Eu rodava geração de conteúdo e checagem de pedidos no mesmo cron. Uma API lenta travou tudo por 5 horas
Eu tenho uma confissão de engenheiro pra fazer: por uns bons meses, a minha “infraestrutura” de operação foi um arquivo de crontab e fé.
No mesmo cron eu rodava duas coisas que não têm nada a ver uma com a outra. De um lado, a geração de conteúdo: o robô escrevia rascunho de artigo, montava relatório de métricas, agregava número de tráfego. Coisa de horário fixo, sem pressa, ninguém está esperando do outro lado da tela. Do outro lado, a checagem de pedidos: olhar se entrou venda nova, disparar notificação, confirmar pagamento. Coisa que precisa acontecer agora, porque tem um usuário real esperando.
Duas naturezas opostas, um cron só. Eu sabia que era feio. Eu achava que feio não ia me machucar. Eu estava errado, e o preço veio numa terça à tarde.
O dia em que o gerador de relatório derrubou as vendas
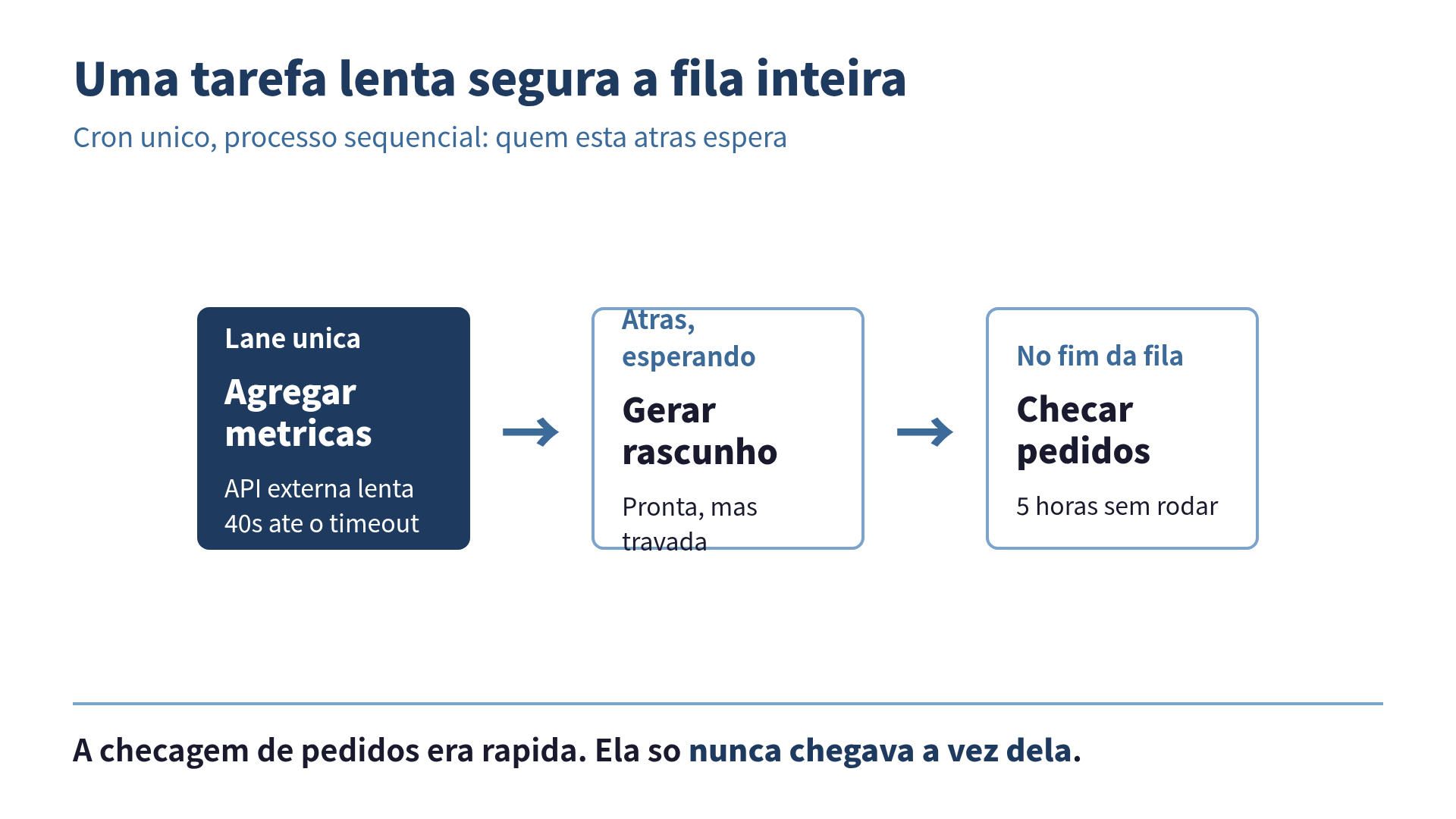
Era mais ou menos assim a ordem das tarefas no meu cron: primeiro a agregação de métricas (que chama uma API externa de analytics), depois a geração do rascunho, e só no fim a checagem de pedidos. Tudo sequencial, no mesmo processo, porque “é mais simples assim”: frase que todo engenheiro fala dez minutos antes de descobrir que não era.
