Coloquei 7 agentes de IA no cron diário. 2 ficaram em silêncio por 18 dias. Tracing não pegou. Um contrato de exit code pegou.
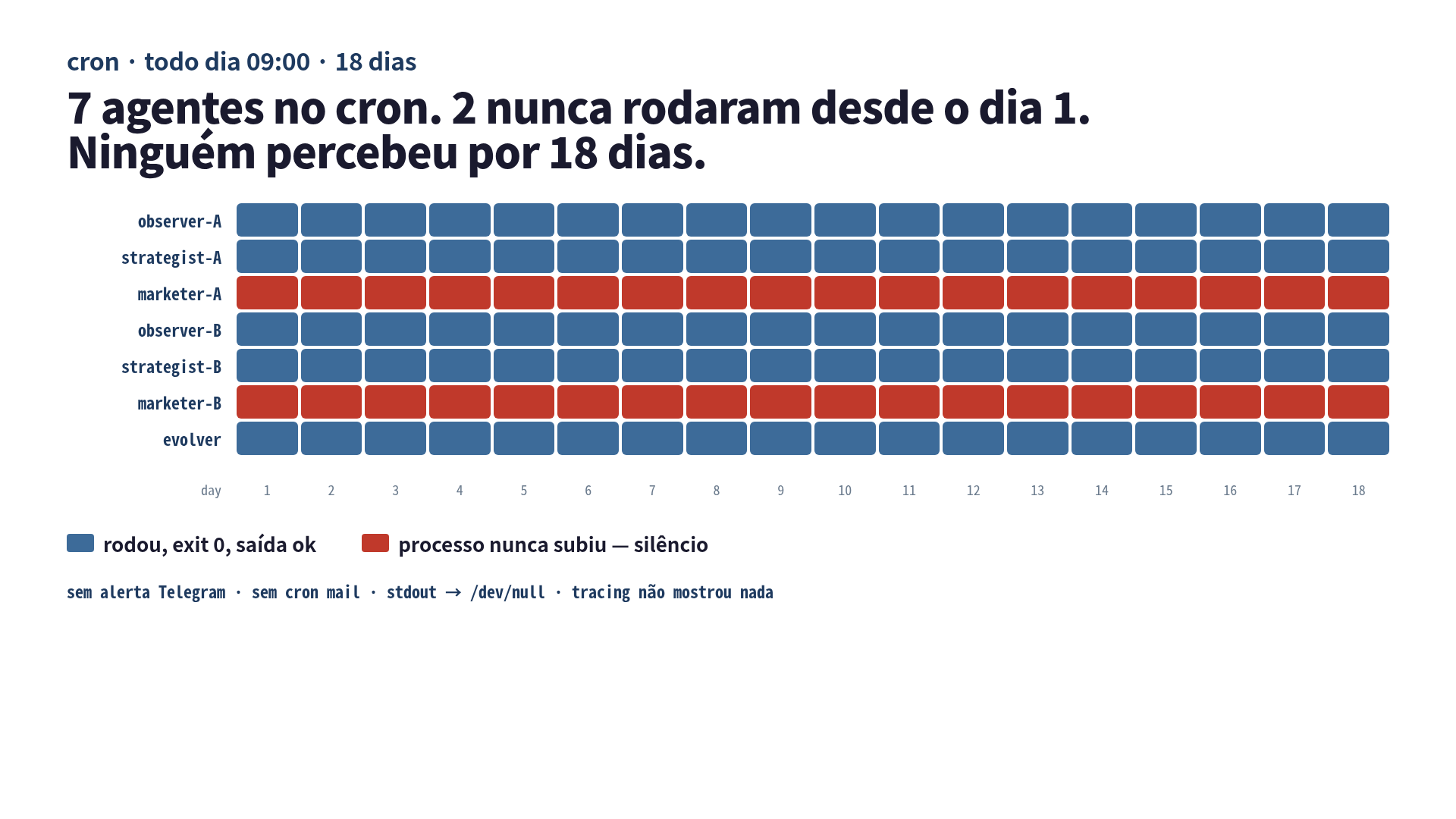
Eu tinha 7 agentes de IA no cron. Dois deles pararam de rodar no dia 1. Eu percebi no dia 18.
