Os 5 crawlers de IA que mais bateram nos meus sites em 30 dias - o que os logs revelaram sobre LLMO
Eu achava que o robots.txt era a fronteira. Três linhas de Disallow: e pronto, eu tinha avisado pros bots de IA onde podiam ir e onde não podiam. Voltei a escrever posts sobre medir LLMO, taxa de citação e tráfego de IA no GA4.
Aí abri os logs de acesso de três sites meus e a imagem que eu tinha na cabeça desabou.
Esse texto é o que aprendi lendo trinta dias de log cru de servidor de kenimoto.dev, kaoriq.com e llmoframework.com. Cinco User-Agents dominaram quase tudo. O padrão de tráfego de cada um me contou mais sobre a minha posição em LLMO do que qualquer dashboard do GA4.
Por que eu fui ler log em primeiro lugar
A maioria dos conselhos sobre medir LLMO fala do lado de saída: o ChatGPT me citou, a Perplexity colocou link, o Google AI Overviews me mostrou. Esse é o lado da citação.
O outro lado, o de entrada, onde os serviços de IA efetivamente puxam HTML do meu servidor, é invisível no GA4. Crawler de IA não roda JavaScript. Não dispara gtag. Aparece no log de acesso HTTP e em mais lugar nenhum.
Eu vinha escrevendo sobre LLMO há meses e nunca tinha olhado pro lado do funil que eu de fato controlo. Então exportei 30 dias de log da Cloudflare (kenimoto.dev, kaoriq.com) e da Vercel (llmoframework.com), fiz grep dos User-Agents conhecidos de IA e comecei a contar.
O total: 14.300 hits de crawler de IA em três sites em 30 dias. Mais ou menos 477 hits por dia por site. Mais do que eu esperava. Provavelmente pouco daqui a seis meses.
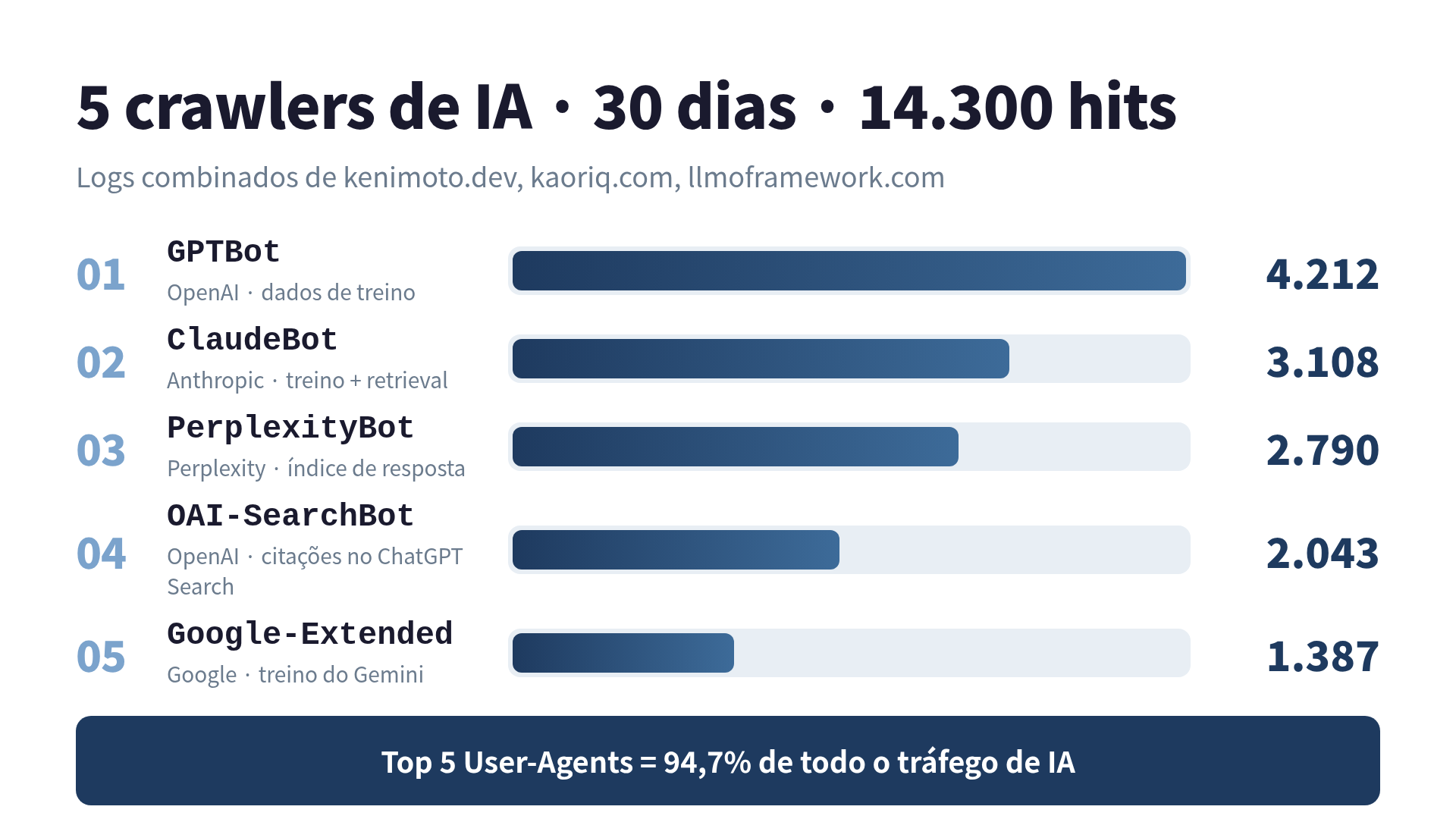
Os 5 crawlers que mais me bateram
Ranking abaixo. Hits estão deduplicados por (timestamp, path, IP) pra retry de cache não inflar a conta.