Naquela terça, a API de analytics resolveu ter um dia ruim. Não caiu. Cair teria sido melhor, porque eu trato erro. Ela ficou lenta. Cada chamada que normalmente voltava em 300 milissegundos passou a demorar 40, 50 segundos antes de dar timeout. E o meu código, todo educado, ficou ali esperando, com a paciência de quem não tem pressa nenhuma.
O problema é que atrás dessa tarefa lenta estava a fila inteira. A checagem de pedidos estava na lane de trás, esperando o relatório terminar. E o relatório não terminava.
Resultado: durante cinco horas, nenhum pedido foi processado. As vendas continuaram entrando. Os usuários não sabiam de nada, a loja estava no ar, o botão de comprar funcionava lindamente. O que não funcionava era o meu processo que confirmava o pedido e disparava a notificação. Os pedidos ficaram empilhados, sem confirmação, porque o robô que devia olhar pra eles estava bloqueado atrás de um gráfico de tráfego que ninguém ia ler naquele dia.
Cinco horas. Eu só percebi porque um cliente mandou mensagem perguntando se o pedido tinha dado certo. Não foi o meu monitoramento. Foi um humano educado no chat.
A conta da paralisação (e por que ela dói no indie BR)
Vou colocar número, porque “travou por um tempão” não impressiona ninguém e é exatamente o tipo de coisa vaga que a gente conta no happy hour pra parecer que sofreu.
Eu rodo um D2C pequeno, dessas operações indie de uma pessoa só que existem aos montes no Brasil. Num dia comum, entravam uns 6 a 8 pedidos por hora no horário de pico, ticket médio na faixa de R$ 90. Não é Magalu. Mas cada pedido que entra sem confirmação na hora vira atrito: o cliente fica inseguro, alguns desistem, outros mandam mensagem (e aí o “suporte” sou eu, no celular, no meio do almoço).
Conta de padaria: 5 horas vezes ~7 pedidos por hora dá uns 35 pedidos sem confirmação imediata. Nem todos viram cancelamento, porque a maioria eu recuperei correndo atrás depois. Mas a parcela que esfriou, somada ao tempo que eu gastei apagando incêndio em vez de trabalhar, me custou algo na ordem de R$ 600 a R$ 800 naquele dia. Por hora parada, uns R$ 130 a R$ 160 evaporando em pedido que não foi processado na hora certa.
Para uma operação grande isso é ruído. Para um indie, é o lucro da semana indo embora porque eu quis economizar um processo no crontab.
Não era um problema de velocidade. Era de vizinhança
A minha primeira reação foi a errada: “preciso deixar a API de analytics mais rápida”. Errado. A API não era minha, e ela vai ficar lenta de novo, num outro dia, porque APIs externas fazem isso. A pergunta certa não é “como deixo essa tarefa rápida”, e sim “por que uma tarefa lenta consegue derrubar uma tarefa que não tem nada a ver com ela”.
Esse é o velho problema do vizinho barulhento. Você mora num prédio onde o cara do apartamento de cima resolve tocar bateria às três da manhã, e de repente o seu sono, que não tem relação nenhuma com a bateria dele, vira refém. No meu cron, a geração de relatório era o baterista, e a checagem de pedidos era eu tentando dormir.
Tem nome técnico pra isso também, e é o que os times de sistemas distribuídos chamam de bloqueio de cabeça de fila: quando o primeiro item de uma fila trava, tudo que está atrás trava junto, mesmo que os itens de trás estivessem prontos pra rodar em um milissegundo. A minha checagem de pedidos era rápida. Ela só nunca chegava a vez dela.