Essa frase já é o artigo inteiro, mas também é o tipo de frase contra a qual eu teria argumentado se alguém dissesse num podcast. “Não dá pra não perceber 18 dias. Você tem tracing. Você tem dashboard. Você tem um canal de Telegram que dispara quando qualquer coisa se mexe.” Tinha tudo isso. Os dois agentes mortos passaram por baixo de todas essas camadas, porque cada uma delas foi feita para olhar para processos que estavam rodando. Os meus dois não estavam.
Esse é o log dos 18 dias: quais eram os 7 agentes, como 2 quebraram em silêncio no dia 1, por que o tracing não conseguia pegar, e o pequeno contrato de exit code que hoje gruda em qualquer agente CLI que eu coloco no cron.
Os 7 agentes e o setup que parecia estar bem
Eu rodo dois domínios de conteúdo e um harness self-evolving na mesma máquina. Cada domínio tem 3 agentes no cron das 09
— observer, strategist, marketer — mais um evolver compartilhado que roda aos sábados. São 7 processos. As linhas do cron eram mais ou menos assim:0 9 * * * /home/me/repos/harness-ops/scripts/marketer-A.sh >/dev/null 2>&1
0 9 * * * /home/me/repos/harness-ops/scripts/marketer-B.sh >/dev/null 2>&1Cada shell script embrulha claude -p "..." com um prompt, captura a saída, escreve um log diário, e termina. Quem decide publicar, publica de fato no final. Tinha um webhook de Telegram disparando dentro do script no sucesso e no caminho do set -e. Esse setup tinha uns 2 meses em produção antes da falha silenciosa.
O que escapou no setup tinha 3 linhas abaixo do heredoc. Os scripts dos dois marketers chamavam um helper Python que morava em outro repositório. Eu tinha feito cd no repo vizinho na hora do teste, validado o helper na mão, e comitado. Depois disso eu arrumei o repo vizinho, renomeei o módulo, e a linha de import dentro do script do marketer apontava pra um arquivo que não existia mais.
Daqui dá pra adivinhar o resto. python3 helper.py ... sai com exit 1 na hora por ModuleNotFoundError. A primeira linha do shell era set -euo pipefail. O script morre nas 10 primeiras linhas. O Telegram só é chamado lá embaixo, depois do Python. O script nunca chega lá. >/dev/null 2>&1 engole o stderr. O cron sem MAILTO=. Todo dia de manhã, 2 agentes morrem em silêncio. Os outros 5 publicam normal. O sistema todo parece saudável.
O que o tracing estava olhando, e o que não estava
Quero ser preciso aqui, porque no dia 18 eu passei algumas horas tentando me convencer de que “se o tracing fosse melhor, teria pegado.” Não teria.
Eu tinha spans OTEL saindo de cada invocação de claude -p. Iam para um collector self-hosted e de lá pra um dashboard pequeno. O dashboard mostrava: tokens por tarefa, latência de tool-call, taxa de retry, total diário de execuções. Na manhã do dia 18, o dashboard estava reto em 5 execuções/dia há 18 dias seguidos. A linha tinha que estar em 7.
O tracing instrumenta processos que executam. Mostra chamada lenta. Mostra chamada que falhou. Mostra retry em loop. Não mostra processo que nunca subiu. Os 2 marketers mortos não emitiam span nenhum, porque o emissor de span vivia exatamente dentro do helper Python que estava falhando no import. Do ponto de vista do dashboard, esses dois agentes simplesmente não existiam naquele dia. Nem no seguinte. Nem no outro.
Eu estava olhando pra pergunta errada. “Meus agentes estão saudáveis?” é uma pergunta que o tracing responde. “Os 7 agentes agendados rodaram de fato hoje?” é uma pergunta que o tracing não consegue responder, porque os agentes que não rodaram são justamente os que não mandam sinal nenhum.
Se você já leu o modelo de dead man’s switch do healthchecks.io, é exatamente o cenário que eles descrevem na doc: “Um job de processamento de dados pode parar sem disparar nenhum alarme nos sistemas de monitoramento tradicionais. Essas falhas silenciosas podem persistir por dias ou semanas até alguém perceber dados faltando ou resultados corrompidos.” Eu tinha lido essa página antes. Só não tinha aplicado ao meu próprio cron, porque achava que o Telegram me cobria. Telegram só dispara dos caminhos que o script efetivamente alcança.