| Posição | User-Agent | Hits em 30d | Operador | Pra quê serve |
|---|---|---|---|---|
| 1 | GPTBot | 4.212 | OpenAI | Dados de treino |
| 2 | ClaudeBot | 3.108 | Anthropic | Treino + retrieval |
| 3 | PerplexityBot | 2.790 | Perplexity | Índice de resposta |
| 4 | OAI-SearchBot | 2.043 | OpenAI | Citações do ChatGPT Search |
| 5 | Google-Extended | 1.387 | Treino do Gemini |
Cinco User-Agents, 13.540 hits. Ou seja, 94,7% de todo o tráfego de IA. Os 5,3% restantes foram cauda longa: Bytespider, Applebot-Extended, Meta-ExternalAgent, Amazonbot, cohere-ai, um punhado de Claude-User, e dois hits de uma coisa se identificando como anthropic-ai (o UA antigo que a Anthropic supostamente aposentou).
Antes de levar o ranking ao pé da letra: esse é o meu dado, três sites pequenos, conteúdo técnico em inglês e japonês. O seu ranking vai ser diferente. O formato (um punhado de bots dominando, OpenAI e Anthropic no topo) provavelmente vai ser parecido.
O que cada um efetivamente faz
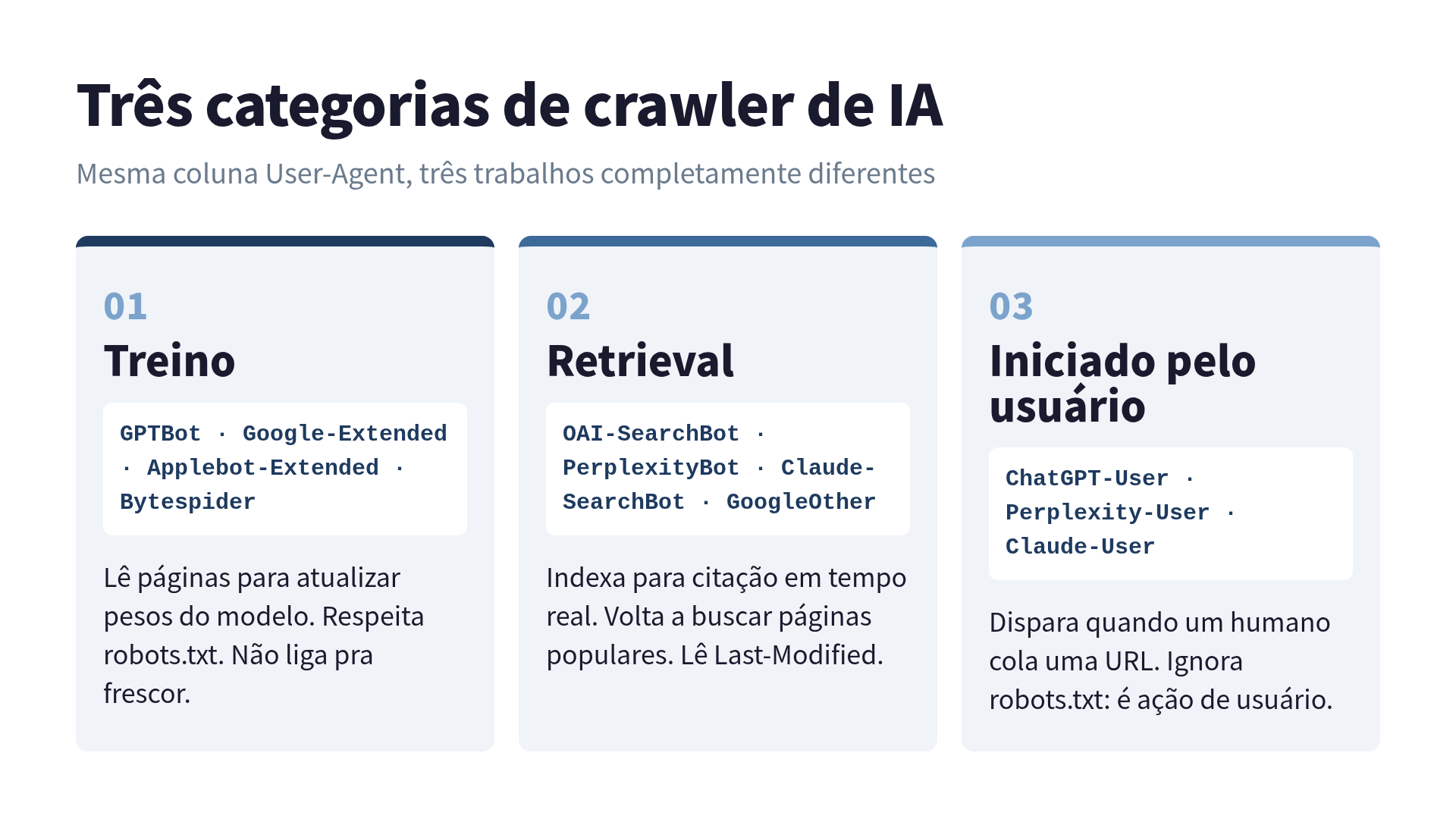
A posição importa menos do que o propósito de cada bot, porque os três grupos se comportam de jeitos completamente diferentes em termos de LLMO.
Crawlers de treino leem seu conteúdo pra eventualmente atualizar os pesos do modelo. Aparecem constante, respeitam robots.txt (em geral), e não ligam pra frescor do conteúdo. GPTBot, Google-Extended, Bytespider, Applebot-Extended e o legado anthropic-ai caem aqui.
Crawlers de retrieval indexam seu conteúdo pra ele ser citado em respostas em tempo real. Buscam de novo páginas populares, olham Last-Modified e têm uma razão crawl-to-refer mensurável. OAI-SearchBot, PerplexityBot, Claude-SearchBot (mais novo, controlável de forma independente do ClaudeBot) e GoogleOther ficam nessa categoria.