E tem um detalhe que machuca o engenheiro mais do que a perda de venda: quando tudo roda no mesmo processo, o log vira uma papa. Eu tinha uma única sequência de mensagens onde a geração de conteúdo, a agregação e a checagem de pedidos se misturavam. Quando fui investigar, não dava pra saber de cara quem segurou quem. A rastreabilidade some justamente na hora que você mais precisa dela.
E o retry, o tão amado retry, só piorava. No meu cron único, quando a tarefa de analytics dava timeout e tentava de novo, essa nova tentativa atrasava todas as tarefas seguintes mais um pouco. O retry de uma tarefa virava castigo coletivo. A localidade do retry tinha quebrado: a tentativa de consertar uma coisa estragava as outras.
O conserto não foi otimizar. Foi separar
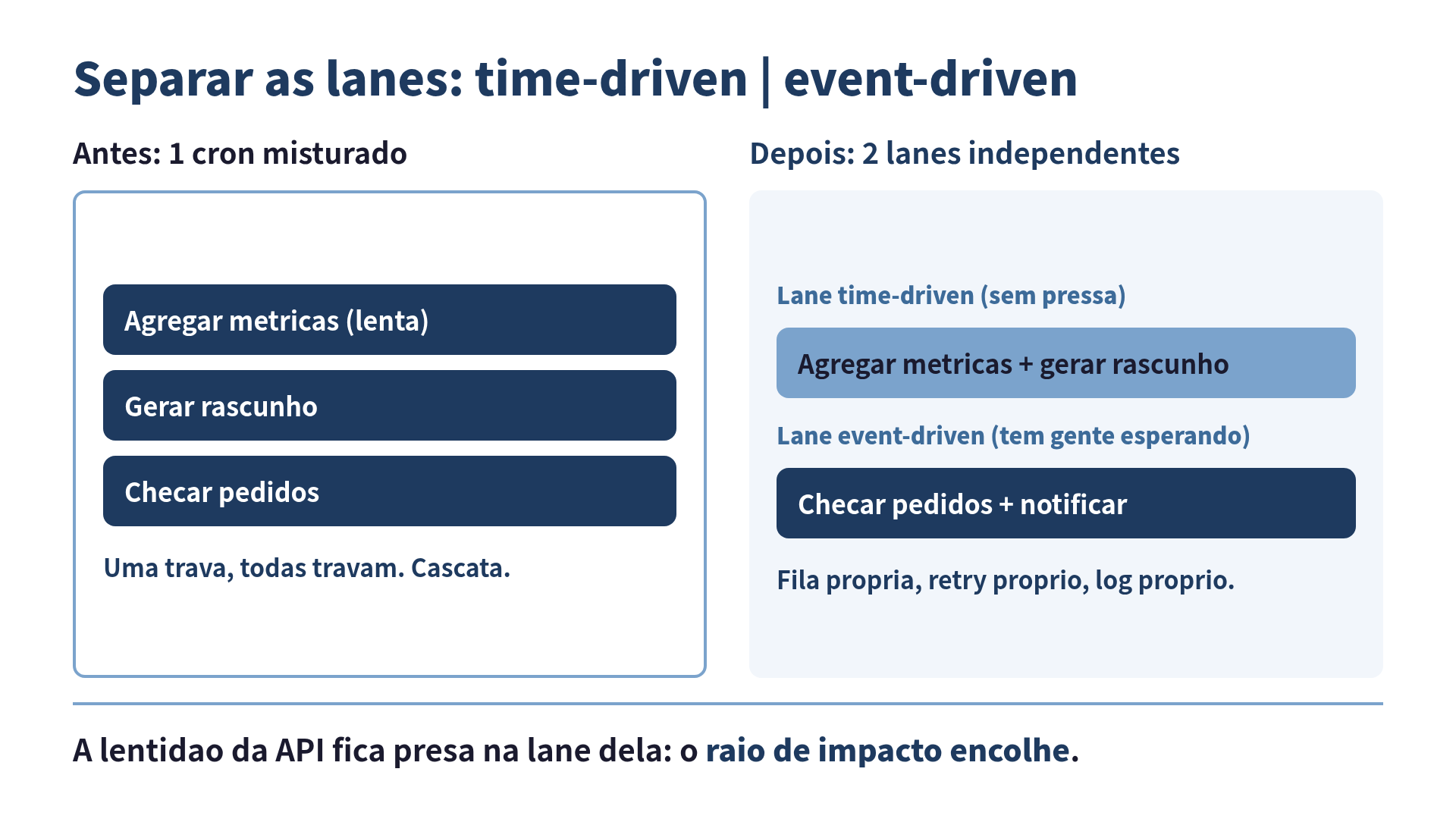
A solução não foi nenhum truque de performance. Foi parar de misturar duas coisas que nunca deveriam ter morado juntas. Eu separei em duas lanes independentes.
