|---|---|
| Profound | sim | não | sim | sim | não |
| Peec AI | sim | sim | sim | sim | sim |
| Otterly | sim | não | sim | sim | não |
| Bluefish | sim | não | sim | não | sim |
| Scrunch | sim | não | não | sim | não |
| Semrush | sim | não | sim | sim | não |
| Script Python | sim | sim | não | sim | não |
A Peec AI amostra todos os cinco. Só isso já dá mais área de superfície, e é parte do motivo de ela aparecer no topo. A Scrunch só vê ChatGPT e Perplexity, então um número alto vindo de duas superfícies só é uma informação diferente: significa que naquelas duas a presença é forte.
Se você só liga para ChatGPT, a escolha do rastreador importa menos. Se você liga para Gemini ou Claude, metade da lista cai fora.
3. Frequência e regras de deduplicação
A maioria roda cada query diariamente. Algumas, semanalmente. A Otterly roda diário mas deduplica numa janela de 24h: cinco menções em um dia contam uma. A Peec AI roda diário e conta cada menção separadamente. Em 15 dias e 12 queries, isso acumula rápido.
4. Se amostram nos seus idiomas
Publico em quatro idiomas. A maioria amostra só em inglês por padrão e ignora o resto a menos que você configure conjuntos de idioma. A Peec AI deu o número multilíngue mais útil porque consulta em 115 idiomas por padrão. As outras basicamente ignoraram meu tráfego em PT e ES, e por isso subestimam o que de fato está acontecendo no Brasil e em LatAm.
No Brasil ainda é difícil achar rastreador que cubra Perplexity em português direito. Se você publica conteúdo em PT-BR e a única coisa que olha esse idioma é a Peec AI, isso já justifica o teste antes de comprar qualquer outra.
A conclusão chata: escolha a definição, depois escolha a ferramenta
Depois de duas semanas encarando esses números, eu acho que “qual rastreador é o mais certo” é a pergunta errada. Não existe verdade absoluta para citação por IA. Toda LLM é uma caixa preta que retorna respostas levemente diferentes para a mesma prompt dependendo de horário, região e datacenter. Não tem Google Search Console para isso.
A pergunta certa é: qual definição de “citação” corresponde ao resultado de negócio que eu de fato quero?
- Quer tráfego de atribuição (alguém clica no link)? Profound ou Otterly. Só contam citação com link. Os números são pequenos, mas batem com eventos de referrer que você pode validar no GA4.
- Quer presença de marca (a LLM está falando de você, com ou sem link)? Peec AI. O número parece generoso, mas é o proxy mais próximo de “o ChatGPT está dizendo meu nome em voz alta na resposta”.
- Quer posicionamento competitivo? Bluefish ou Scrunch tratam concorrentes nativamente.
- Quer a verdade dentro do orçamento? Escreva o seu script. O meu são 200 linhas de Python em volta das APIs da OpenAI, Anthropic e Perplexity, e custa cerca de USD 8 por mês. Ainda me dá o texto cru da resposta, coisa que as comerciais escondem por trás de gráficos.
Enquanto a área não combinar uma definição comum, cada fornecedor vai continuar contando diferente e chamando pela mesma palavra. Uma taxonomia como a que o llmoframework.com propõe ajudaria de verdade aqui: um padrão para o que “citação”, “menção” e “link de fonte” significam entre ferramentas, para que os números fiquem comparáveis.
O que eu de fato uso
Resposta honesta: rodo duas ferramentas, não sete.
Mantive a Otterly porque é barata e a definição rigorosa dela bate com o que eu consigo verificar no GA4. Se a Otterly diz que houve citação e o GA4 mostra um clique de referrer, eu acredito nos dois. Mantive também meu script Python, porque me dá o texto cru e eu posso mudar a definição amanhã se quiser.
Cancelei o resto. Não porque são ruins. Porque pagar USD 499 por mês para receber um número que eu não consigo reconciliar com outro número de uma ferramenta de USD 29 estava me deixando mais burro, não mais informado.
Se você está prestes a gastar dinheiro num rastreador de citação por IA, faça isso primeiro: escreva numa frase só o que “citação” significa para você. Depois pergunte para cada fornecedor se a definição deles bate com a sua. A maioria não responde direito. Essa é a resposta.
O frame completo de medição (KPIs de citação, GA4 referrals, análise de log de crawler como peças de um sistema) está em LLMO Quickstart: Otimização para Busca por IA para Engenheiros. O capítulo de medição é o que define “citação” antes de comprar qualquer rastreador.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?