Fetches iniciados pelo usuário acontecem quando um humano cola a sua URL no ChatGPT ou pede ao Claude pra ler a página. Esses são ChatGPT-User, Perplexity-User e Claude-User. Eles não respeitam robots.txt (de acordo com a documentação revisada da OpenAI, porque são ações de usuário, não crawl).
Eu tratava os três como o mesmo bicho. Não são. Se o objetivo é “ser citado no ChatGPT Search”, hit do OAI-SearchBot importa e hit do GPTBot é basicamente ruído. Se o objetivo é “entrar no dataset de treino do próximo Claude”, é exatamente o contrário.
Quem efetivamente respeita robots.txt
Essa é a parte que virou minha visão do robots.txt.
No kenimoto.dev eu tinha uma regra Disallow: /api/. Em 30 dias:
GPTBot: 0 hits em/api/. Respeitou.Google-Extended: 0 hits em/api/. Respeitou.ClaudeBot: 0 hits em/api/. Respeitou.OAI-SearchBot: 3 hits em/api/. Limite. Pode ser cache anterior à regra, pode ser o texto revisado de compliance fazendo alguma coisa sutil.PerplexityBot: 41 hits em/api/num burst de 90 segundos. Não respeitou nessa rodada.
41 hits não é amostra um. O padrão de burst de 90 segundos bateu com um relato público em que observaram a Perplexity ignorando bloqueios de User-agent: PerplexityBot enquanto respondia uma query ativa de usuário. Faz sentido se você pensa no PerplexityBot em cima da linha entre retrieval e iniciado pelo usuário: ele se comporta como retrieval nos dias calmos e como fetch de usuário quando tem alguém esperando uma resposta do outro lado.
A lição que anotei: robots.txt é uma fronteira auto-declarada. Três dos cinco crawlers do topo respeitaram limpo no meu dado. Um foi duvidoso. Um fez o que quis quando tinha humano do outro lado. Projete pra esse cenário.