A lane time-driven (orientada a tempo) ficou com tudo que roda por horário e não tem ninguém esperando: geração de rascunho, agregação de métricas, relatório. Pode ser lenta, pode tomar timeout, pode tentar de novo à vontade. Ninguém atrás dela sofre, porque atrás dela não tem ninguém que importe.
A lane event-driven (orientada a evento) ficou com tudo que reage a um acontecimento real e tem um usuário do outro lado: pedido novo entrou, processa; pagamento confirmou, notifica. Essa lane tem o próprio processo, a própria fila, o próprio retry. Quando a API de analytics tem outro dia ruim, e ela vai ter, a lane de pedidos nem fica sabendo. Ela mora em outro apartamento.
Em arquitetura isso tem nome de gente grande: padrão de antepara, o bulkhead. A ideia vem do navio, daquelas paredes que dividem o casco em compartimentos estanques: se um compartimento enche de água, o navio não afunda, porque a água não passa pro compartimento do lado. A separação de lanes é a mesma coisa: você não evita que uma parte falhe, você só garante que a falha de uma parte não inunde a outra. O Titanic, aliás, tinha anteparas. O problema dele foi que a água passava por cima delas. Detalhe de implementação importa.
O ponto que demorei pra entender: separar lanes não deixa nada mais rápido. A API de analytics continua ficando lenta no mesmo dia. A diferença é que agora a lentidão dela fica presa na lane dela. O raio de impacto encolheu de “tudo” para “uma coisa que ninguém estava esperando mesmo”.
O que mudou nos números
Depois da separação, três coisas:
A taxa de erro mensal das tarefas de pedido caiu de um patamar que me dava uns dois ou três sustos por mês para essencialmente zero relacionado a bloqueio de lane. Os erros que sobraram são erros de verdade, tipo pagamento recusado ou dado inválido, não tarefa boa morrendo de fome atrás de uma tarefa lenta.
O esforço de retry parou de ser coletivo. Quando a lane time-driven tenta de novo, ela tenta sozinha, no canto dela. Eu deixei de ter aquele efeito dominó em que uma tentativa empurrava o atraso pra frente. O retry virou local de novo, que é onde ele sempre deveria ter morado.
E o log, finalmente, faz sentido. Cada lane tem a própria trilha. Quando algo dá errado, eu olho a trilha certa e sei em trinta segundos quem travou. Antes eu gastava meia hora separando no olho o que era relatório e o que era pedido na mesma papa de mensagens.
Todos esses ganhos vieram da mesma decisão boba: parar de pedir pra duas tarefas opostas dividirem o mesmo quarto. Zero linha de código esperto envolvida.
O que eu levo dessa terça
Se você roda uma operação indie, de uma pessoa só, com um cron e fé igual eu rodava, a pergunta que vale a pena fazer hoje é simples: no seu agendamento, tem alguma tarefa “sem pressa” rodando na frente de uma tarefa “tem gente esperando”? Se tem, você tem um baterista morando em cima do seu quarto. É só questão de qual madrugada ele vai resolver tocar.
Separar não é sofisticado. Não tem fila distribuída chique, não tem nome bonito no currículo. É só reconhecer que tempo e evento são duas naturezas diferentes e merecem moradas diferentes. Eu aprendi isso da pior forma, com um cliente educado me avisando no chat que a casa estava pegando fogo enquanto eu olhava um gráfico de tráfego.
Hoje as duas lanes vivem separadas, e quando a próxima API externa tiver o dia ruim dela, e vai ter, eu vou estar almoçando em paz. Essa história, junto com o resto do que aprendi quebrando a minha própria operação, virou parte do que eu venho juntando num guia de engenharia de harness. Mas isso é papo pra outro dia.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?