O contrato de exit code que parafusei depois
A correção não envolveu mais observability. Envolveu confiar menos no agente para se reportar, e mais no wrapper do cron para reportar no lugar dele. Coloquei um contrato pequeno em cada agente agendado:
- Definir exit codes que significam algo. Não só
0 = bom, qualquer outra coisa = ruim. Peguei emprestado do sysexits.h:0= “rodou e terminou o trabalho”,64= “erro de config ou ambiente” (o caso doModuleNotFoundError),65= “rodou mas não produziu output usável”,78= “skip intencional” (o marketer decidiu que hoje não tem nada pra publicar). - O wrapper do cron é o dono do reporte. O job do script do agente é sair com o código certo. O job do wrapper é pegar esse código e empurrar pra algum lugar durável, independente do agente ter dado certo ou não.
- Heartbeat dispara no sucesso. Não na falha. Silêncio precisa virar alarme.
O wrapper do cron ficou mais ou menos assim:
#!/usr/bin/env bash
# scripts/cron-wrap.sh <agent-name>
set -uo pipefail
AGENT="$1"
SCRIPT="$HOME/repos/harness-ops/scripts/${AGENT}.sh"
HC_URL="https://hc-ping.com/<uuid-${AGENT}>"
START=$(date -Iseconds)
bash "$SCRIPT"
RC=$?
END=$(date -Iseconds)
# loga toda execução, deu certo ou não
echo "${START} ${AGENT} rc=${RC} end=${END}" >> "$HOME/logs/cron-runs.log"
# ping com o exit code embutido na URL
# se faltar ping por 24h → healthchecks.io me chama
curl -fsS --retry 3 "${HC_URL}/${RC}" >/dev/null || true
# escala não-zero na hora (mas o cron em si nunca falha)
if [[ "$RC" -ne 0 && "$RC" -ne 78 ]]; then
"$HOME/bin/tg-notify.sh" "agent=${AGENT} rc=${RC} ver ~/logs/cron-runs.log"
fi
exit 0Três coisas que me custaram algumas noites de ajuste.
Primeiro, set -uo pipefail no lugar de set -euo pipefail. Eu não quero que o wrapper morra quando o agente morre, porque se o wrapper morre antes do ping, o healthchecks.io vai me chamar daqui a 24h — tarde demais — e a linha do log nem é escrita. O wrapper tem que continuar rodando e capturar o código por conta própria.
Segundo, a URL do ping tem o exit code no caminho. O healthchecks.io aceita e mostra no dashboard como o último código reportado. Consigo bater o olho na lista e ver “agente rodou, saiu com 64” sem abrir log nenhum. O Cronitor faz quase a mesma coisa com um formato de URL ligeiramente diferente; escolha o que combina com seu setup.
Terceiro, 78 é tratado como skip deliberado, não falha. O caminho “hoje não tem nada pra publicar” do marketer retorna 78. Sem isso, o canal de escalonamento dispara em dia legitimamente quieto, eu aprendo a ignorar o canal, e o monitoramento morre na prática.
Conta de R$: 18 dias de Marketer parado
Eu uso Claude Code Max, ~USD 200/mês. Na cotação de hoje (~R$ 5,60) dá uns R$ 1.120/mês. Os 2 marketers eram responsáveis por mais ou menos um terço da minha publicação automatizada. Por 18 dias eles ficaram parados:
- assinatura do mês inteiro continuou rolando: ~R$ 1.120
- contribuição relativa dos 2 marketers parados: ~1/3
- “tempo de assinatura pago sem retorno”: ~R$ 670 nesses 18 dias
- mais ~36 artigos que deveriam ter saído e não saíram (18 dias × 2 marketers), com o re-trabalho que vem depois para reconstruir contexto e republicar nas datas certas
Não dá pra somar nas duas pontas — o trabalho não rodado também não consumiu token — mas o ponto é: assinatura cobrada / output entregue / observabilidade verde. Os três sinais que eu normalmente uso pra decidir se “está tudo bem” mentiram juntos por 18 dias. A conta que dói não é a do Anthropic, é o tempo até descobrir.