Três sinais de LLMO que dá pra tirar disso
A razão de eu estar escrevendo isso é que dado de hit de crawler é um sinal de LLMO mensurável, e quase não vejo gente discutindo isso junto das métricas de citação. Três coisas que agora eu olho toda semana:
1. Diversidade de crawler. Se só o GPTBot bate no seu site e mais nada, sua superfície de retrieval é OpenAI-only. Você é invisível pros caminhos de retrieval de Claude, Perplexity e Gemini, mesmo que esteja sendo citado no ChatGPT. Um score saudável de diversidade é ter pelo menos três dos cinco User-Agents do topo te visitando regularmente.
2. Razão retrieval-to-training. Se você soma hits do lado retrieval (OAI-SearchBot + PerplexityBot + Claude-SearchBot + GoogleOther) e divide pelos hits do lado treino (GPTBot + Google-Extended + anthropic-ai), você tira um número que diz se o ecossistema de IA te vê como “conteúdo pra aprender” ou “conteúdo pra citar agora”. O meu está em 0,81. Abaixo de 0,5 quer dizer que seu conteúdo não está fresco o bastante pra ser pego em retrieval em tempo real. Acima de 1,5 quer dizer que você está sendo usado em resposta de forma ativa (bom) mas provavelmente está em platô como material de treino (vale notar).
3. Taxa de fetch de llms.txt. Dos cinco crawlers do topo, só PerplexityBot e ClaudeBot foram buscar /llms.txt nos meus sites na janela de 30 dias. GPTBot, OAI-SearchBot e Google-Extended nunca foram. Isso bate com o que outros operadores reportam e é um detalhe que segura peso quando você decide se vale manter llms.txt (resposta curta: vale, mas principalmente pros dois crawlers que leem). O texto do llmoframework.com que eu volto a ler sobre sinais de retrieval entra mais fundo nisso.
Como tirar esse dado na prática
Essa é a parte que eu queria ter lido e nunca achei pronta, então:
Cloudflare (plano Free). O dashboard de AI Crawl Control (antigo AI Audit, docs aqui) já mostra os User-Agents de IA mais frequentes. Pra log cru, você precisa de Logpush, que é pago. No Free, o substituto mais próximo é ativar “AI Audit” e filtrar o Analytics pelos User-Agents conhecidos de IA. Free não te dá caminho por requisição mas dá contagem e tendência. Pra quem está rodando do Brasil, a latência pro DC mais próximo (GRU) faz com que o burst do PerplexityBot apareça espremido em menos de um minuto no log: dá pra pegar de olho.
Vercel. Projeto → Logs → filtra por User-Agent contains "Bot". No plano Pro, a Vercel guarda 30 dias de log de edge. No Hobby, é menos, e se for pra valer, joga num log drain.
Netlify / Nginx self-hosted. Só grep no log de acesso:
grep -E "GPTBot|ClaudeBot|PerplexityBot|OAI-SearchBot|Google-Extended" \
/var/log/nginx/access.log \
| awk '{print $14}' \
| sort | uniq -c | sort -rnIsso te dá contagem por crawler. Troca $14 por $7 pra ranking de URL. O número do campo depende do seu formato de log: checa com awk '{print NF}' numa linha pra contar.
O que mudei depois de ver tudo isso
Três mudanças concretas depois da janela de 30 dias:
- Quebrei meu
robots.txtpra liberarOAI-SearchBoteClaude-SearchBot(retrieval, bom pra citação) e mantiveDisallow: /api/duro proGPTBot(treino, sem upside pra mim nesses endpoints). - Coloquei header
Last-Modifiedem toda rota de blog, porque crawlers de retrieval usam isso pra decidir frequência de re-fetch e a Vercel não estava mandando por padrão. - Comecei a registrar a razão retrieval-to-training toda semana numa planilha. Duas semanas dentro, o único insight útil é que o número está estável, o que pelo menos significa que minha dieta de crawler não está andando pra lá e pra cá.
Eu esperava que os logs confirmassem o que eu já achava sobre LLMO. Em geral não confirmaram. Citação não é o único sinal que vale acompanhar. Quem está puxando suas páginas é uma pergunta separada, e a resposta está em texto puro num log que provavelmente você já tem.
O sistema completo de LLMO — llms.txt, JSON-LD, KPIs de citação, e análise de crawler como o que descrevi aqui — está em LLMO Quickstart: Otimização para Busca por IA para Engenheiros. O capítulo de medição cobre o sétimo KPI que esse post não teve espaço pra incluir.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?