O que pegou no dia que eu liguei
Eu coloquei isso em produção exatamente no dia 18 dos marketers silenciosos. Em 10 minutos, marketer-A e marketer-B apareceram no dashboard do healthchecks.io com último código reportado = 64 — erro de config, o módulo que não existia mais. Não precisei abrir o código do agente. Bateu o olho no dashboard.
Em uma hora, renomeei o import, rodei os dois na mão pra confirmar exit 0, e o cron da manhã seguinte publicou os 2 artigos que tinham sido pulados em silêncio por duas semanas e meia. O dashboard de tracing finalmente subiu pra 7 execuções/dia. A linha continua reta, só que agora reta no número certo.
No dia seguinte, um agente diferente — observer-B, que tinha ficado saudável o tempo todo da falha silenciosa — começou a sair com 65 (“sem output usável”). O dashboard pegou em 20 minutos. Esse é o tipo de coisa que o contrato existe pra fazer: o agente rodou, mas o que produziu é lixo. Você descobre no mesmo dia, não na mesma quinzena.
O que eu diria pro meu eu de 2 meses atrás
A versão minha que montou esse cron 2 meses atrás não era descuidada. Tinha alerta Telegram, dashboard de tracing, log diário. Tinha lido o capítulo de disposability do Twelve-Factor App. Até tinha pensado na diferença entre “agente falhou” e “agente não rodou”, e tinha julgado que o segundo era raro o bastante pra ignorar.
O erro foi tratar “não rodou” como caso raro. Num setup com 7 processos agendados, 3 helpers Python, 2 repos que se mexem independentes, e um script que cabe o Telegram no meio em vez de nas duas pontas, “não rodou” é o modo de falha silenciosa mais provável. Não está nem perto dos outros.
Três coisas que eu diria, na ordem de quão barato é colocar em produção:
MAILTO=é de graça. Se você defineMAILTO=seu-mail@example.comno cron, o próprio cron envia stderr de qualquer job que falha, inclusive os que morrem antes do código de alerta rodar. Sozinho isso teria pego minha falha no mesmo dia. (A página do systemd timers no ArchWiki tem um resumo bom deOnFailure=se você migrou pra timer.)- Embrulha cada agente agendado num script que é seu. Não o agente em si — um wrapper em volta dele com um único trabalho: pegar o exit code e pingar em algum lugar. O wrapper pode ser mais feio que o agente, porque ele quase nunca muda.
- O heartbeat de sucesso é o que faz o silêncio gritar. Alerta de falha tem em todo lugar, e não te conta nada sobre agente que nunca executou. Um heartbeat que dispara no sucesso, mais um dead man’s switch que chama quando o heartbeat não chega, transforma “2 agentes ficaram quietos” de uma descoberta de 18 dias em uma descoberta de 1 dia.
Tracing e observability são como você olha pros processos que estão vivos. O contrato de exit code é como você lembra que eles tinham que estar vivos pra começo de conversa. Um complementa o outro, e o padrão “set it and forget it” do cron desmorona sem o segundo. O meu desmoronou. Por 18 dias. Em silêncio. Num servidor que eu olhava todo dia de manhã.
Olhava o dashboard. O dashboard estava olhando pra pergunta errada.
Recapitulando
- 7 agentes no cron, 2 morreram no dia 1 por
ModuleNotFoundError, ninguém percebeu por 18 dias - Tracing observa o que executou, então é estruturalmente cego pra processo que nunca subiu
- A solução foi contrato de exit code (
0/64/65/78), wrapper de cron que reporta no lugar do agente, e heartbeat de sucesso com dead man’s switch - O mais barato de tudo é
MAILTO=no cron. Sozinho já teria pego a maior parte das falhas silenciosas
Se quiser ir mais fundo no ciclo de vida de hooks e nos workflows diários de Claude Code, escrevi mais sobre isso em Harness Engineering: De Usar IA a Controlar IA (capítulo de hooks/feedback-loops) e em Practical Claude Code (capítulo de workflow diário) — os dois capítulos mais próximos do que descrevi aqui.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?